 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Representation Learning via Flow Matching
Feb 05, 2026Disentangled representation learning aims to capture the underlying explanatory factors of observed data, enabling a principled understanding of the data-generating process. Recent advances in generative modeling have introduced new paradigms for learning such representations. However, existing diffusion-based methods encourage factor independence via inductive biases, yet frequently lack strong semantic alignment. In this work, we propose a flow matching-based framework for disentangled representation learning, which casts disentanglement as learning factor-conditioned flows in a compact latent space. To enforce explicit semantic alignment, we introduce a non-overlap (orthogonality) regularizer that suppresses cross-factor interference and reduces information leakage between factors. Extensive experiments across multiple datasets demonstrate consistent improvements over representative baselines, yielding higher disentanglement scores as well as improved controllability and sample fidelity.
Enhancing Multimodal Misinformation Detection by Replaying the Whole Story from Image Modality Perspective
Nov 09, 2025
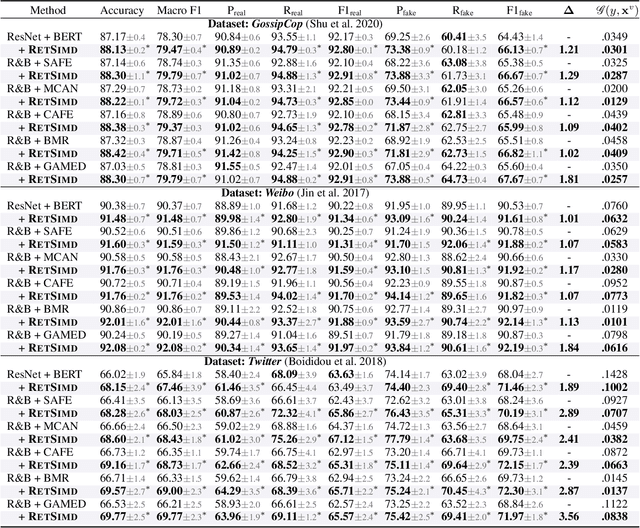
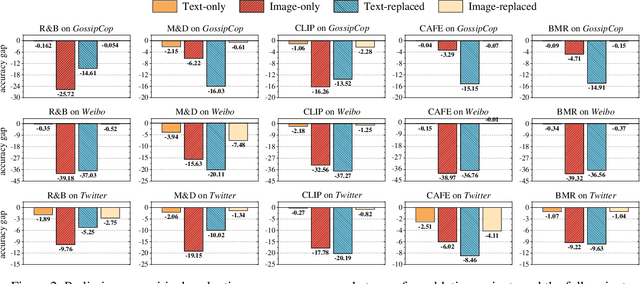
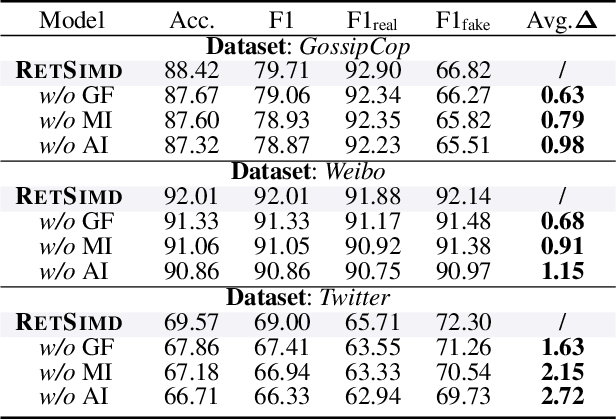
Multimodal Misinformation Detection (MMD) refers to the task of detecting social media posts involving misinformation, where the post often contains text and image modalities. However, by observing the MMD posts, we hold that the text modality may be much more informative than the image modality because the text generally describes the whole event/story of the current post but the image often presents partial scenes only. Our preliminary empirical results indicate that the image modality exactly contributes less to MMD. Upon this idea, we propose a new MMD method named RETSIMD. Specifically, we suppose that each text can be divided into several segments, and each text segment describes a partial scene that can be presented by an image. Accordingly, we split the text into a sequence of segments, and feed these segments into a pre-trained text-to-image generator to augment a sequence of images. We further incorporate two auxiliary objectives concerning text-image and image-label mutual information, and further post-train the generator over an auxiliary text-to-image generation benchmark dataset. Additionally, we propose a graph structure by defining three heuristic relationships between images, and use a graph neural network to generate the fused features. Extensive empirical results validate the effectiveness of RETSIMD.
Weakly Supervised Fine-grained Span-Level Framework for Chinese Radiology Report Quality Assurance
Aug 12, 2025Quality Assurance (QA) for radiology reports refers to judging whether the junior reports (written by junior doctors) are qualified. The QA scores of one junior report are given by the senior doctor(s) after reviewing the image and junior report. This process requires intensive labor costs for senior doctors. Additionally, the QA scores may be inaccurate for reasons like diagnosis bias, the ability of senior doctors, and so on. To address this issue, we propose a Span-level Quality Assurance EvaluaTOR (Sqator) to mark QA scores automatically. Unlike the common document-level semantic comparison method, we try to analyze the semantic difference by exploring more fine-grained text spans. Unlike the common document-level semantic comparison method, we try to analyze the semantic difference by exploring more fine-grained text spans. Specifically, Sqator measures QA scores by measuring the importance of revised spans between junior and senior reports, and outputs the final QA scores by merging all revised span scores. We evaluate Sqator using a collection of 12,013 radiology reports. Experimental results show that Sqator can achieve competitive QA scores. Moreover, the importance scores of revised spans can be also consistent with the judgments of senior doctors.
Robust Misinformation Detection by Visiting Potential Commonsense Conflict
Apr 30, 2025



The development of Internet technology has led to an increased prevalence of misinformation, causing severe negative effects across diverse domains. To mitigate this challenge, Misinformation Detection (MD), aiming to detect online misinformation automatically, emerges as a rapidly growing research topic in the community. In this paper, we propose a novel plug-and-play augmentation method for the MD task, namely Misinformation Detection with Potential Commonsense Conflict (MD-PCC). We take inspiration from the prior studies indicating that fake articles are more likely to involve commonsense conflict. Accordingly, we construct commonsense expressions for articles, serving to express potential commonsense conflicts inferred by the difference between extracted commonsense triplet and golden ones inferred by the well-established commonsense reasoning tool COMET. These expressions are then specified for each article as augmentation. Any specific MD methods can be then trained on those commonsense-augmented articles. Besides, we also collect a novel commonsense-oriented dataset named CoMis, whose all fake articles are caused by commonsense conflict. We integrate MD-PCC with various existing MD backbones and compare them across both 4 public benchmark datasets and CoMis. Empirical results demonstrate that MD-PCC can consistently outperform the existing MD baselines.
Collaboration and Controversy Among Experts: Rumor Early Detection by Tuning a Comment Generator
Apr 05, 2025Over the past decade, social media platforms have been key in spreading rumors, leading to significant negative impacts. To counter this, the community has developed various Rumor Detection (RD) algorithms to automatically identify them using user comments as evidence. However, these RD methods often fail in the early stages of rumor propagation when only limited user comments are available, leading the community to focus on a more challenging topic named Rumor Early Detection (RED). Typically, existing RED methods learn from limited semantics in early comments. However, our preliminary experiment reveals that the RED models always perform best when the number of training and test comments is consistent and extensive. This inspires us to address the RED issue by generating more human-like comments to support this hypothesis. To implement this idea, we tune a comment generator by simulating expert collaboration and controversy and propose a new RED framework named CAMERED. Specifically, we integrate a mixture-of-expert structure into a generative language model and present a novel routing network for expert collaboration. Additionally, we synthesize a knowledgeable dataset and design an adversarial learning strategy to align the style of generated comments with real-world comments. We further integrate generated and original comments with a mutual controversy fusion module. Experimental results show that CAMERED outperforms state-of-the-art RED baseline models and generation methods, demonstrating its effectiveness.
Dual-level Mixup for Graph Few-shot Learning with Fewer Tasks
Feb 19, 2025



Graph neural networks have been demonstrated as a powerful paradigm for effectively learning graph-structured data on the web and mining content from it.Current leading graph models require a large number of labeled samples for training, which unavoidably leads to overfitting in few-shot scenarios. Recent research has sought to alleviate this issue by simultaneously leveraging graph learning and meta-learning paradigms. However, these graph meta-learning models assume the availability of numerous meta-training tasks to learn transferable meta-knowledge. Such assumption may not be feasible in the real world due to the difficulty of constructing tasks and the substantial costs involved. Therefore, we propose a SiMple yet effectIve approach for graph few-shot Learning with fEwer tasks, named SMILE. We introduce a dual-level mixup strategy, encompassing both within-task and across-task mixup, to simultaneously enrich the available nodes and tasks in meta-learning. Moreover, we explicitly leverage the prior information provided by the node degrees in the graph to encode expressive node representations. Theoretically, we demonstrate that SMILE can enhance the model generalization ability. Empirically, SMILE consistently outperforms other competitive models by a large margin across all evaluated datasets with in-domain and cross-domain settings. Our anonymous code can be found here.
A Simple Graph Contrastive Learning Framework for Short Text Classification
Jan 16, 2025



Short text classification has gained significant attention in the information age due to its prevalence and real-world applications. Recent advancements in graph learning combined with contrastive learning have shown promising results in addressing the challenges of semantic sparsity and limited labeled data in short text classification. However, existing models have certain limitations. They rely on explicit data augmentation techniques to generate contrastive views, resulting in semantic corruption and noise. Additionally, these models only focus on learning the intrinsic consistency between the generated views, neglecting valuable discriminative information from other potential views. To address these issues, we propose a Simple graph contrastive learning framework for Short Text Classification (SimSTC). Our approach involves performing graph learning on multiple text-related component graphs to obtain multi-view text embeddings. Subsequently, we directly apply contrastive learning on these embeddings. Notably, our method eliminates the need for data augmentation operations to generate contrastive views while still leveraging the benefits of multi-view contrastive learning. Despite its simplicity, our model achieves outstanding performance, surpassing large language models on various datasets.
Enhancing Unsupervised Graph Few-shot Learning via Set Functions and Optimal Transport
Jan 10, 2025



Graph few-shot learning has garnered significant attention for its ability to rapidly adapt to downstream tasks with limited labeled data, sparking considerable interest among researchers. Recent advancements in graph few-shot learning models have exhibited superior performance across diverse applications. Despite their successes, several limitations still exist. First, existing models in the meta-training phase predominantly focus on instance-level features within tasks, neglecting crucial set-level features essential for distinguishing between different categories. Second, these models often utilize query sets directly on classifiers trained with support sets containing only a few labeled examples, overlooking potential distribution shifts between these sets and leading to suboptimal performance. Finally, previous models typically require necessitate abundant labeled data from base classes to extract transferable knowledge, which is typically infeasible in real-world scenarios. To address these issues, we propose a novel model named STAR, which leverages Set funcTions and optimAl tRansport for enhancing unsupervised graph few-shot learning. Specifically, STAR utilizes expressive set functions to obtain set-level features in an unsupervised manner and employs optimal transport principles to align the distributions of support and query sets, thereby mitigating distribution shift effects. Theoretical analysis demonstrates that STAR can capture more task-relevant information and enhance generalization capabilities. Empirically, extensive experiments across multiple datasets validate the effectiveness of STAR. Our code can be found here.
Learning Causal Transition Matrix for Instance-dependent Label Noise
Dec 18, 2024



Noisy labels are both inevitable and problematic in machine learning methods, as they negatively impact models' generalization ability by causing overfitting. In the context of learning with noise, the transition matrix plays a crucial role in the design of statistically consistent algorithms. However, the transition matrix is often considered unidentifiable. One strand of methods typically addresses this problem by assuming that the transition matrix is instance-independent; that is, the probability of mislabeling a particular instance is not influenced by its characteristics or attributes. This assumption is clearly invalid in complex real-world scenarios. To better understand the transition relationship and relax this assumption, we propose to study the data generation process of noisy labels from a causal perspective. We discover that an unobservable latent variable can affect either the instance itself, the label annotation procedure, or both, which complicates the identification of the transition matrix. To address various scenarios, we have unified these observations within a new causal graph. In this graph, the input instance is divided into a noise-resistant component and a noise-sensitive component based on whether they are affected by the latent variable. These two components contribute to identifying the ``causal transition matrix'', which approximates the true transition matrix with theoretical guarantee. In line with this, we have designed a novel training framework that explicitly models this causal relationship and, as a result, achieves a more accurate model for inferring the clean label.
Forming Auxiliary High-confident Instance-level Loss to Promote Learning from Label Proportions
Nov 15, 2024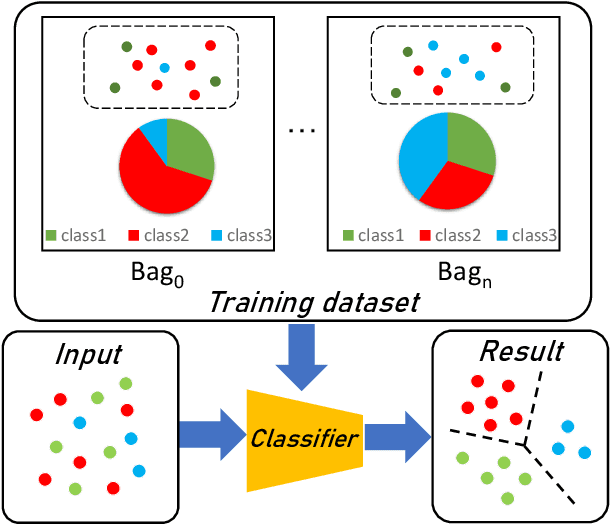
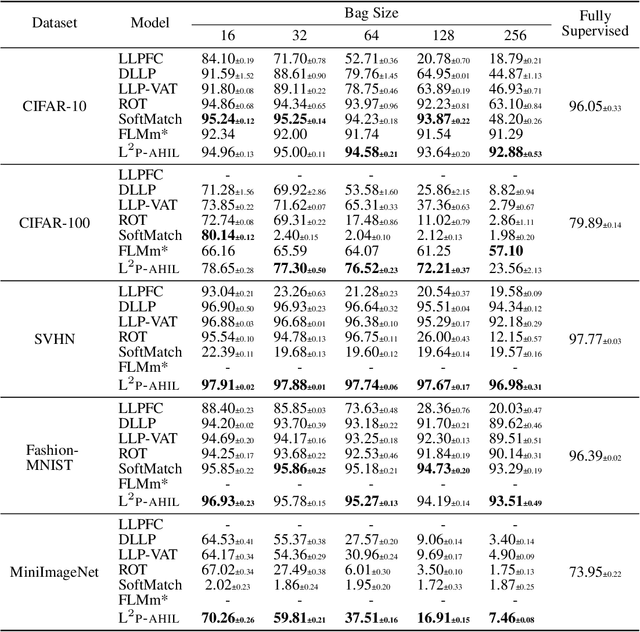

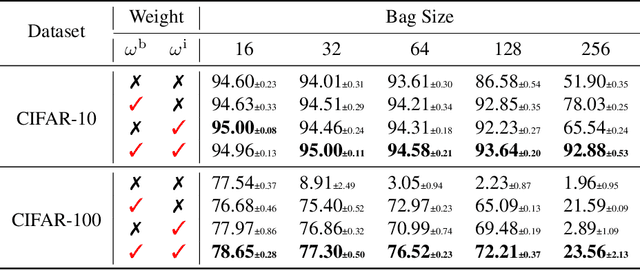
Learning from label proportions (LLP), i.e., a challenging weakly-supervised learning task, aims to train a classifier by using bags of instances and the proportions of classes within bags, rather than annotated labels for each instance. Beyond the traditional bag-level loss, the mainstream methodology of LLP is to incorporate an auxiliary instance-level loss with pseudo-labels formed by predictions. Unfortunately, we empirically observed that the pseudo-labels are are often inaccurate due to over-smoothing, especially for the scenarios with large bag sizes, hurting the classifier induction. To alleviate this problem, we suggest a novel LLP method, namely Learning from Label Proportions with Auxiliary High-confident Instance-level Loss (L^2P-AHIL). Specifically, we propose a dual entropy-based weight (DEW) method to adaptively measure the confidences of pseudo-labels. It simultaneously emphasizes accurate predictions at the bag level and avoids overly smoothed predictions. We then form high-confident instance-level loss with DEW, and jointly optimize it with the bag-level loss in a self-training manner. The experimental results on benchmark datasets show that L^2P-AHIL can surpass the existing baseline methods, and the performance gain can be more significant as the bag size increases.