 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multimodal Misinformation Detection by Replaying the Whole Story from Image Modality Perspective
Nov 09, 2025
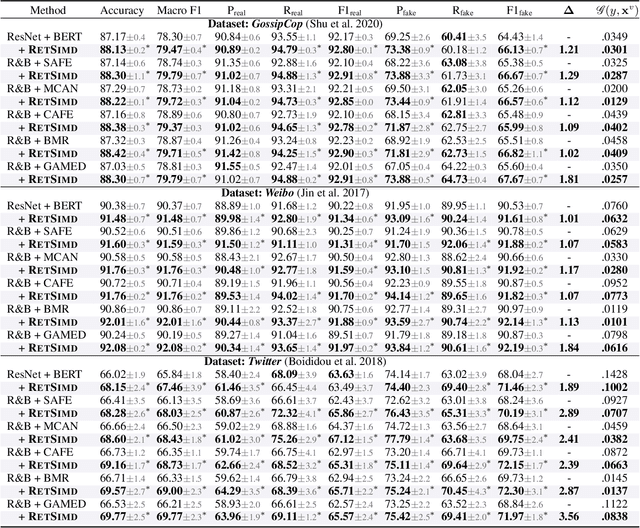
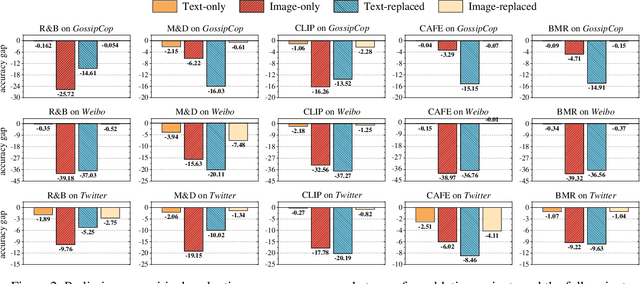
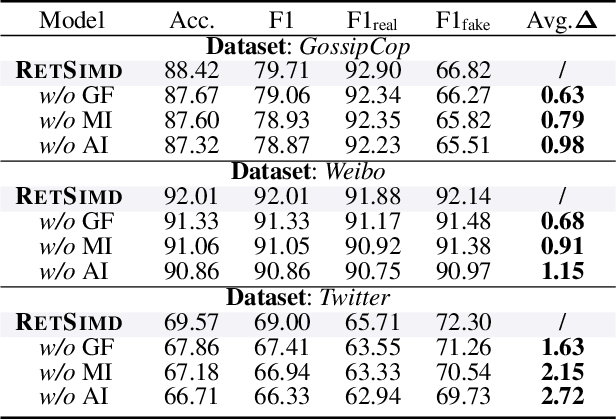
Multimodal Misinformation Detection (MMD) refers to the task of detecting social media posts involving misinformation, where the post often contains text and image modalities. However, by observing the MMD posts, we hold that the text modality may be much more informative than the image modality because the text generally describes the whole event/story of the current post but the image often presents partial scenes only. Our preliminary empirical results indicate that the image modality exactly contributes less to MMD. Upon this idea, we propose a new MMD method named RETSIMD. Specifically, we suppose that each text can be divided into several segments, and each text segment describes a partial scene that can be presented by an image. Accordingly, we split the text into a sequence of segments, and feed these segments into a pre-trained text-to-image generator to augment a sequence of images. We further incorporate two auxiliary objectives concerning text-image and image-label mutual information, and further post-train the generator over an auxiliary text-to-image generation benchmark dataset. Additionally, we propose a graph structure by defining three heuristic relationships between images, and use a graph neural network to generate the fused features. Extensive empirical results validate the effectiveness of RETSIMD.
Semi-supervised Multiscale Matching for SAR-Optical Image
Aug 11, 2025Driven by the complementary nature of optical and synthetic aperture radar (SAR) images, SAR-optical image matching has garnered significant interest. Most existing SAR-optical image matching methods aim to capture effective matching features by employing the supervision of pixel-level matched correspondences within SAR-optical image pairs, which, however, suffers from time-consuming and complex manual annotation, making it difficult to collect sufficient labeled SAR-optical image pairs. To handle this, we design a semi-supervised SAR-optical image matching pipeline that leverages both scarce labeled and abundant unlabeled image pairs and propose a semi-supervised multiscale matching for SAR-optical image matching (S2M2-SAR). Specifically, we pseudo-label those unlabeled SAR-optical image pairs with pseudo ground-truth similarity heatmaps by combining both deep and shallow level matching results, and train the matching model by employing labeled and pseudo-labeled similarity heatmaps. In addition, we introduce a cross-modal feature enhancement module trained using a cross-modality mutual independence loss, which requires no ground-truth labels. This unsupervised objective promotes the separation of modality-shared and modality-specific features by encouraging statistical independence between them, enabling effective feature disentanglement across optical and SAR modalities. To evaluate the effectiveness of S2M2-SAR, we compare it with existing competitors on benchmark datasets. Experimental results demonstrate that S2M2-SAR not only surpasses existing semi-supervised methods but also achieves performance competitive with fully supervised SOTA methods, demonstrating its efficiency and practical potential.
Robust Misinformation Detection by Visiting Potential Commonsense Conflict
Apr 30, 2025



The development of Internet technology has led to an increased prevalence of misinformation, causing severe negative effects across diverse domains. To mitigate this challenge, Misinformation Detection (MD), aiming to detect online misinformation automatically, emerges as a rapidly growing research topic in the community. In this paper, we propose a novel plug-and-play augmentation method for the MD task, namely Misinformation Detection with Potential Commonsense Conflict (MD-PCC). We take inspiration from the prior studies indicating that fake articles are more likely to involve commonsense conflict. Accordingly, we construct commonsense expressions for articles, serving to express potential commonsense conflicts inferred by the difference between extracted commonsense triplet and golden ones inferred by the well-established commonsense reasoning tool COMET. These expressions are then specified for each article as augmentation. Any specific MD methods can be then trained on those commonsense-augmented articles. Besides, we also collect a novel commonsense-oriented dataset named CoMis, whose all fake articles are caused by commonsense conflict. We integrate MD-PCC with various existing MD backbones and compare them across both 4 public benchmark datasets and CoMis. Empirical results demonstrate that MD-PCC can consistently outperform the existing MD baselines.
Collaboration and Controversy Among Experts: Rumor Early Detection by Tuning a Comment Generator
Apr 05, 2025Over the past decade, social media platforms have been key in spreading rumors, leading to significant negative impacts. To counter this, the community has developed various Rumor Detection (RD) algorithms to automatically identify them using user comments as evidence. However, these RD methods often fail in the early stages of rumor propagation when only limited user comments are available, leading the community to focus on a more challenging topic named Rumor Early Detection (RED). Typically, existing RED methods learn from limited semantics in early comments. However, our preliminary experiment reveals that the RED models always perform best when the number of training and test comments is consistent and extensive. This inspires us to address the RED issue by generating more human-like comments to support this hypothesis. To implement this idea, we tune a comment generator by simulating expert collaboration and controversy and propose a new RED framework named CAMERED. Specifically, we integrate a mixture-of-expert structure into a generative language model and present a novel routing network for expert collaboration. Additionally, we synthesize a knowledgeable dataset and design an adversarial learning strategy to align the style of generated comments with real-world comments. We further integrate generated and original comments with a mutual controversy fusion module. Experimental results show that CAMERED outperforms state-of-the-art RED baseline models and generation methods, demonstrating its effectiveness.
Why Misinformation is Created? Detecting them by Integrating Intent Features
Jul 27, 2024



Various social media platforms, e.g., Twitter and Reddit, allow people to disseminate a plethora of information more efficiently and conveniently. However, they are inevitably full of misinformation, causing damage to diverse aspects of our daily lives. To reduce the negative impact, timely identification of misinformation, namely Misinformation Detection (MD), has become an active research topic receiving widespread attention. As a complex phenomenon, the veracity of an article is influenced by various aspects. In this paper, we are inspired by the opposition of intents between misinformation and real information. Accordingly, we propose to reason the intent of articles and form the corresponding intent features to promote the veracity discrimination of article features. To achieve this, we build a hierarchy of a set of intents for both misinformation and real information by referring to the existing psychological theories, and we apply it to reason the intent of articles by progressively generating binary answers with an encoder-decoder structure. We form the corresponding intent features and integrate it with the token features to achieve more discriminative article features for MD. Upon these ideas, we suggest a novel MD method, namely Detecting Misinformation by Integrating Intent featuRes (DM-INTER). To evaluate the performance of DM-INTER, we conduct extensive experiments on benchmark MD datasets. The experimental results validate that DM-INTER can outperform the existing baseline MD methods.
Harmfully Manipulated Images Matter in Multimodal Misinformation Detection
Jul 27, 2024Nowadays, misinformation is widely spreading over various social media platforms and causes extremely negative impacts on society. To combat this issue, automatically identifying misinformation, especially those containing multimodal content, has attracted growing attention from the academic and industrial communities, and induced an active research topic named Multimodal Misinformation Detection (MMD). Typically, existing MMD methods capture the semantic correlation and inconsistency between multiple modalities, but neglect some potential clues in multimodal content. Recent studies suggest that manipulated traces of the images in articles are non-trivial clues for detecting misinformation. Meanwhile, we find that the underlying intentions behind the manipulation, e.g., harmful and harmless, also matter in MMD. Accordingly, in this work, we propose to detect misinformation by learning manipulation features that indicate whether the image has been manipulated, as well as intention features regarding the harmful and harmless intentions of the manipulation. Unfortunately, the manipulation and intention labels that make these features discriminative are unknown. To overcome the problem, we propose two weakly supervised signals as alternatives by introducing additional datasets on image manipulation detection and formulating two classification tasks as positive and unlabeled learning problems. Based on these ideas, we propose a novel MMD method, namely Harmfully Manipulated Images Matter in MMD (HAMI-M3D). Extensive experiments across three benchmark datasets can demonstrate that HAMI-M3D can consistently improve the performance of any MMD baselines.
Learning with Partial Labels from Semi-supervised Perspective
Nov 30, 2022Partial Label (PL) learning refers to the task of learning from the partially labeled data, where each training instance is ambiguously equipped with a set of candidate labels but only one is valid. Advances in the recent deep PL learning literature have shown that the deep learning paradigms, e.g., self-training, contrastive learning, or class activate values, can achieve promising performance. Inspired by the impressive success of deep Semi-Supervised (SS) learning, we transform the PL learning problem into the SS learning problem, and propose a novel PL learning method, namely Partial Label learning with Semi-supervised Perspective (PLSP). Specifically, we first form the pseudo-labeled dataset by selecting a small number of reliable pseudo-labeled instances with high-confidence prediction scores and treating the remaining instances as pseudo-unlabeled ones. Then we design a SS learning objective, consisting of a supervised loss for pseudo-labeled instances and a semantic consistency regularization for pseudo-unlabeled instances. We further introduce a complementary regularization for those non-candidate labels to constrain the model predictions on them to be as small as possible. Empirical results demonstrate that PLSP significantly outperforms the existing PL baseline methods, especially on high ambiguity levels. Code available: https://github.com/changchunli/PLSP.
Topic representation: finding more representative words in topic models
Oct 23, 2018
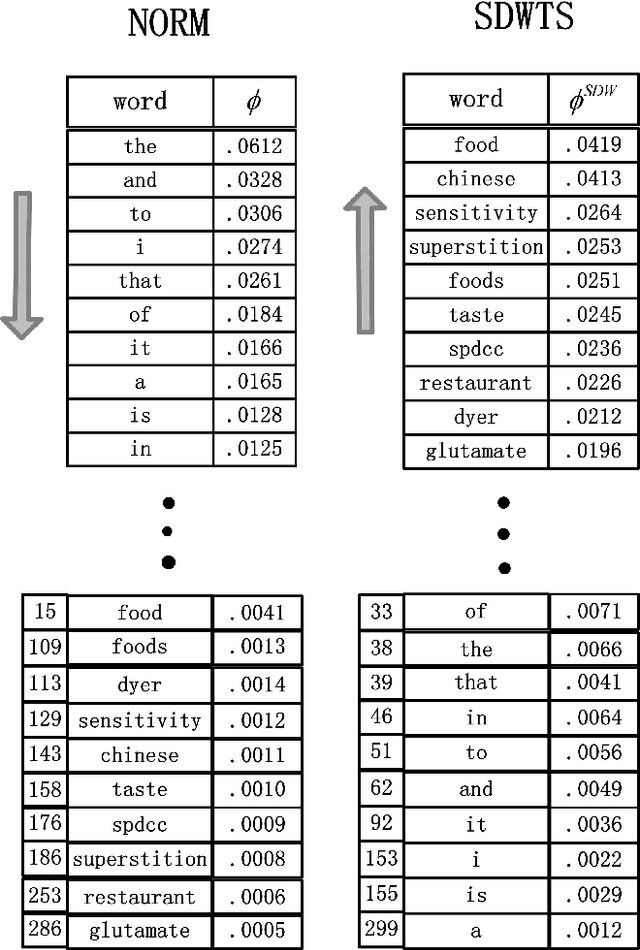

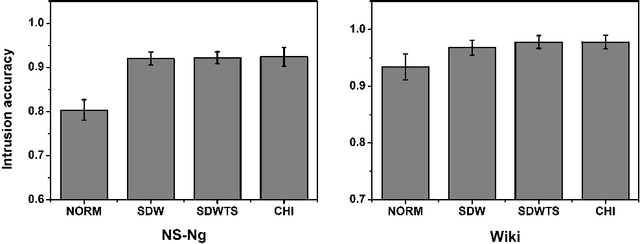
The top word list, i.e., the top-M words with highest marginal probability in a given topic, is the standard topic representation in topic models. Most of recent automatical topic labeling algorithms and popular topic quality metrics are based on it. However, we find, empirically, words in this type of top word list are not always representative. The objective of this paper is to find more representative top word lists for topics. To achieve this, we rerank the words in a given topic by further considering marginal probability on words over every other topic. The reranking list of top-M words is used to be a novel topic representation for topic models. We investigate three reranking methodologies, using (1) standard deviation weight, (2) standard deviation weight with topic size and (3) Chi Square \c{hi}2statistic selection. Experimental results on real world collections indicate that our representations can extract more representative words for topics, agreeing with human judgements.