 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Assessment of Autonomous Driving: Integrating Technical Failures, Ethical Dilemmas, and Policy Frameworks
Jun 04, 2026Autonomous driving technology has the potential to reduce the large number of road traffic accidents caused by human error each year, but it also brings new types of risks that need to be evaluated from the aspects of technology, ethics and regulations. Based on public crash data from the National Highway Traffic Safety Administration (NHTSA), disengagement reports from the California Department of Motor Vehicles (DMV), the MIT Moral Machines dataset, and a comparative regulatory analysis of five jurisdictions, we have found that the main types of technical failure modes are perception and classification errors. These account for a relatively large proportion of the reported accidents, and it can be concluded that there are different ethical frameworks for autonomous vehicle decision-making, and inconsistent regulations in different areas increase the uncertainty of widespread application. Generally speaking, the problems of technology, ethics and regulation are closely related and need to be solved together. Therefore, this paper recommends a more adaptive and cooperative governance approach that combines engineering standards, ethical discussion, and institutional supervision.
VulTriage: Triple-Path Context Augmentation for LLM-Based Vulnerability Detection
May 10, 2026Automated vulnerability detection is a fundamental task in software security, yet existing learning-based methods still struggle to capture the structural dependencies, domain-specific vulnerability knowledge, and complex program semantics required for accurate detection. Recent Large Language Models (LLMs) have shown strong code understanding ability, but directly prompting them with raw source code often leads to missed vulnerabilities or false alarms, especially when vulnerable and benign functions differ only in subtle semantic details. To address this, we propose VulTriage, a triple-path context augmentation framework for LLM-based vulnerability detection. VulTriage enhances the LLM input through three complementary paths: a Control Path that extracts and verbalizes AST, CFG, and DFG information to expose control and data dependencies; a Knowledge Path that retrieves relevant CWE-derived vulnerability patterns and examples through hybrid dense--sparse retrieval; and a Semantic Path that summarizes the functional behavior of the code before the final judgment. These contexts are integrated into a unified instruction to guide the LLM toward more reliable vulnerability reasoning. Experiments on the PrimeVul pair test set show that VulTriage achieves state-of-the-art performance, outperforming existing deep learning and LLM-based baselines on key pair-wise and classification metrics. Further ablation studies verify the effectiveness of each path, and additional experiments on the Kotlin dataset demonstrate the generalization ability of VulTriage under low-resource and class-imbalanced settings. Our code is available at https://github.com/vinsontang1/VulTriage
SenseFlow: A Physics-Informed and Self-Ensembling Iterative Framework for Power Flow Estimation
May 18, 2025Power flow estimation plays a vital role in ensuring the stability and reliability of electrical power systems, particularly in the context of growing network complexities and renewable energy integration. However, existing studies often fail to adequately address the unique characteristics of power systems, such as the sparsity of network connections and the critical importance of the unique Slack node, which poses significant challenges in achieving high-accuracy estimations. In this paper, we present SenseFlow, a novel physics-informed and self-ensembling iterative framework that integrates two main designs, the Physics-Informed Power Flow Network (FlowNet) and Self-Ensembling Iterative Estimation (SeIter), to carefully address the unique properties of the power system and thereby enhance the power flow estimation. Specifically, SenseFlow enforces the FlowNet to gradually predict high-precision voltage magnitudes and phase angles through the iterative SeIter process. On the one hand, FlowNet employs the Virtual Node Attention and Slack-Gated Feed-Forward modules to facilitate efficient global-local communication in the face of network sparsity and amplify the influence of the Slack node on angle predictions, respectively. On the other hand, SeIter maintains an exponential moving average of FlowNet's parameters to create a robust ensemble model that refines power state predictions throughout the iterative fitting process. Experimental results demonstrate that SenseFlow outperforms existing methods, providing a promising solution for high-accuracy power flow estimation across diverse grid configurations.
PTCL: Pseudo-Label Temporal Curriculum Learning for Label-Limited Dynamic Graph
Apr 24, 2025Dynamic node classification is critical for modeling evolving systems like financial transactions and academic collaborations. In such systems, dynamically capturing node information changes is critical for dynamic node classification, which usually requires all labels at every timestamp. However, it is difficult to collect all dynamic labels in real-world scenarios due to high annotation costs and label uncertainty (e.g., ambiguous or delayed labels in fraud detection). In contrast, final timestamp labels are easier to obtain as they rely on complete temporal patterns and are usually maintained as a unique label for each user in many open platforms, without tracking the history data. To bridge this gap, we propose PTCL(Pseudo-label Temporal Curriculum Learning), a pioneering method addressing label-limited dynamic node classification where only final labels are available. PTCL introduces: (1) a temporal decoupling architecture separating the backbone (learning time-aware representations) and decoder (strictly aligned with final labels), which generate pseudo-labels, and (2) a Temporal Curriculum Learning strategy that prioritizes pseudo-labels closer to the final timestamp by assigning them higher weights using an exponentially decaying function. We contribute a new academic dataset (CoOAG), capturing long-range research interest in dynamic graph. Experiments across real-world scenarios demonstrate PTCL's consistent superiority over other methods adapted to this task. Beyond methodology, we propose a unified framework FLiD (Framework for Label-Limited Dynamic Node Classification), consisting of a complete preparation workflow, training pipeline, and evaluation standards, and supporting various models and datasets. The code can be found at https://github.com/3205914485/FLiD.
DiN: Diffusion Model for Robust Medical VQA with Semantic Noisy Labels
Mar 24, 2025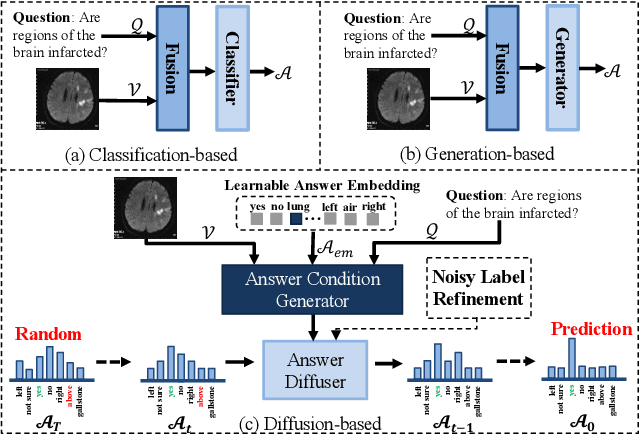
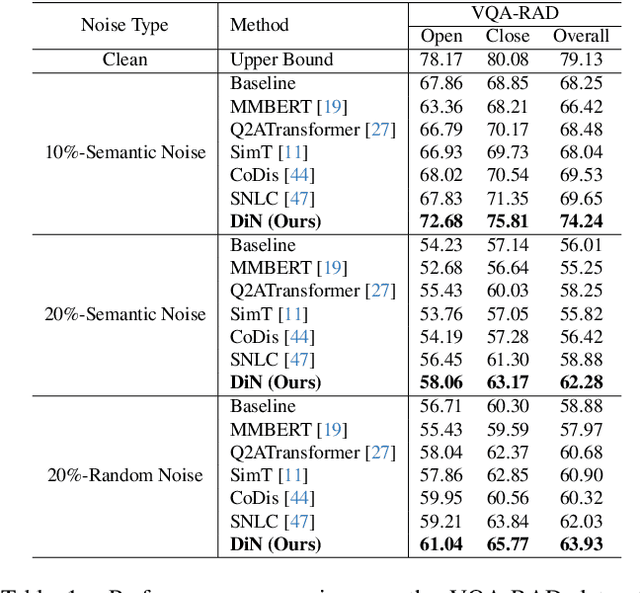
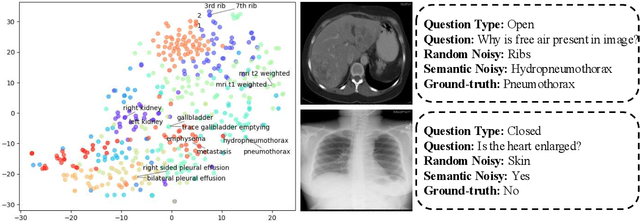
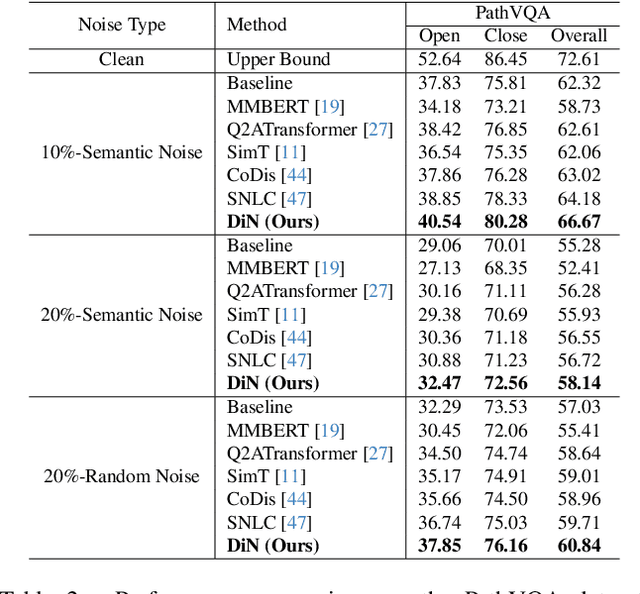
Medical Visual Question Answering (Med-VQA) systems benefit the interpretation of medical images containing critical clinical information. However, the challenge of noisy labels and limited high-quality datasets remains underexplored. To address this, we establish the first benchmark for noisy labels in Med-VQA by simulating human mislabeling with semantically designed noise types. More importantly, we introduce the DiN framework, which leverages a diffusion model to handle noisy labels in Med-VQA. Unlike the dominant classification-based VQA approaches that directly predict answers, our Answer Diffuser (AD) module employs a coarse-to-fine process, refining answer candidates with a diffusion model for improved accuracy. The Answer Condition Generator (ACG) further enhances this process by generating task-specific conditional information via integrating answer embeddings with fused image-question features. To address label noise, our Noisy Label Refinement(NLR) module introduces a robust loss function and dynamic answer adjustment to further boost the performance of the AD module.
Imbalanced Medical Image Segmentation with Pixel-dependent Noisy Labels
Jan 12, 2025



Accurate medical image segmentation is often hindered by noisy labels in training data, due to the challenges of annotating medical images. Prior research works addressing noisy labels tend to make class-dependent assumptions, overlooking the pixel-dependent nature of most noisy labels. Furthermore, existing methods typically apply fixed thresholds to filter out noisy labels, risking the removal of minority classes and consequently degrading segmentation performance. To bridge these gaps, our proposed framework, Collaborative Learning with Curriculum Selection (CLCS), addresses pixel-dependent noisy labels with class imbalance. CLCS advances the existing works by i) treating noisy labels as pixel-dependent and addressing them through a collaborative learning framework, and ii) employing a curriculum dynamic thresholding approach adapting to model learning progress to select clean data samples to mitigate the class imbalance issue, and iii) applying a noise balance loss to noisy data samples to improve data utilization instead of discarding them outright. Specifically, our CLCS contains two modules: Curriculum Noisy Label Sample Selection (CNS) and Noise Balance Loss (NBL). In the CNS module, we designed a two-branch network with discrepancy loss for collaborative learning so that different feature representations of the same instance could be extracted from distinct views and used to vote the class probabilities of pixels. Besides, a curriculum dynamic threshold is adopted to select clean-label samples through probability voting. In the NBL module, instead of directly dropping the suspiciously noisy labels, we further adopt a robust loss to leverage such instances to boost the performance.
UniBrain: A Unified Model for Cross-Subject Brain Decoding
Dec 27, 2024



Brain decoding aims to reconstruct original stimuli from fMRI signals, providing insights into interpreting mental content. Current approaches rely heavily on subject-specific models due to the complex brain processing mechanisms and the variations in fMRI signals across individuals. Therefore, these methods greatly limit the generalization of models and fail to capture cross-subject commonalities. To address this, we present UniBrain, a unified brain decoding model that requires no subject-specific parameters. Our approach includes a group-based extractor to handle variable fMRI signal lengths, a mutual assistance embedder to capture cross-subject commonalities, and a bilevel feature alignment scheme for extracting subject-invariant features. We validate our UniBrain on the brain decoding benchmark, achieving comparable performance to current state-of-the-art subject-specific models with extremely fewer parameters. We also propose a generalization benchmark to encourage the community to emphasize cross-subject commonalities for more general brain decoding. Our code is available at https://github.com/xiaoyao3302/UniBrain.
MoTe: Learning Motion-Text Diffusion Model for Multiple Generation Tasks
Nov 29, 2024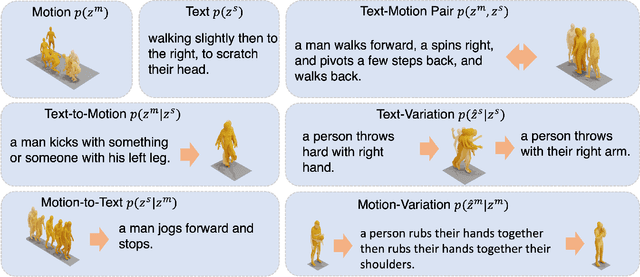

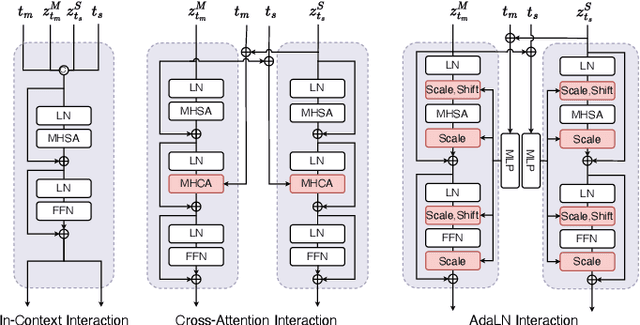

Recently, human motion analysis has experienced great improvement due to inspiring generative models such as the denoising diffusion model and large language model. While the existing approaches mainly focus on generating motions with textual descriptions and overlook the reciprocal task. In this paper, we present~\textbf{MoTe}, a unified multi-modal model that could handle diverse tasks by learning the marginal, conditional, and joint distributions of motion and text simultaneously. MoTe enables us to handle the paired text-motion generation, motion captioning, and text-driven motion generation by simply modifying the input context. Specifically, MoTe is composed of three components: Motion Encoder-Decoder (MED), Text Encoder-Decoder (TED), and Moti-on-Text Diffusion Model (MTDM). In particular, MED and TED are trained for extracting latent embeddings, and subsequently reconstructing the motion sequences and textual descriptions from the extracted embeddings, respectively. MTDM, on the other hand, performs an iterative denoising process on the input context to handle diverse tasks. Experimental results on the benchmark datasets demonstrate the superior performance of our proposed method on text-to-motion generation and competitive performance on motion captioning.
Towards Small Object Editing: A Benchmark Dataset and A Training-Free Approach
Nov 03, 2024



A plethora of text-guided image editing methods has recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models especially Stable Diffusion. Despite the success of diffusion models in producing high-quality images, their application to small object generation has been limited due to difficulties in aligning cross-modal attention maps between text and these objects. Our approach offers a training-free method that significantly mitigates this alignment issue with local and global attention guidance , enhancing the model's ability to accurately render small objects in accordance with textual descriptions. We detail the methodology in our approach, emphasizing its divergence from traditional generation techniques and highlighting its advantages. What's more important is that we also provide~\textit{SOEBench} (Small Object Editing), a standardized benchmark for quantitatively evaluating text-based small object generation collected from \textit{MSCOCO} and \textit{OpenImage}. Preliminary results demonstrate the effectiveness of our method, showing marked improvements in the fidelity and accuracy of small object generation compared to existing models. This advancement not only contributes to the field of AI and computer vision but also opens up new possibilities for applications in various industries where precise image generation is critical. We will release our dataset on our project page: \href{https://soebench.github.io/}{https://soebench.github.io/}.
A Dual-Channel Particle Swarm Optimization Algorithm Based on Adaptive Balance Search
Jun 25, 2024The balance between exploration (Er) and exploitation (Ei) determines the generalization performance of the particle swarm optimization (PSO) algorithm on different problems. Although the insufficient balance caused by global best being located near a local minimum has been widely researched, few scholars have systematically paid attention to two behaviors about personal best position (P) and global best position (G) existing in PSO. 1) P's uncontrollable-exploitation and involuntary-exploration guidance behavior. 2) G's full-time and global guidance behavior, each of which negatively affects the balance of Er and Ei. With regards to this, we firstly discuss the two behaviors, unveiling the mechanisms by which they affect the balance, and further pinpoint three key points for better balancing Er and Ei: eliminating the coupling between P and G, empowering P with controllable-exploitation and voluntary-exploration guidance behavior, controlling G's full-time and global guidance behavior. Then, we present a dual-channel PSO algorithm based on adaptive balance search (DCPSO-ABS). This algorithm entails a dual-channel framework to mitigate the interaction of P and G, aiding in regulating the behaviors of P and G, and meanwhile an adaptive balance search strategy for empowering P with voluntary-exploration and controllable-exploitation guidance behavior as well as adaptively controlling G's full-time and global guidance behavior. Finally, three kinds of experiments on 57 benchmark functions are designed to demonstrate that our proposed algorithm has stronger generalization performance than selected state-of-the-art algorithms.