 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Small Object Editing: A Benchmark Dataset and A Training-Free Approach
Nov 03, 2024



A plethora of text-guided image editing methods has recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models especially Stable Diffusion. Despite the success of diffusion models in producing high-quality images, their application to small object generation has been limited due to difficulties in aligning cross-modal attention maps between text and these objects. Our approach offers a training-free method that significantly mitigates this alignment issue with local and global attention guidance , enhancing the model's ability to accurately render small objects in accordance with textual descriptions. We detail the methodology in our approach, emphasizing its divergence from traditional generation techniques and highlighting its advantages. What's more important is that we also provide~\textit{SOEBench} (Small Object Editing), a standardized benchmark for quantitatively evaluating text-based small object generation collected from \textit{MSCOCO} and \textit{OpenImage}. Preliminary results demonstrate the effectiveness of our method, showing marked improvements in the fidelity and accuracy of small object generation compared to existing models. This advancement not only contributes to the field of AI and computer vision but also opens up new possibilities for applications in various industries where precise image generation is critical. We will release our dataset on our project page: \href{https://soebench.github.io/}{https://soebench.github.io/}.
SOEDiff: Efficient Distillation for Small Object Editing
May 15, 2024In this paper, we delve into a new task known as small object editing (SOE), which focuses on text-based image inpainting within a constrained, small-sized area. Despite the remarkable success have been achieved by current image inpainting approaches, their application to the SOE task generally results in failure cases such as Object Missing, Text-Image Mismatch, and Distortion. These failures stem from the limited use of small-sized objects in training datasets and the downsampling operations employed by U-Net models, which hinders accurate generation. To overcome these challenges, we introduce a novel training-based approach, SOEDiff, aimed at enhancing the capability of baseline models like StableDiffusion in editing small-sized objects while minimizing training costs. Specifically, our method involves two key components: SO-LoRA, which efficiently fine-tunes low-rank matrices, and Cross-Scale Score Distillation loss, which leverages high-resolution predictions from the pre-trained teacher diffusion model. Our method presents significant improvements on the test dataset collected from MSCOCO and OpenImage, validating the effectiveness of our proposed method in small object editing. In particular, when comparing SOEDiff with SD-I model on the OpenImage-f dataset, we observe a 0.99 improvement in CLIP-Score and a reduction of 2.87 in FID. Our project page can be found in https://soediff.github.io/.
A General Visual Representation Guided Framework with Global Affinity for Weakly Supervised Salient Object Detection
Feb 21, 2023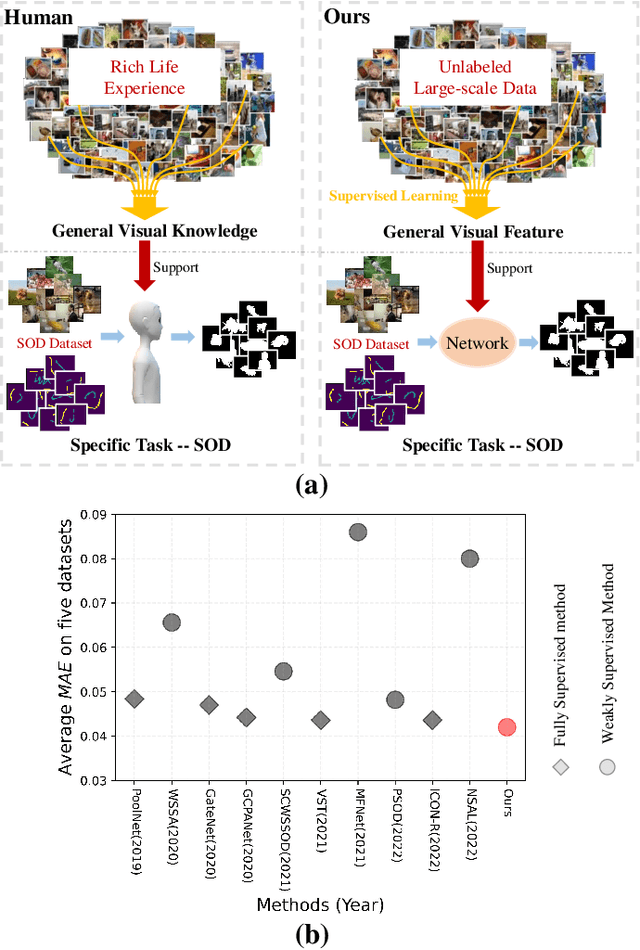
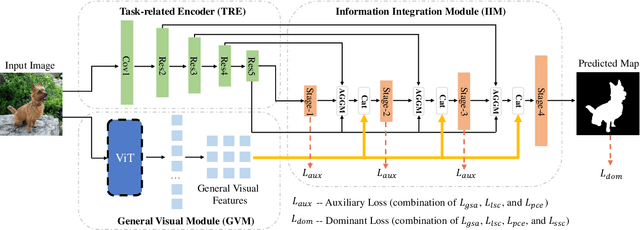

Fully supervised salient object detection (SOD) methods have made considerable progress in performance, yet these models rely heavily on expensive pixel-wise labels. Recently, to achieve a trade-off between labeling burden and performance, scribble-based SOD methods have attracted increasing attention. Previous models directly implement the SOD task only based on small-scale SOD training data. Due to the limited information provided by the weakly scribble tags and such small-scale training data, it is extremely difficult for them to understand the image and further achieve a superior SOD task. In this paper, we propose a simple yet effective framework guided by general visual representations that simulate the general cognition of humans for scribble-based SOD. It consists of a task-related encoder, a general visual module, and an information integration module to combine efficiently the general visual representations learned from large-scale unlabeled datasets with task-related features to perform the SOD task based on understanding the contextual connections of images. Meanwhile, we propose a novel global semantic affinity loss to guide the model to perceive the global structure of the salient objects. Experimental results on five public benchmark datasets demonstrate that our method that only utilizes scribble annotations without introducing any extra label outperforms the state-of-the-art weakly supervised SOD methods and is comparable or even superior to the state-of-the-art fully supervised models.
Synthesize Boundaries: A Boundary-aware Self-consistent Framework for Weakly Supervised Salient Object Detection
Dec 04, 2022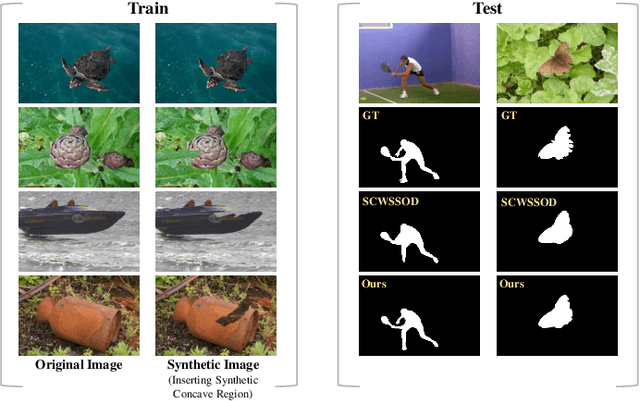
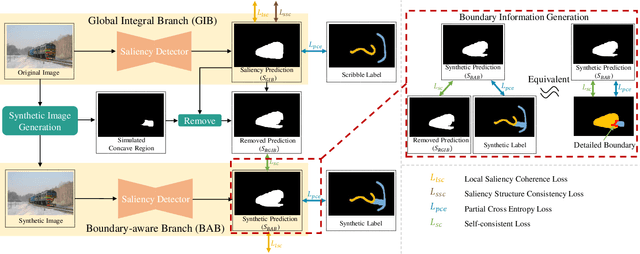
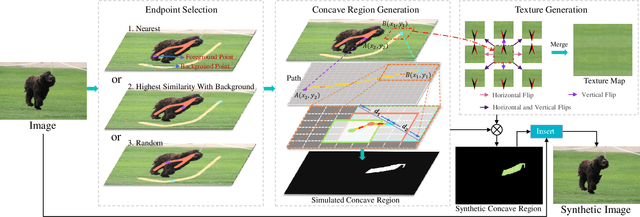
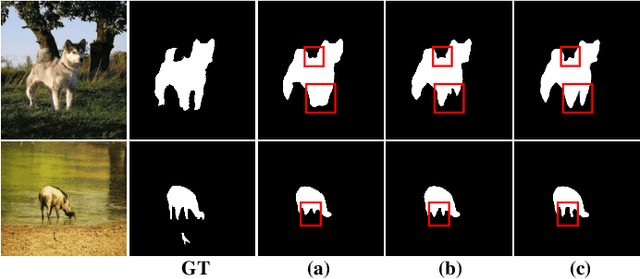
Fully supervised salient object detection (SOD) has made considerable progress based on expensive and time-consuming data with pixel-wise annotations. Recently, to relieve the labeling burden while maintaining performance, some scribble-based SOD methods have been proposed. However, learning precise boundary details from scribble annotations that lack edge information is still difficult. In this paper, we propose to learn precise boundaries from our designed synthetic images and labels without introducing any extra auxiliary data. The synthetic image creates boundary information by inserting synthetic concave regions that simulate the real concave regions of salient objects. Furthermore, we propose a novel self-consistent framework that consists of a global integral branch (GIB) and a boundary-aware branch (BAB) to train a saliency detector. GIB aims to identify integral salient objects, whose input is the original image. BAB aims to help predict accurate boundaries, whose input is the synthetic image. These two branches are connected through a self-consistent loss to guide the saliency detector to predict precise boundaries while identifying salient objects. Experimental results on five benchmarks demonstrate that our method outperforms the state-of-the-art weakly supervised SOD methods and further narrows the gap with the fully supervised methods.
Motion-aware Memory Network for Fast Video Salient Object Detection
Aug 01, 2022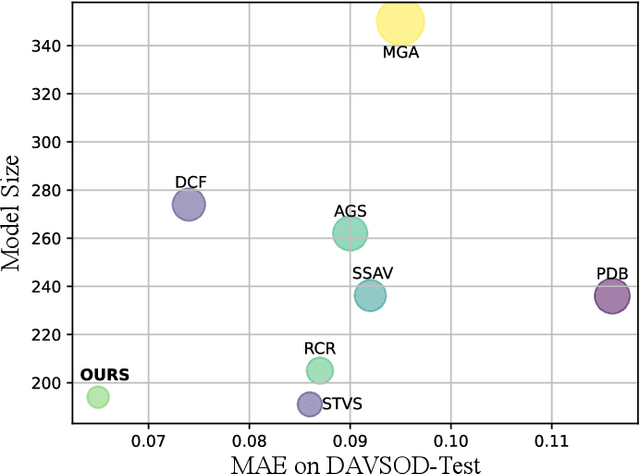

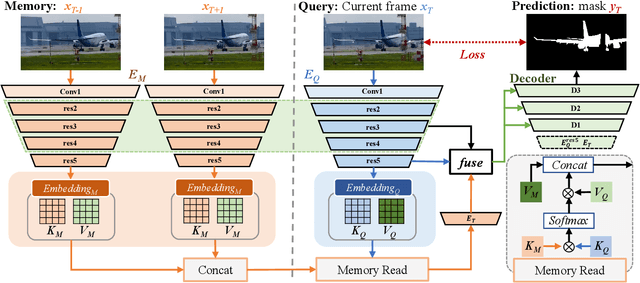
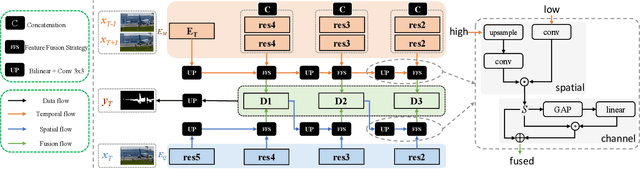
Previous methods based on 3DCNN, convLSTM, or optical flow have achieved great success in video salient object detection (VSOD). However, they still suffer from high computational costs or poor quality of the generated saliency maps. To solve these problems, we design a space-time memory (STM)-based network, which extracts useful temporal information of the current frame from adjacent frames as the temporal branch of VSOD. Furthermore, previous methods only considered single-frame prediction without temporal association. As a result, the model may not focus on the temporal information sufficiently. Thus, we initially introduce object motion prediction between inter-frame into VSOD. Our model follows standard encoder--decoder architecture. In the encoding stage, we generate high-level temporal features by using high-level features from the current and its adjacent frames. This approach is more efficient than the optical flow-based methods. In the decoding stage, we propose an effective fusion strategy for spatial and temporal branches. The semantic information of the high-level features is used to fuse the object details in the low-level features, and then the spatiotemporal features are obtained step by step to reconstruct the saliency maps. Moreover, inspired by the boundary supervision commonly used in image salient object detection (ISOD), we design a motion-aware loss for predicting object boundary motion and simultaneously perform multitask learning for VSOD and object motion prediction, which can further facilitate the model to extract spatiotemporal features accurately and maintain the object integrity. Extensive experiments on several datasets demonstrated the effectiveness of our method and can achieve state-of-the-art metrics on some datasets. The proposed model does not require optical flow or other preprocessing, and can reach a speed of nearly 100 FPS during inference.
Learning Video Salient Object Detection Progressively from Unlabeled Videos
Apr 05, 2022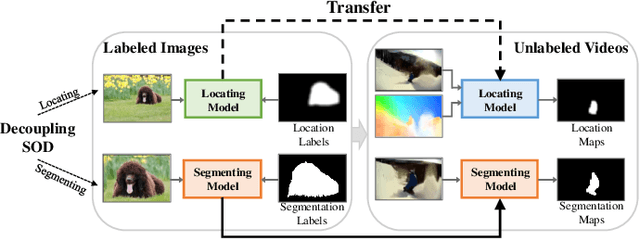
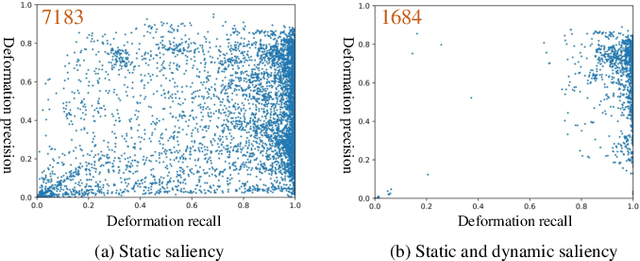
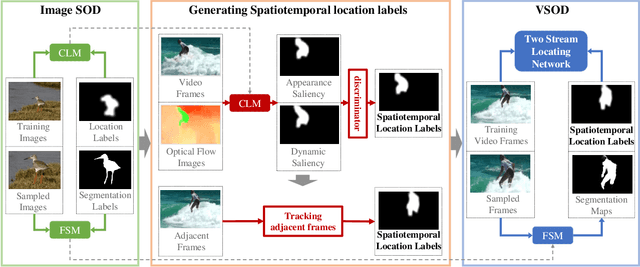
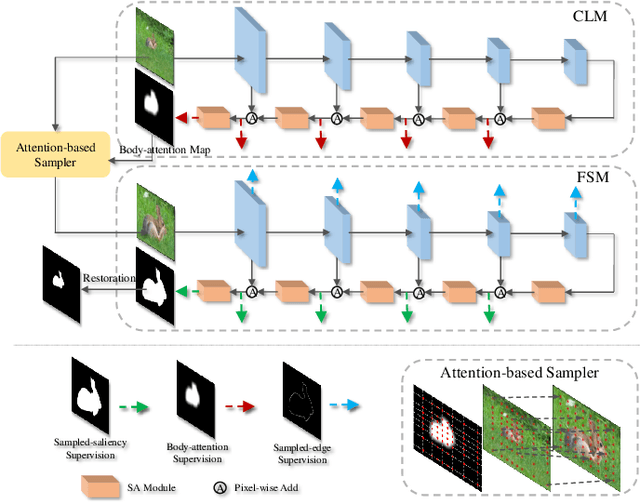
Recent deep learning-based video salient object detection (VSOD) has achieved some breakthrough, but these methods rely on expensive annotated videos with pixel-wise annotations, weak annotations, or part of the pixel-wise annotations. In this paper, based on the similarities and the differences between VSOD and image salient object detection (SOD), we propose a novel VSOD method via a progressive framework that locates and segments salient objects in sequence without utilizing any video annotation. To use the knowledge learned in the SOD dataset for VSOD efficiently, we introduce dynamic saliency to compensate for the lack of motion information of SOD during the locating process but retain the same fine segmenting process. Specifically, an algorithm for generating spatiotemporal location labels, which consists of generating high-saliency location labels and tracking salient objects in adjacent frames, is proposed. Based on these location labels, a two-stream locating network that introduces an optical flow branch for video salient object locating is presented. Although our method does not require labeled video at all, the experimental results on five public benchmarks of DAVIS, FBMS, ViSal, VOS, and DAVSOD demonstrate that our proposed method is competitive with fully supervised methods and outperforms the state-of-the-art weakly and unsupervised methods.