 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive Balance Search Based Complementary Heterogeneous Particle Swarm Optimization Architecture
Dec 17, 2024



A series of modified cognitive-only particle swarm optimization (PSO) algorithms effectively mitigate premature convergence by constructing distinct vectors for different particles. However, the underutilization of these constructed vectors hampers convergence accuracy. In this paper, an adaptive balance search based complementary heterogeneous PSO architecture is proposed, which consists of a complementary heterogeneous PSO (CHxPSO) framework and an adaptive balance search (ABS) strategy. The CHxPSO framework mainly includes two update channels and two subswarms. Two channels exhibit nearly heterogeneous properties while sharing a common constructed vector. This ensures that one constructed vector is utilized across both heterogeneous update mechanisms. The two subswarms work within their respective channels during the evolutionary process, preventing interference between the two channels. The ABS strategy precisely controls the proportion of particles involved in the evolution in the two channels, and thereby guarantees the flexible utilization of the constructed vectors, based on the evolutionary process and the interactions with the problem's fitness landscape. Together, our architecture ensures the effective utilization of the constructed vectors by emphasizing exploration in the early evolutionary process while exploitation in the later, enhancing the performance of a series of modified cognitive-only PSOs. Extensive experimental results demonstrate the generalization performance of our architecture.
A Dual-Channel Particle Swarm Optimization Algorithm Based on Adaptive Balance Search
Jun 25, 2024The balance between exploration (Er) and exploitation (Ei) determines the generalization performance of the particle swarm optimization (PSO) algorithm on different problems. Although the insufficient balance caused by global best being located near a local minimum has been widely researched, few scholars have systematically paid attention to two behaviors about personal best position (P) and global best position (G) existing in PSO. 1) P's uncontrollable-exploitation and involuntary-exploration guidance behavior. 2) G's full-time and global guidance behavior, each of which negatively affects the balance of Er and Ei. With regards to this, we firstly discuss the two behaviors, unveiling the mechanisms by which they affect the balance, and further pinpoint three key points for better balancing Er and Ei: eliminating the coupling between P and G, empowering P with controllable-exploitation and voluntary-exploration guidance behavior, controlling G's full-time and global guidance behavior. Then, we present a dual-channel PSO algorithm based on adaptive balance search (DCPSO-ABS). This algorithm entails a dual-channel framework to mitigate the interaction of P and G, aiding in regulating the behaviors of P and G, and meanwhile an adaptive balance search strategy for empowering P with voluntary-exploration and controllable-exploitation guidance behavior as well as adaptively controlling G's full-time and global guidance behavior. Finally, three kinds of experiments on 57 benchmark functions are designed to demonstrate that our proposed algorithm has stronger generalization performance than selected state-of-the-art algorithms.
Maximum Correntropy Value Decomposition for Multi-agent Deep Reinforcemen Learning
Aug 07, 2022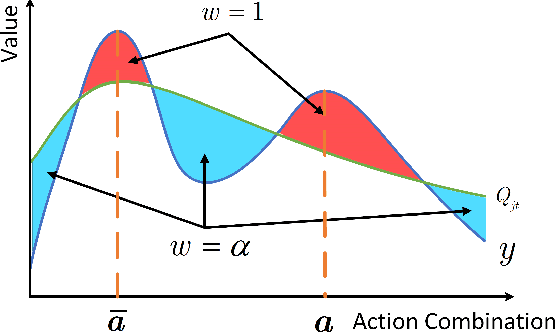
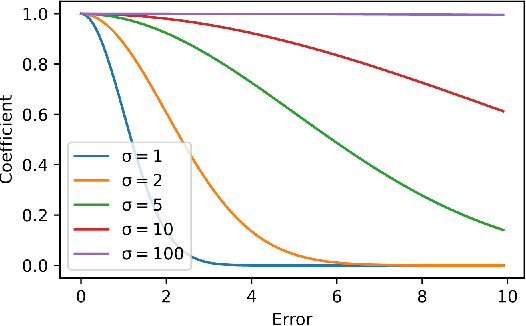
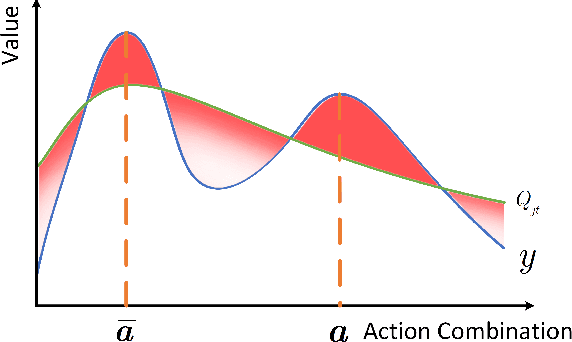
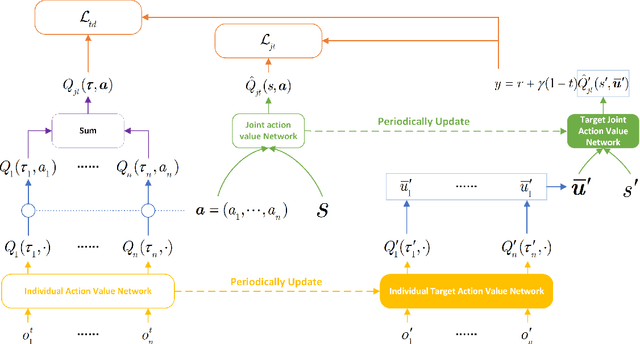
We explore value decomposition solutions for multi-agent deep reinforcement learning in the popular paradigm of centralized training with decentralized execution(CTDE). As the recognized best solution to CTDE, Weighted QMIX is cutting-edge on StarCraft Multi-agent Challenge (SMAC), with a weighting scheme implemented on QMIX to place more emphasis on the optimal joint actions. However, the fixed weight requires manual tuning according to the application scenarios, which painfully prevents Weighted QMIX from being used in broader engineering applications. In this paper, we first demonstrate the flaw of Weighted QMIX using an ordinary One-Step Matrix Game (OMG), that no matter how the weight is chosen, Weighted QMIX struggles to deal with non-monotonic value decomposition problems with a large variance of reward distributions. Then we characterize the problem of value decomposition as an Underfitting One-edged Robust Regression problem and make the first attempt to give a solution to the value decomposition problem from the perspective of information-theoretical learning. We introduce the Maximum Correntropy Criterion (MCC) as a cost function to dynamically adapt the weight to eliminate the effects of minimum in reward distributions. We simplify the implementation and propose a new algorithm called MCVD. A preliminary experiment conducted on OMG shows that MCVD could deal with non-monotonic value decomposition problems with a large tolerance of kernel bandwidth selection. Further experiments are carried out on Cooperative-Navigation and multiple SMAC scenarios, where MCVD exhibits unprecedented ease of implementation, broad applicability, and stability.