 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeHash: Learning Binary Codes with Spiking Neural Networks for Cross-Modal Hashing Retrieval
May 30, 2026Cross-modal hashing retrieval encodes heterogeneous data into compact binary codes for efficient Hamming-space search. Existing methods usually learn cross-modal semantics in continuous feature spaces and generate binary codes through a final sign operation, which weakly couples training optimization with discrete hash retrieval. We propose SpikeHash, a unified spiking framework that formulates cross-modal hashing as spike-state evolution, directional spike interaction, and competitive spike readout. Specifically, SpikeHash converts image and text features into multi-timestep spike sequences. In a shared Hamming space, the two spike sequences jointly drive the temporal evolution of a shared hash state. Cross-modal interaction is further performed through directional spike modulation, enabling each modality to influence the firing dynamics of the other. Crucially, SpikeHash replaces the conventional continuous hash head with a positive-negative spiking hash readout, where each hash bit is produced by temporal competition between paired spike channels. Experimental results show that SpikeHash achieves competitive retrieval accuracy on three benchmark datasets while reducing the parameter size, operation count, and estimated energy of the hash learning stage, suggesting a compact spiking alternative to conventional continuous hash mapping. The project page is available at https://shuqiao-111.github.io/.
Harmful Visual Content Manipulation Matters in Misinformation Detection Under Multimedia Scenarios
Mar 22, 2026Nowadays, the widespread dissemination of misinformation across numerous social media platforms has led to severe negative effects on society. To address this challenge, the automatic detection of misinformation, particularly under multimedia scenarios, has gained significant attention from both academic and industrial communities, leading to the emergence of a research task known as Multimodal Misinformation Detection (MMD). Typically, current MMD approaches focus on capturing the semantic relationships and inconsistency between various modalities but often overlook certain critical indicators within multimodal content. Recent research has shown that manipulated features within visual content in social media articles serve as valuable clues for MMD. Meanwhile, we argue that the potential intentions behind the manipulation, e.g., harmful and harmless, also matter in MMD. Therefore, in this study, we aim to identify such multimodal misinformation by capturing two types of features: manipulation features, which represent if visual content has been manipulated, and intention features, which assess the nature of these manipulations, distinguishing between harmful and harmless intentions. Unfortunately, the manipulation and intention labels that supervise these features to be discriminative are unknown. To address this, we introduce two weakly supervised indicators as substitutes by incorporating supplementary datasets focused on image manipulation detection and framing two different classification tasks as positive and unlabeled learning issues. With this framework, we introduce an innovative MMD approach, titled Harmful Visual Content Manipulation Matters in MMD (HAVC-M4 D). Comprehensive experiments conducted on four prevalent MMD datasets indicate that HAVC-M4 D significantly and consistently enhances the performance of existing MMD methods.
Enhancing Multimodal Misinformation Detection by Replaying the Whole Story from Image Modality Perspective
Nov 09, 2025
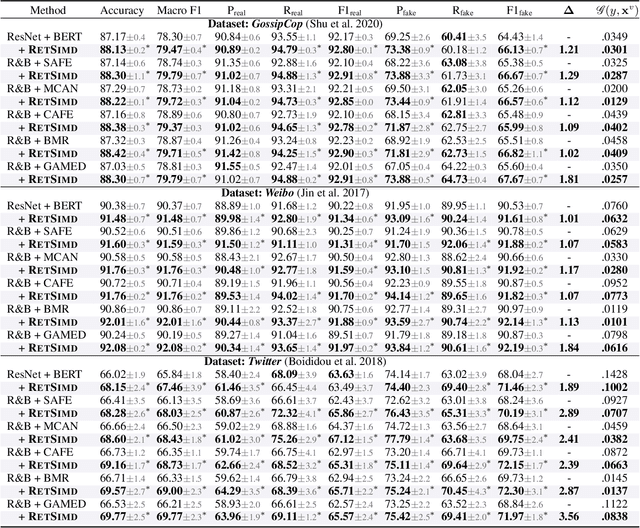
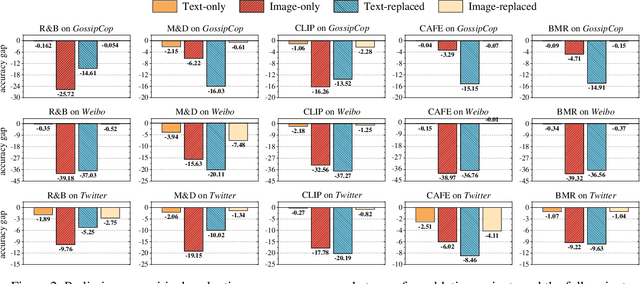
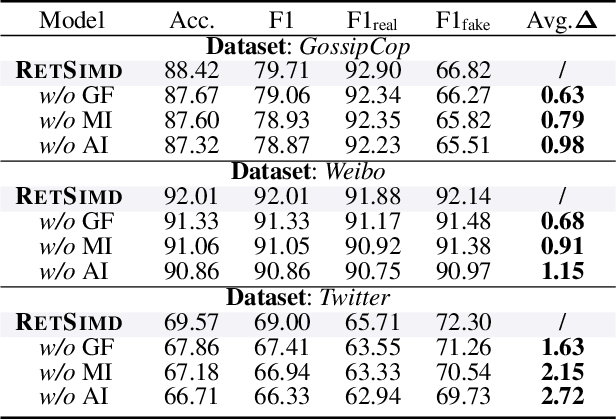
Multimodal Misinformation Detection (MMD) refers to the task of detecting social media posts involving misinformation, where the post often contains text and image modalities. However, by observing the MMD posts, we hold that the text modality may be much more informative than the image modality because the text generally describes the whole event/story of the current post but the image often presents partial scenes only. Our preliminary empirical results indicate that the image modality exactly contributes less to MMD. Upon this idea, we propose a new MMD method named RETSIMD. Specifically, we suppose that each text can be divided into several segments, and each text segment describes a partial scene that can be presented by an image. Accordingly, we split the text into a sequence of segments, and feed these segments into a pre-trained text-to-image generator to augment a sequence of images. We further incorporate two auxiliary objectives concerning text-image and image-label mutual information, and further post-train the generator over an auxiliary text-to-image generation benchmark dataset. Additionally, we propose a graph structure by defining three heuristic relationships between images, and use a graph neural network to generate the fused features. Extensive empirical results validate the effectiveness of RETSIMD.
ANPrompt: Anti-noise Prompt Tuning for Vision-Language Models
Aug 06, 2025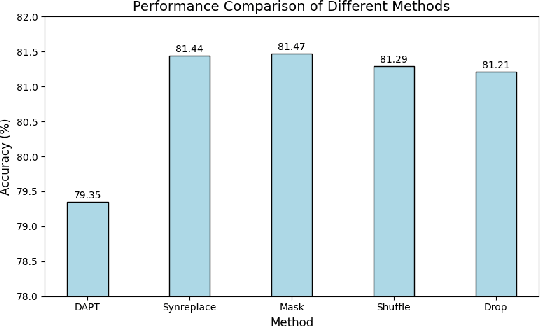
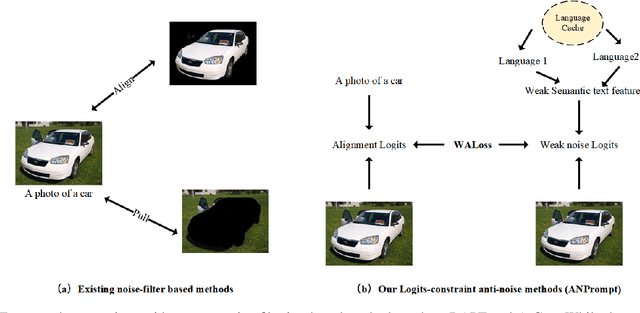
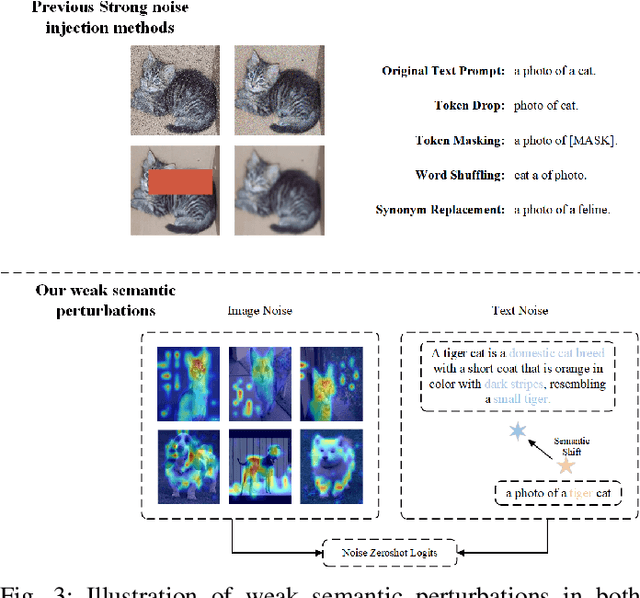

Prompt tuning has emerged as an efficient and effective technique for adapting vision-language models (VLMs) with low computational overhead. However, existing methods often overlook the vulnerability of prompt-tuned VLMs to weak semantic perturbations-such as subtle image or text noise-that degrade their generalization to unseen classes. To address this limitation, we propose ANPrompt, a novel prompt tuning framework designed to enhance robustness under such perturbations. ANPrompt first constructs weak noise text features by fusing original and noise-perturbed text embeddings, which are then clustered to form noise prompts. These noise prompts are integrated with learnable prompt tokens to generate anti-noise prompts, which are injected into the deeper layers of both image and text encoders. To further capture the noise-aware visual semantics, ANPrompt computes the Noise-Resistant Visual Prompt Prototype (NRVPP) by averaging the output prompt tokens from the vision encoder. Finally, ANPrompt introduces alignment, robustness, and anti-noise objectives by computing a Weak semantic noise Alignment Loss (WALoss) alongside the standard cross-entropy and sim loss. Experiments across 11 benchmarks demonstrate that ANPrompt consistently outperforms existing prompt tuning approaches, achieving superior robustness to semantic noise and improved generalization to novel categories.
Uncertainty-Aware Spatial Color Correlation for Low-Light Image Enhancement
Aug 06, 2025Most existing low-light image enhancement approaches primarily focus on architectural innovations, while often overlooking the intrinsic uncertainty within feature representations particularly under extremely dark conditions where degraded gradient and noise dominance severely impair model reliability and causal reasoning. To address these issues, we propose U2CLLIE, a novel framework that integrates uncertainty-aware enhancement and spatial-color causal correlation modeling. From the perspective of entropy-based uncertainty, our framework introduces two key components: (1) An Uncertainty-Aware Dual-domain Denoise (UaD) Module, which leverages Gaussian-Guided Adaptive Frequency Domain Feature Enhancement (G2AF) to suppress frequency-domain noise and optimize entropy-driven representations. This module enhances spatial texture extraction and frequency-domain noise suppression/structure refinement, effectively mitigating gradient vanishing and noise dominance. (2) A hierarchical causality-aware framework, where a Luminance Enhancement Network (LEN) first performs coarse brightness enhancement on dark regions. Then, during the encoder-decoder phase, two asymmetric causal correlation modeling modules Neighborhood Correlation State Space (NeCo) and Adaptive Spatial-Color Calibration (AsC) collaboratively construct hierarchical causal constraints. These modules reconstruct and reinforce neighborhood structure and color consistency in the feature space. Extensive experiments demonstrate that U2CLLIE achieves state-of-the-art performance across multiple benchmark datasets, exhibiting robust performance and strong generalization across various scenes.
Robust Misinformation Detection by Visiting Potential Commonsense Conflict
Apr 30, 2025



The development of Internet technology has led to an increased prevalence of misinformation, causing severe negative effects across diverse domains. To mitigate this challenge, Misinformation Detection (MD), aiming to detect online misinformation automatically, emerges as a rapidly growing research topic in the community. In this paper, we propose a novel plug-and-play augmentation method for the MD task, namely Misinformation Detection with Potential Commonsense Conflict (MD-PCC). We take inspiration from the prior studies indicating that fake articles are more likely to involve commonsense conflict. Accordingly, we construct commonsense expressions for articles, serving to express potential commonsense conflicts inferred by the difference between extracted commonsense triplet and golden ones inferred by the well-established commonsense reasoning tool COMET. These expressions are then specified for each article as augmentation. Any specific MD methods can be then trained on those commonsense-augmented articles. Besides, we also collect a novel commonsense-oriented dataset named CoMis, whose all fake articles are caused by commonsense conflict. We integrate MD-PCC with various existing MD backbones and compare them across both 4 public benchmark datasets and CoMis. Empirical results demonstrate that MD-PCC can consistently outperform the existing MD baselines.
Revisiting CLIP for SF-OSDA: Unleashing Zero-Shot Potential with Adaptive Threshold and Training-Free Feature Filtering
Apr 19, 2025Source-Free Unsupervised Open-Set Domain Adaptation (SF-OSDA) methods using CLIP face significant issues: (1) while heavily dependent on domain-specific threshold selection, existing methods employ simple fixed thresholds, underutilizing CLIP's zero-shot potential in SF-OSDA scenarios; and (2) overlook intrinsic class tendencies while employing complex training to enforce feature separation, incurring deployment costs and feature shifts that compromise CLIP's generalization ability. To address these issues, we propose CLIPXpert, a novel SF-OSDA approach that integrates two key components: an adaptive thresholding strategy and an unknown class feature filtering module. Specifically, the Box-Cox GMM-Based Adaptive Thresholding (BGAT) module dynamically determines the optimal threshold by estimating sample score distributions, balancing known class recognition and unknown class sample detection. Additionally, the Singular Value Decomposition (SVD)-Based Unknown-Class Feature Filtering (SUFF) module reduces the tendency of unknown class samples towards known classes, improving the separation between known and unknown classes. Experiments show that our source-free and training-free method outperforms state-of-the-art trained approach UOTA by 1.92% on the DomainNet dataset, achieves SOTA-comparable performance on datasets such as Office-Home, and surpasses other SF-OSDA methods. This not only validates the effectiveness of our proposed method but also highlights CLIP's strong zero-shot potential for SF-OSDA tasks.
Collaboration and Controversy Among Experts: Rumor Early Detection by Tuning a Comment Generator
Apr 05, 2025Over the past decade, social media platforms have been key in spreading rumors, leading to significant negative impacts. To counter this, the community has developed various Rumor Detection (RD) algorithms to automatically identify them using user comments as evidence. However, these RD methods often fail in the early stages of rumor propagation when only limited user comments are available, leading the community to focus on a more challenging topic named Rumor Early Detection (RED). Typically, existing RED methods learn from limited semantics in early comments. However, our preliminary experiment reveals that the RED models always perform best when the number of training and test comments is consistent and extensive. This inspires us to address the RED issue by generating more human-like comments to support this hypothesis. To implement this idea, we tune a comment generator by simulating expert collaboration and controversy and propose a new RED framework named CAMERED. Specifically, we integrate a mixture-of-expert structure into a generative language model and present a novel routing network for expert collaboration. Additionally, we synthesize a knowledgeable dataset and design an adversarial learning strategy to align the style of generated comments with real-world comments. We further integrate generated and original comments with a mutual controversy fusion module. Experimental results show that CAMERED outperforms state-of-the-art RED baseline models and generation methods, demonstrating its effectiveness.
Cogito, ergo sum: A Neurobiologically-Inspired Cognition-Memory-Growth System for Code Generation
Jan 30, 2025



Large language models based Multi Agent Systems (MAS) have demonstrated promising performance for enhancing the efficiency and accuracy of code generation tasks. However,most existing methods follow a conventional sequence of planning, coding, and debugging,which contradicts the growth-driven nature of human learning process. Additionally,the frequent information interaction between multiple agents inevitably involves high computational costs. In this paper,we propose Cogito,a neurobiologically inspired multi-agent framework to enhance the problem-solving capabilities in code generation tasks with lower cost. Specifically,Cogito adopts a reverse sequence: it first undergoes debugging, then coding,and finally planning. This approach mimics human learning and development,where knowledge is acquired progressively. Accordingly,a hippocampus-like memory module with different functions is designed to work with the pipeline to provide quick retrieval in similar tasks. Through this growth-based learning model,Cogito accumulates knowledge and cognitive skills at each stage,ultimately forming a Super Role an all capable agent to perform the code generation task. Extensive experiments against representative baselines demonstrate the superior performance and efficiency of Cogito. The code is publicly available at https://anonymous.4open.science/r/Cogito-0083.
Data-Efficient CLIP-Powered Dual-Branch Networks for Source-Free Unsupervised Domain Adaptation
Oct 21, 2024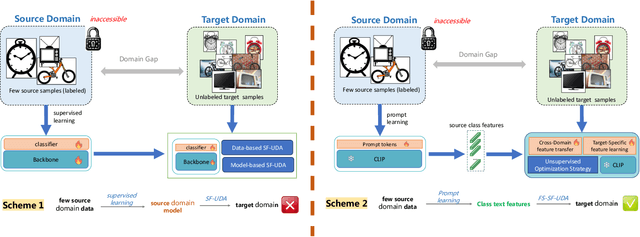
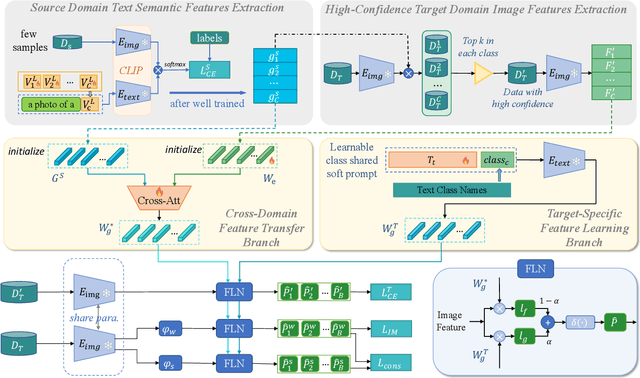
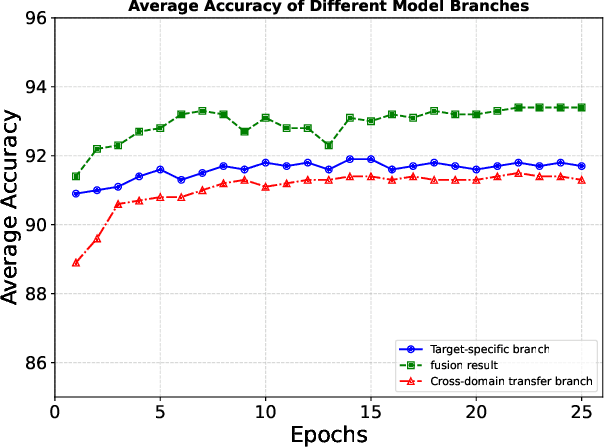
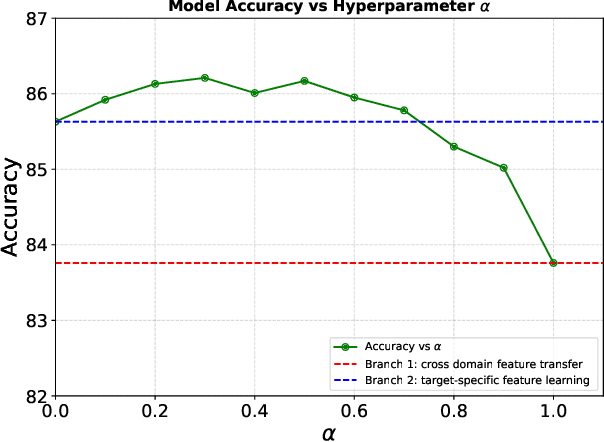
Source-Free Unsupervised Domain Adaptation (SF-UDA) aims to transfer a model's performance from a labeled source domain to an unlabeled target domain without direct access to source samples, addressing data privacy issues. However, most existing SF-UDA approaches assume the availability of abundant source domain samples, which is often impractical due to the high cost of data annotation. In this paper, we explore a more challenging scenario where direct access to source domain samples is restricted, and the source domain contains only a few samples. To tackle the dual challenges of limited source data and privacy concerns, we introduce a data-efficient, CLIP-powered dual-branch network (CDBN in short). We design a cross-modal dual-branch network that integrates source domain class semantics into the unsupervised fine-tuning of the target domain. It preserves the class information from the source domain while enhancing the model's generalization to the target domain. Additionally, we propose an unsupervised optimization strategy driven by accurate classification and diversity, which aims to retain the classification capability learned from the source domain while producing more confident and diverse predictions in the target domain. Extensive experiments across 31 transfer tasks on 7 public datasets demonstrate that our approach achieves state-of-the-art performance compared to existing methods.