 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspect-Based Sentiment Analysis with Explicit Sentiment Augmentations
Dec 18, 2023

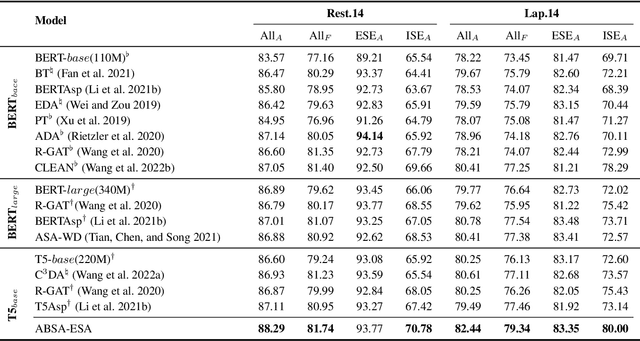
Aspect-based sentiment analysis (ABSA), a fine-grained sentiment classification task, has received much attention recently. Many works investigate sentiment information through opinion words, such as ''good'' and ''bad''. However, implicit sentiment widely exists in the ABSA dataset, which refers to the sentence containing no distinct opinion words but still expresses sentiment to the aspect term. To deal with implicit sentiment, this paper proposes an ABSA method that integrates explicit sentiment augmentations. And we propose an ABSA-specific augmentation method to create such augmentations. Specifically, we post-trains T5 by rule-based data. We employ Syntax Distance Weighting and Unlikelihood Contrastive Regularization in the training procedure to guide the model to generate an explicit sentiment. Meanwhile, we utilize the Constrained Beam Search to ensure the augmentation sentence contains the aspect terms. We test ABSA-ESA on two of the most popular benchmarks of ABSA. The results show that ABSA-ESA outperforms the SOTA baselines on implicit and explicit sentiment accuracy.
Learning with Partial Labels from Semi-supervised Perspective
Nov 30, 2022Partial Label (PL) learning refers to the task of learning from the partially labeled data, where each training instance is ambiguously equipped with a set of candidate labels but only one is valid. Advances in the recent deep PL learning literature have shown that the deep learning paradigms, e.g., self-training, contrastive learning, or class activate values, can achieve promising performance. Inspired by the impressive success of deep Semi-Supervised (SS) learning, we transform the PL learning problem into the SS learning problem, and propose a novel PL learning method, namely Partial Label learning with Semi-supervised Perspective (PLSP). Specifically, we first form the pseudo-labeled dataset by selecting a small number of reliable pseudo-labeled instances with high-confidence prediction scores and treating the remaining instances as pseudo-unlabeled ones. Then we design a SS learning objective, consisting of a supervised loss for pseudo-labeled instances and a semantic consistency regularization for pseudo-unlabeled instances. We further introduce a complementary regularization for those non-candidate labels to constrain the model predictions on them to be as small as possible. Empirical results demonstrate that PLSP significantly outperforms the existing PL baseline methods, especially on high ambiguity levels. Code available: https://github.com/changchunli/PLSP.
Weakly Supervised Prototype Topic Model with Discriminative Seed Words: Modifying the Category Prior by Self-exploring Supervised Signals
Nov 20, 2021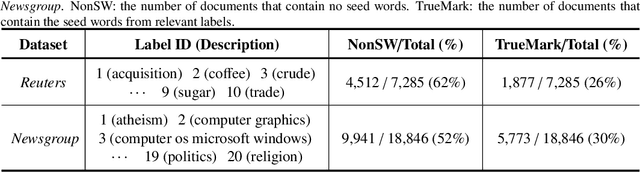

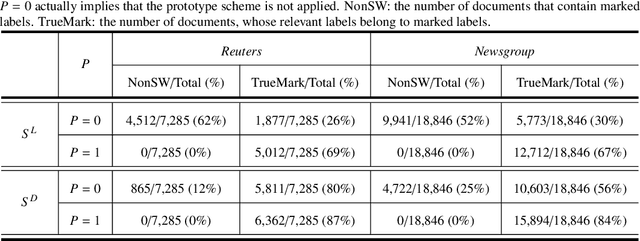
Dataless text classification, i.e., a new paradigm of weakly supervised learning, refers to the task of learning with unlabeled documents and a few predefined representative words of categories, known as seed words. The recent generative dataless methods construct document-specific category priors by using seed word occurrences only, however, such category priors often contain very limited and even noisy supervised signals. To remedy this problem, in this paper we propose a novel formulation of category prior. First, for each document, we consider its label membership degree by not only counting seed word occurrences, but also using a novel prototype scheme, which captures pseudo-nearest neighboring categories. Second, for each label, we consider its frequency prior knowledge of the corpus, which is also a discriminative knowledge for classification. By incorporating the proposed category prior into the previous generative dataless method, we suggest a novel generative dataless method, namely Weakly Supervised Prototype Topic Model (WSPTM). The experimental results on real-world datasets demonstrate that WSPTM outperforms the existing baseline methods.
Variational Wasserstein Barycenters with c-Cyclical Monotonicity
Oct 22, 2021
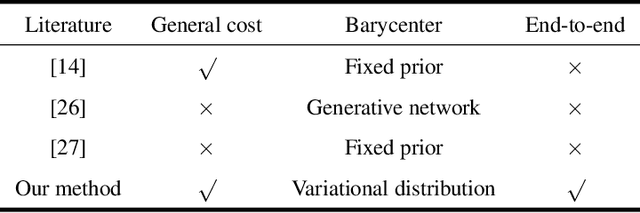

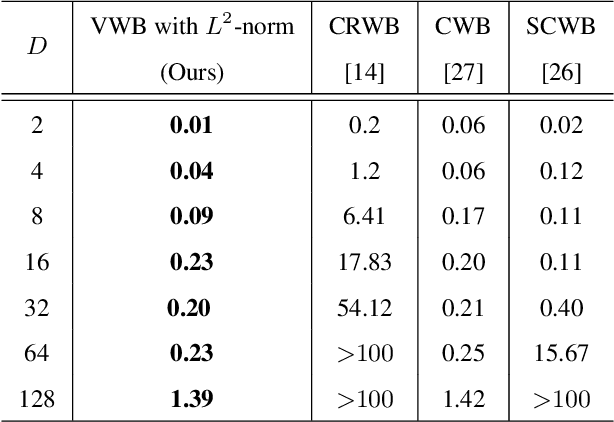
Wasserstein barycenter, built on the theory of optimal transport, provides a powerful framework to aggregate probability distributions, and it has increasingly attracted great attention within the machine learning community. However, it suffers from severe computational burden, especially for high dimensional and continuous settings. To this end, we develop a novel continuous approximation method for the Wasserstein barycenters problem given sample access to the input distributions. The basic idea is to introduce a variational distribution as the approximation of the true continuous barycenter, so as to frame the barycenters computation problem as an optimization problem, where parameters of the variational distribution adjust the proxy distribution to be similar to the barycenter. Leveraging the variational distribution, we construct a tractable dual formulation for the regularized Wasserstein barycenter problem with c-cyclical monotonicity, which can be efficiently solved by stochastic optimization. We provide theoretical analysis on convergence and demonstrate the practical effectiveness of our method on real applications of subset posterior aggregation and synthetic data.
Cross-Channel Correlation Preserved Three-Stream Lightweight CNNs for Demosaicking
Aug 21, 2019


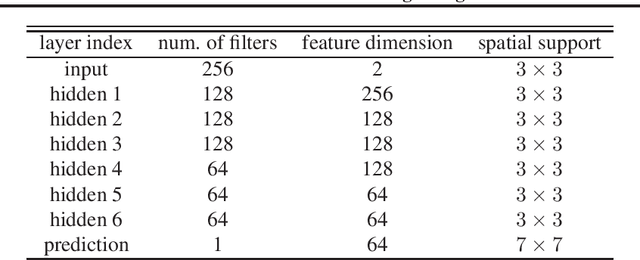
Demosaicking is a procedure to reconstruct full RGB images from Color Filter Array (CFA) samples, none of which has all color components available. Recent deep Convolutional Neural Networks (CNN) based models have obtained state of the art accuracy on benchmark datasets. However, due to the sequential feature extraction manner of CNNs, deep demosaicking models may be over slow for daily use cameras. In this paper, we decouple deep sequential demosaicking to three-stream lightweight networks, which restore the green channel, the green-red difference plane and the green-blue difference plane respectively. This strategy allows independent offline training and parallel online estimation, whilst preserving the intrinsic cross-channel correlation of natural images. Moreover, this allows designing each stream according to the various restoration difficulty of each channel. As validated by extensive experiments, our method achieves top accuracy at fast speed. Source code will be released along with paper publication.
Topic representation: finding more representative words in topic models
Oct 23, 2018
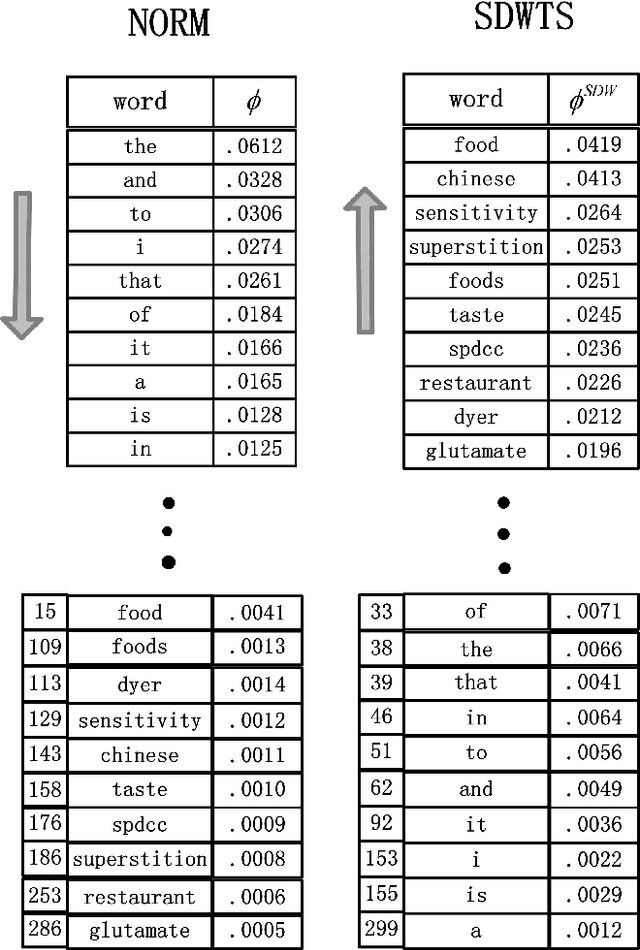

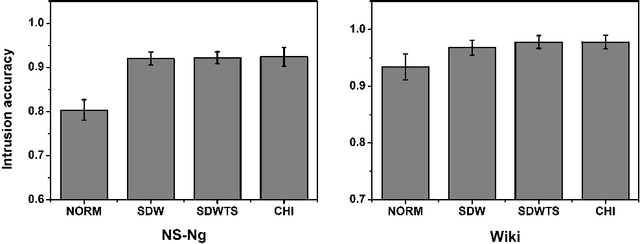
The top word list, i.e., the top-M words with highest marginal probability in a given topic, is the standard topic representation in topic models. Most of recent automatical topic labeling algorithms and popular topic quality metrics are based on it. However, we find, empirically, words in this type of top word list are not always representative. The objective of this paper is to find more representative top word lists for topics. To achieve this, we rerank the words in a given topic by further considering marginal probability on words over every other topic. The reranking list of top-M words is used to be a novel topic representation for topic models. We investigate three reranking methodologies, using (1) standard deviation weight, (2) standard deviation weight with topic size and (3) Chi Square \c{hi}2statistic selection. Experimental results on real world collections indicate that our representations can extract more representative words for topics, agreeing with human judgements.
Low Cost Edge Sensing for High Quality Demosaicking
Jun 05, 2018
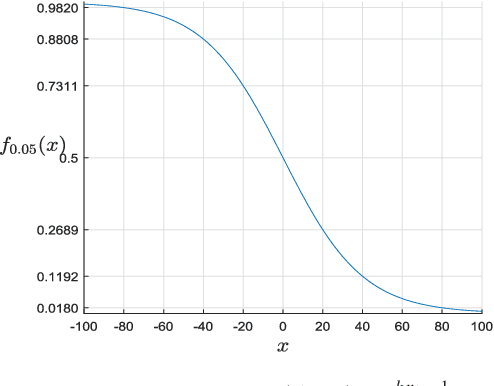
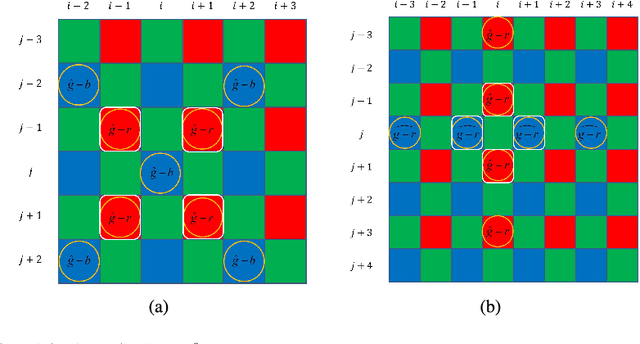
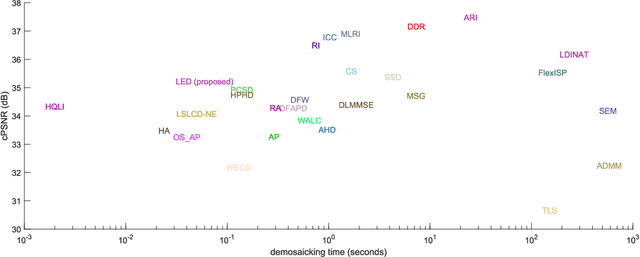
Digital cameras that use Color Filter Arrays (CFA) entail a demosaicking procedure to form full RGB images. As today's camera users generally require images to be viewed instantly, demosaicking algorithms for real applications must be fast. Moreover, the associated cost should be lower than the cost saved by using CFA. For this purpose, we revisit the classical Hamilton-Adams (HA) algorithm, which outperforms many sophisticated techniques in both speed and accuracy. Inspired by HA's strength and weakness, we design a very low cost edge sensing scheme. Briefly, it guides demosaicking by a logistic functional of the difference between directional variations. We extensively compare our algorithm with 28 demosaicking algorithms by running their open source codes on benchmark datasets. Compared to methods of similar computational cost, our method achieves substantially higher accuracy, Whereas compared to methods of similar accuracy, our method has significantly lower cost. Moreover, on test images of currently popular resolution, the quality of our algorithm is comparable to top performers, whereas its speed is tens of times faster.