 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Small Object Editing: A Benchmark Dataset and A Training-Free Approach
Nov 03, 2024



A plethora of text-guided image editing methods has recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models especially Stable Diffusion. Despite the success of diffusion models in producing high-quality images, their application to small object generation has been limited due to difficulties in aligning cross-modal attention maps between text and these objects. Our approach offers a training-free method that significantly mitigates this alignment issue with local and global attention guidance , enhancing the model's ability to accurately render small objects in accordance with textual descriptions. We detail the methodology in our approach, emphasizing its divergence from traditional generation techniques and highlighting its advantages. What's more important is that we also provide~\textit{SOEBench} (Small Object Editing), a standardized benchmark for quantitatively evaluating text-based small object generation collected from \textit{MSCOCO} and \textit{OpenImage}. Preliminary results demonstrate the effectiveness of our method, showing marked improvements in the fidelity and accuracy of small object generation compared to existing models. This advancement not only contributes to the field of AI and computer vision but also opens up new possibilities for applications in various industries where precise image generation is critical. We will release our dataset on our project page: \href{https://soebench.github.io/}{https://soebench.github.io/}.
SOEDiff: Efficient Distillation for Small Object Editing
May 15, 2024In this paper, we delve into a new task known as small object editing (SOE), which focuses on text-based image inpainting within a constrained, small-sized area. Despite the remarkable success have been achieved by current image inpainting approaches, their application to the SOE task generally results in failure cases such as Object Missing, Text-Image Mismatch, and Distortion. These failures stem from the limited use of small-sized objects in training datasets and the downsampling operations employed by U-Net models, which hinders accurate generation. To overcome these challenges, we introduce a novel training-based approach, SOEDiff, aimed at enhancing the capability of baseline models like StableDiffusion in editing small-sized objects while minimizing training costs. Specifically, our method involves two key components: SO-LoRA, which efficiently fine-tunes low-rank matrices, and Cross-Scale Score Distillation loss, which leverages high-resolution predictions from the pre-trained teacher diffusion model. Our method presents significant improvements on the test dataset collected from MSCOCO and OpenImage, validating the effectiveness of our proposed method in small object editing. In particular, when comparing SOEDiff with SD-I model on the OpenImage-f dataset, we observe a 0.99 improvement in CLIP-Score and a reduction of 2.87 in FID. Our project page can be found in https://soediff.github.io/.
Training-Free Unsupervised Prompt for Vision-Language Models
Apr 25, 2024



Prompt learning has become the most effective paradigm for adapting large pre-trained vision-language models (VLMs) to downstream tasks. Recently, unsupervised prompt tuning methods, such as UPL and POUF, directly leverage pseudo-labels as supervisory information to fine-tune additional adaptation modules on unlabeled data. However, inaccurate pseudo labels easily misguide the tuning process and result in poor representation capabilities. In light of this, we propose Training-Free Unsupervised Prompts (TFUP), which maximally preserves the inherent representation capabilities and enhances them with a residual connection to similarity-based prediction probabilities in a training-free and labeling-free manner. Specifically, we integrate both instance confidence and prototype scores to select representative samples, which are used to customize a reliable Feature Cache Model (FCM) for training-free inference. Then, we design a Multi-level Similarity Measure (MSM) that considers both feature-level and semantic-level similarities to calculate the distance between each test image and the cached sample as the weight of the corresponding cached label to generate similarity-based prediction probabilities. In this way, TFUP achieves surprising performance, even surpassing the training-base method on multiple classification datasets. Based on our TFUP, we propose a training-based approach (TFUP-T) to further boost the adaptation performance. In addition to the standard cross-entropy loss, TFUP-T adopts an additional marginal distribution entropy loss to constrain the model from a global perspective. Our TFUP-T achieves new state-of-the-art classification performance compared to unsupervised and few-shot adaptation approaches on multiple benchmarks. In particular, TFUP-T improves the classification accuracy of POUF by 3.3% on the most challenging Domain-Net dataset.
Troublemaker Learning for Low-Light Image Enhancement
Feb 07, 2024



Low-light image enhancement (LLIE) restores the color and brightness of underexposed images. Supervised methods suffer from high costs in collecting low/normal-light image pairs. Unsupervised methods invest substantial effort in crafting complex loss functions. We address these two challenges through the proposed TroubleMaker Learning (TML) strategy, which employs normal-light images as inputs for training. TML is simple: we first dim the input and then increase its brightness. TML is based on two core components. First, the troublemaker model (TM) constructs pseudo low-light images from normal images to relieve the cost of pairwise data. Second, the predicting model (PM) enhances the brightness of pseudo low-light images. Additionally, we incorporate an enhancing model (EM) to further improve the visual performance of PM outputs. Moreover, in LLIE tasks, characterizing global element correlations is important because more information on the same object can be captured. CNN cannot achieve this well, and self-attention has high time complexity. Accordingly, we propose Global Dynamic Convolution (GDC) with O(n) time complexity, which essentially imitates the partial calculation process of self-attention to formulate elementwise correlations. Based on the GDC module, we build the UGDC model. Extensive quantitative and qualitative experiments demonstrate that UGDC trained with TML can achieve competitive performance against state-of-the-art approaches on public datasets. The code is available at https://github.com/Rainbowman0/TML_LLIE.
HAP: Structure-Aware Masked Image Modeling for Human-Centric Perception
Oct 31, 2023Model pre-training is essential in human-centric perception. In this paper, we first introduce masked image modeling (MIM) as a pre-training approach for this task. Upon revisiting the MIM training strategy, we reveal that human structure priors offer significant potential. Motivated by this insight, we further incorporate an intuitive human structure prior - human parts - into pre-training. Specifically, we employ this prior to guide the mask sampling process. Image patches, corresponding to human part regions, have high priority to be masked out. This encourages the model to concentrate more on body structure information during pre-training, yielding substantial benefits across a range of human-centric perception tasks. To further capture human characteristics, we propose a structure-invariant alignment loss that enforces different masked views, guided by the human part prior, to be closely aligned for the same image. We term the entire method as HAP. HAP simply uses a plain ViT as the encoder yet establishes new state-of-the-art performance on 11 human-centric benchmarks, and on-par result on one dataset. For example, HAP achieves 78.1% mAP on MSMT17 for person re-identification, 86.54% mA on PA-100K for pedestrian attribute recognition, 78.2% AP on MS COCO for 2D pose estimation, and 56.0 PA-MPJPE on 3DPW for 3D pose and shape estimation.
Task-Oriented Multi-Modal Mutual Leaning for Vision-Language Models
Mar 30, 2023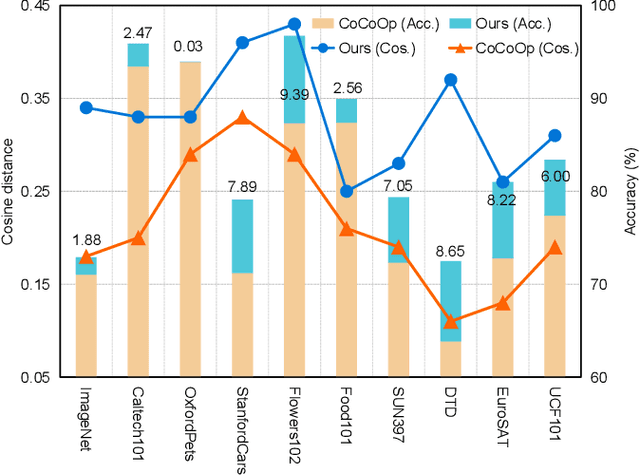
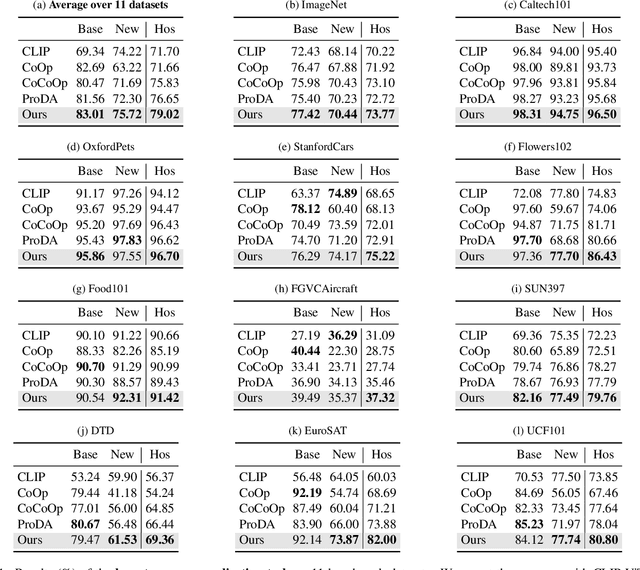
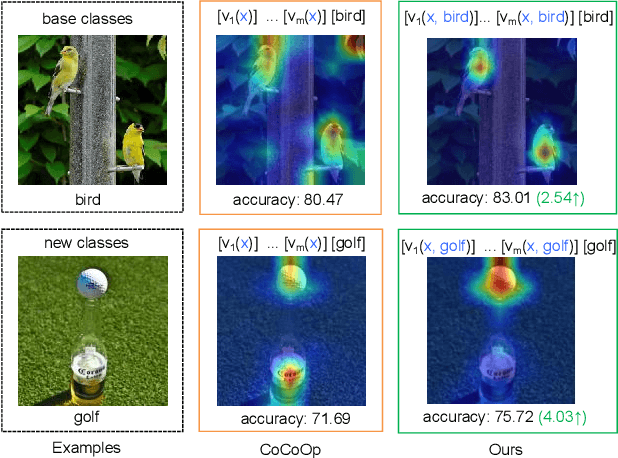
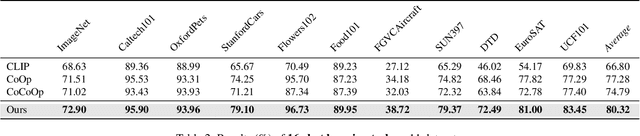
Prompt learning has become one of the most efficient paradigms for adapting large pre-trained vision-language models to downstream tasks. Current state-of-the-art methods, like CoOp and ProDA, tend to adopt soft prompts to learn an appropriate prompt for each specific task. Recent CoCoOp further boosts the base-to-new generalization performance via an image-conditional prompt. However, it directly fuses identical image semantics to prompts of different labels and significantly weakens the discrimination among different classes as shown in our experiments. Motivated by this observation, we first propose a class-aware text prompt (CTP) to enrich generated prompts with label-related image information. Unlike CoCoOp, CTP can effectively involve image semantics and avoid introducing extra ambiguities into different prompts. On the other hand, instead of reserving the complete image representations, we propose text-guided feature tuning (TFT) to make the image branch attend to class-related representation. A contrastive loss is employed to align such augmented text and image representations on downstream tasks. In this way, the image-to-text CTP and text-to-image TFT can be mutually promoted to enhance the adaptation of VLMs for downstream tasks. Extensive experiments demonstrate that our method outperforms the existing methods by a significant margin. Especially, compared to CoCoOp, we achieve an average improvement of 4.03% on new classes and 3.19% on harmonic-mean over eleven classification benchmarks.
Augmentation Matters: A Simple-yet-Effective Approach to Semi-supervised Semantic Segmentation
Dec 09, 2022



Recent studies on semi-supervised semantic segmentation (SSS) have seen fast progress. Despite their promising performance, current state-of-the-art methods tend to increasingly complex designs at the cost of introducing more network components and additional training procedures. Differently, in this work, we follow a standard teacher-student framework and propose AugSeg, a simple and clean approach that focuses mainly on data perturbations to boost the SSS performance. We argue that various data augmentations should be adjusted to better adapt to the semi-supervised scenarios instead of directly applying these techniques from supervised learning. Specifically, we adopt a simplified intensity-based augmentation that selects a random number of data transformations with uniformly sampling distortion strengths from a continuous space. Based on the estimated confidence of the model on different unlabeled samples, we also randomly inject labelled information to augment the unlabeled samples in an adaptive manner. Without bells and whistles, our simple AugSeg can readily achieve new state-of-the-art performance on SSS benchmarks under different partition protocols.
Instance-specific and Model-adaptive Supervision for Semi-supervised Semantic Segmentation
Nov 21, 2022



Recently, semi-supervised semantic segmentation has achieved promising performance with a small fraction of labeled data. However, most existing studies treat all unlabeled data equally and barely consider the differences and training difficulties among unlabeled instances. Differentiating unlabeled instances can promote instance-specific supervision to adapt to the model's evolution dynamically. In this paper, we emphasize the cruciality of instance differences and propose an instance-specific and model-adaptive supervision for semi-supervised semantic segmentation, named iMAS. Relying on the model's performance, iMAS employs a class-weighted symmetric intersection-over-union to evaluate quantitative hardness of each unlabeled instance and supervises the training on unlabeled data in a model-adaptive manner. Specifically, iMAS learns from unlabeled instances progressively by weighing their corresponding consistency losses based on the evaluated hardness. Besides, iMAS dynamically adjusts the augmentation for each instance such that the distortion degree of augmented instances is adapted to the model's generalization capability across the training course. Not integrating additional losses and training procedures, iMAS can obtain remarkable performance gains against current state-of-the-art approaches on segmentation benchmarks under different semi-supervised partition protocols.
Beyond Attentive Tokens: Incorporating Token Importance and Diversity for Efficient Vision Transformers
Nov 21, 2022



Vision transformers have achieved significant improvements on various vision tasks but their quadratic interactions between tokens significantly reduce computational efficiency. Many pruning methods have been proposed to remove redundant tokens for efficient vision transformers recently. However, existing studies mainly focus on the token importance to preserve local attentive tokens but completely ignore the global token diversity. In this paper, we emphasize the cruciality of diverse global semantics and propose an efficient token decoupling and merging method that can jointly consider the token importance and diversity for token pruning. According to the class token attention, we decouple the attentive and inattentive tokens. In addition to preserving the most discriminative local tokens, we merge similar inattentive tokens and match homogeneous attentive tokens to maximize the token diversity. Despite its simplicity, our method obtains a promising trade-off between model complexity and classification accuracy. On DeiT-S, our method reduces the FLOPs by 35% with only a 0.2% accuracy drop. Notably, benefiting from maintaining the token diversity, our method can even improve the accuracy of DeiT-T by 0.1% after reducing its FLOPs by 40%.