 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCRF: A Federated Cross-domain Recommendation Method with Semantic-driven Deep Knowledge Fusion
Apr 20, 2026As user behavior data becomes increasingly scattered across different platforms, achieving cross-domain knowledge fusion while preserving privacy has become a critical issue in recommender systems. Existing PPCDR methods usually rely on overlapping users or items as a bridge, making them inapplicable to non-overlapping scenarios. They also suffer from limitations in the collaborative modeling of global and local semantics. To this end, this paper proposes a Federated Cross-domain Recommendation method with deep knowledge Fusion (FedCRF). Using textual semantics as a cross-domain bridge, FedCRF achieves cross-domain knowledge transfer via federated semantic learning under the non-overlapping scenario. Specifically, FedCRF constructs global semantic clusters on the server side to extract shared semantic information, and designs a FGSAT module on the client side to dynamically adapt to local data distributions and alleviate cross-domain distribution shift. Meanwhile, it builds a semantic graph based on textual features to learn representations that integrate both structural and semantic information, and introduces contrastive learning constraints between global and local semantic representations to enhance semantic consistency and promote deep knowledge fusion. In this framework, only item semantic representations are shared, while user interaction data remains locally stored, effectively mitigating privacy leakage risks. Experimental results on multiple real-world datasets show that FedCRF significantly outperforms existing methods in terms of Recall@20 and NDCG@20, validating its effectiveness and superiority in non-overlapping cross-domain recommendation scenarios.
HEX: Humanoid-Aligned Experts for Cross-Embodiment Whole-Body Manipulation
Apr 09, 2026Humans achieve complex manipulation through coordinated whole-body control, whereas most Vision-Language-Action (VLA) models treat robot body parts largely independently, making high-DoF humanoid control challenging and often unstable. We present HEX, a state-centric framework for coordinated manipulation on full-sized bipedal humanoid robots. HEX introduces a humanoid-aligned universal state representation for scalable learning across heterogeneous embodiments, and incorporates a Mixture-of-Experts Unified Proprioceptive Predictor to model whole-body coordination and temporal motion dynamics from large-scale multi-embodiment trajectory data. To efficiently capture temporal visual context, HEX uses lightweight history tokens to summarize past observations, avoiding repeated encoding of historical images during inference. It further employs a residual-gated fusion mechanism with a flow-matching action head to adaptively integrate visual-language cues with proprioceptive dynamics for action generation. Experiments on real-world humanoid manipulation tasks show that HEX achieves state-of-the-art performance in task success rate and generalization, particularly in fast-reaction and long-horizon scenarios.
RoboGene: Boosting VLA Pre-training via Diversity-Driven Agentic Framework for Real-World Task Generation
Feb 19, 2026The pursuit of general-purpose robotic manipulation is hindered by the scarcity of diverse, real-world interaction data. Unlike data collection from web in vision or language, robotic data collection is an active process incurring prohibitive physical costs. Consequently, automated task curation to maximize data value remains a critical yet under-explored challenge. Existing manual methods are unscalable and biased toward common tasks, while off-the-shelf foundation models often hallucinate physically infeasible instructions. To address this, we introduce RoboGene, an agentic framework designed to automate the generation of diverse, physically plausible manipulation tasks across single-arm, dual-arm, and mobile robots. RoboGene integrates three core components: diversity-driven sampling for broad task coverage, self-reflection mechanisms to enforce physical constraints, and human-in-the-loop refinement for continuous improvement. We conduct extensive quantitative analysis and large-scale real-world experiments, collecting datasets of 18k trajectories and introducing novel metrics to assess task quality, feasibility, and diversity. Results demonstrate that RoboGene significantly outperforms state-of-the-art foundation models (e.g., GPT-4o, Gemini 2.5 Pro). Furthermore, real-world experiments show that VLA models pre-trained with RoboGene achieve higher success rates and superior generalization, underscoring the importance of high-quality task generation. Our project is available at https://robogene-boost-vla.github.io.
RoboAug: One Annotation to Hundreds of Scenes via Region-Contrastive Data Augmentation for Robotic Manipulation
Feb 15, 2026Enhancing the generalization capability of robotic learning to enable robots to operate effectively in diverse, unseen scenes is a fundamental and challenging problem. Existing approaches often depend on pretraining with large-scale data collection, which is labor-intensive and time-consuming, or on semantic data augmentation techniques that necessitate an impractical assumption of flawless upstream object detection in real-world scenarios. In this work, we propose RoboAug, a novel generative data augmentation framework that significantly minimizes the reliance on large-scale pretraining and the perfect visual recognition assumption by requiring only the bounding box annotation of a single image during training. Leveraging this minimal information, RoboAug employs pre-trained generative models for precise semantic data augmentation and integrates a plug-and-play region-contrastive loss to help models focus on task-relevant regions, thereby improving generalization and boosting task success rates. We conduct extensive real-world experiments on three robots, namely UR-5e, AgileX, and Tien Kung 2.0, spanning over 35k rollouts. Empirical results demonstrate that RoboAug significantly outperforms state-of-the-art data augmentation baselines. Specifically, when evaluating generalization capabilities in unseen scenes featuring diverse combinations of backgrounds, distractors, and lighting conditions, our method achieves substantial gains over the baseline without augmentation. The success rates increase from 0.09 to 0.47 on UR-5e, from 0.16 to 0.60 on AgileX, and from 0.19 to 0.67 on Tien Kung 2.0. These results highlight the superior generalization and effectiveness of RoboAug in real-world manipulation tasks. Our project is available at https://x-roboaug.github.io/.
RoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
Larger Hausdorff Dimension in Scanning Pattern Facilitates Mamba-Based Methods in Low-Light Image Enhancement
Oct 29, 2025We propose an innovative enhancement to the Mamba framework by increasing the Hausdorff dimension of its scanning pattern through a novel Hilbert Selective Scan mechanism. This mechanism explores the feature space more effectively, capturing intricate fine-scale details and improving overall coverage. As a result, it mitigates information inconsistencies while refining spatial locality to better capture subtle local interactions without sacrificing the model's ability to handle long-range dependencies. Extensive experiments on publicly available benchmarks demonstrate that our approach significantly improves both the quantitative metrics and qualitative visual fidelity of existing Mamba-based low-light image enhancement methods, all while reducing computational resource consumption and shortening inference time. We believe that this refined strategy not only advances the state-of-the-art in low-light image enhancement but also holds promise for broader applications in fields that leverage Mamba-based techniques.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024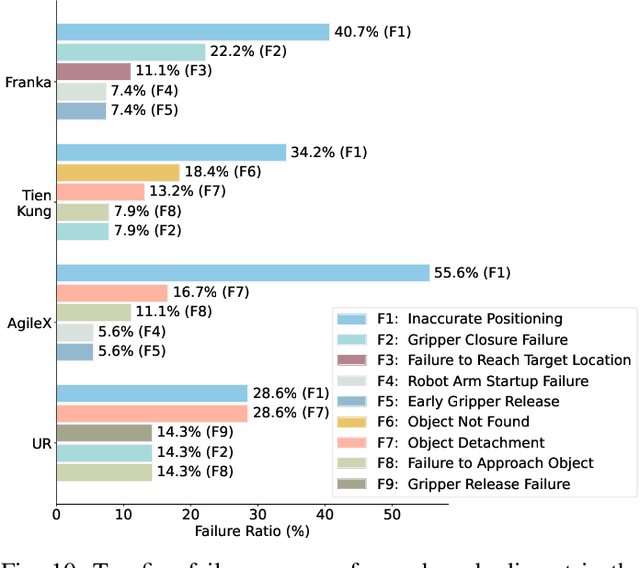
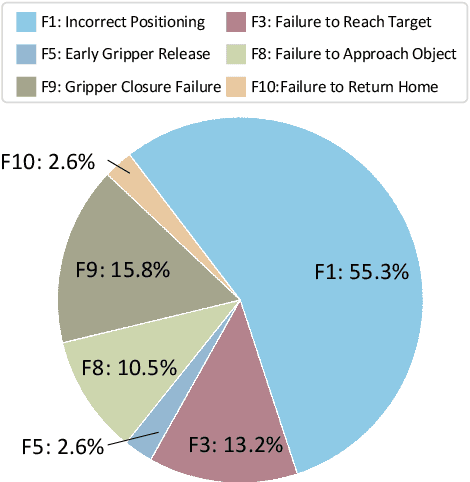
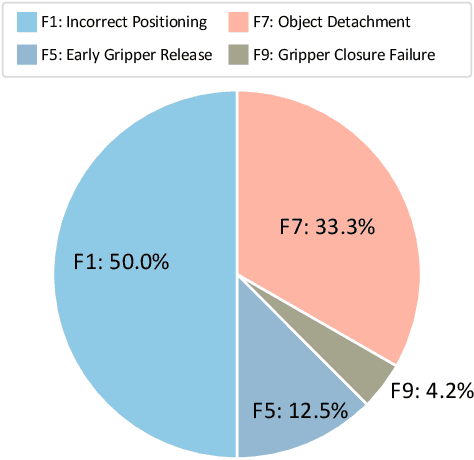
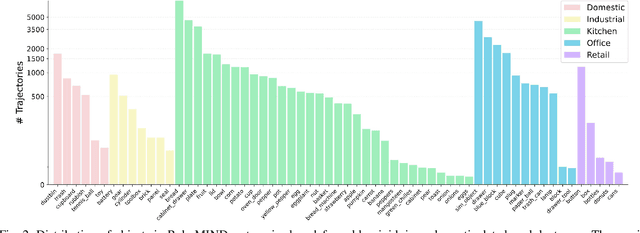
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
Unbiased and Robust: External Attention-enhanced Graph Contrastive Learning for Cross-domain Sequential Recommendation
Oct 17, 2023



Cross-domain sequential recommenders (CSRs) are gaining considerable research attention as they can capture user sequential preference by leveraging side information from multiple domains. However, these works typically follow an ideal setup, i.e., different domains obey similar data distribution, which ignores the bias brought by asymmetric interaction densities (a.k.a. the inter-domain density bias). Besides, the frequently adopted mechanism (e.g., the self-attention network) in sequence encoder only focuses on the interactions within a local view, which overlooks the global correlations between different training batches. To this end, we propose an External Attention-enhanced Graph Contrastive Learning framework, namely EA-GCL. Specifically, to remove the impact of the inter-domain density bias, an auxiliary Self-Supervised Learning (SSL) task is attached to the traditional graph encoder under a multi-task learning manner. To robustly capture users' behavioral patterns, we develop an external attention-based sequence encoder that contains an MLP-based memory-sharing structure. Unlike the self-attention mechanism, such a structure can effectively alleviate the bias interference from the batch-based training scheme. Extensive experiments on two real-world datasets demonstrate that EA-GCL outperforms several state-of-the-art baselines on CSR tasks. The source codes and relevant datasets are available at https://github.com/HoupingY/EA-GCL.
Automated Prompting for Non-overlapping Cross-domain Sequential Recommendation
Apr 09, 2023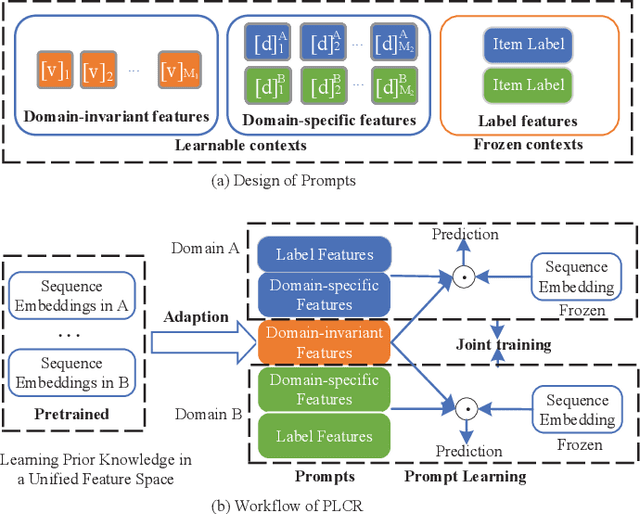
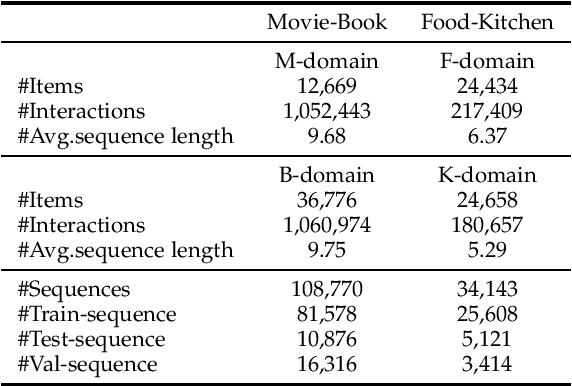
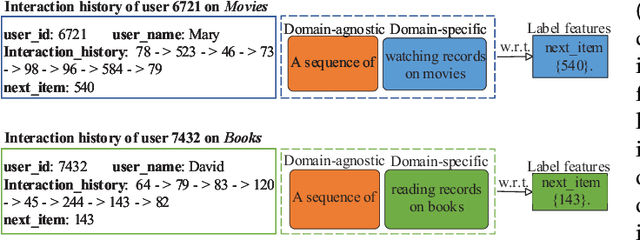
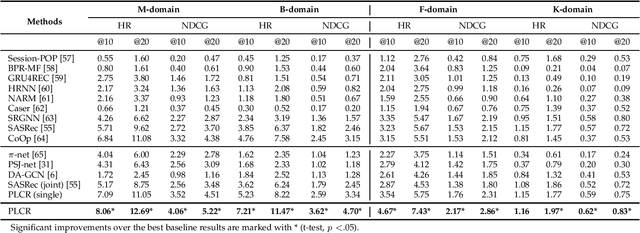
Cross-domain Recommendation (CR) has been extensively studied in recent years to alleviate the data sparsity issue in recommender systems by utilizing different domain information. In this work, we focus on the more general Non-overlapping Cross-domain Sequential Recommendation (NCSR) scenario. NCSR is challenging because there are no overlapped entities (e.g., users and items) between domains, and there is only users' implicit feedback and no content information. Previous CR methods cannot solve NCSR well, since (1) they either need extra content to align domains or need explicit domain alignment constraints to reduce the domain discrepancy from domain-invariant features, (2) they pay more attention to users' explicit feedback (i.e., users' rating data) and cannot well capture their sequential interaction patterns, (3) they usually do a single-target cross-domain recommendation task and seldom investigate the dual-target ones. Considering the above challenges, we propose Prompt Learning-based Cross-domain Recommender (PLCR), an automated prompting-based recommendation framework for the NCSR task. Specifically, to address the challenge (1), PLCR resorts to learning domain-invariant and domain-specific representations via its prompt learning component, where the domain alignment constraint is discarded. For challenges (2) and (3), PLCR introduces a pre-trained sequence encoder to learn users' sequential interaction patterns, and conducts a dual-learning target with a separation constraint to enhance recommendations in both domains. Our empirical study on two sub-collections of Amazon demonstrates the advance of PLCR compared with some related SOTA methods.
Towards Lightweight Cross-domain Sequential Recommendation via External Attention-enhanced Graph Convolution Network
Feb 07, 2023Cross-domain Sequential Recommendation (CSR) is an emerging yet challenging task that depicts the evolution of behavior patterns for overlapped users by modeling their interactions from multiple domains. Existing studies on CSR mainly focus on using composite or in-depth structures that achieve significant improvement in accuracy but bring a huge burden to the model training. Moreover, to learn the user-specific sequence representations, existing works usually adopt the global relevance weighting strategy (e.g., self-attention mechanism), which has quadratic computational complexity. In this work, we introduce a lightweight external attention-enhanced GCN-based framework to solve the above challenges, namely LEA-GCN. Specifically, by only keeping the neighborhood aggregation component and using the Single-Layer Aggregating Protocol (SLAP), our lightweight GCN encoder performs more efficiently to capture the collaborative filtering signals of the items from both domains. To further alleviate the framework structure and aggregate the user-specific sequential pattern, we devise a novel dual-channel External Attention (EA) component, which calculates the correlation among all items via a lightweight linear structure. Extensive experiments are conducted on two real-world datasets, demonstrating that LEA-GCN requires a smaller volume and less training time without affecting the accuracy compared with several state-of-the-art methods.