 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Label Proportions with Dual-proportion Constraints
Mar 22, 2026Learning from Label Proportions (LLP) is a weakly supervised problem in which the training data comprise bags, that is, groups of instances, each annotated only with bag-level class label proportions, and the objective is to learn a classifier that predicts instance-level labels. This setting is widely applicable when privacy constraints limit access to instance-level annotations or when fine-grained labeling is costly or impractical. In this work, we introduce a method that leverages Dual proportion Constraints (LLP-DC) during training, enforcing them at both the bag and instance levels. Specifically, the bag-level training aligns the mean prediction with the given proportion, and the instance-level training aligns hard pseudo-labels that satisfy the proportion constraint, where a minimum-cost maximum-flow algorithm is used to generate hard pseudo-labels. Extensive experimental results across various benchmark datasets empirically validate that LLP-DC consistently improves over previous LLP methods across datasets and bag sizes. The code is publicly available at https://github.com/TianhaoMa5/CV PR2026_Findings_LLP_DC.
S-Crescendo: A Nested Transformer Weaving Framework for Scalable Nonlinear System in S-Domain Representation
May 17, 2025Simulation of high-order nonlinear system requires extensive computational resources, especially in modern VLSI backend design where bifurcation-induced instability and chaos-like transient behaviors pose challenges. We present S-Crescendo - a nested transformer weaving framework that synergizes S-domain with neural operators for scalable time-domain prediction in high-order nonlinear networks, alleviating the computational bottlenecks of conventional solvers via Newton-Raphson method. By leveraging the partial-fraction decomposition of an n-th order transfer function into first-order modal terms with repeated poles and residues, our method bypasses the conventional Jacobian matrix-based iterations and efficiently reduces computational complexity from cubic $O(n^3)$ to linear $O(n)$.The proposed architecture seamlessly integrates an S-domain encoder with an attention-based correction operator to simultaneously isolate dominant response and adaptively capture higher-order non-linearities. Validated on order-1 to order-10 networks, our method achieves up to 0.99 test-set ($R^2$) accuracy against HSPICE golden waveforms and accelerates simulation by up to 18(X), providing a scalable, physics-aware framework for high-dimensional nonlinear modeling.
Fusing Global and Local: Transformer-CNN Synergy for Next-Gen Current Estimation
Apr 08, 2025This paper presents a hybrid model combining Transformer and CNN for predicting the current waveform in signal lines. Unlike traditional approaches such as current source models, driver linear representations, waveform functional fitting, or equivalent load capacitance methods, our model does not rely on fixed simplified models of standard-cell drivers or RC loads. Instead, it replaces the complex Newton iteration process used in traditional SPICE simulations, leveraging the powerful sequence modeling capabilities of the Transformer framework to directly predict current responses without iterative solving steps. The hybrid architecture effectively integrates the global feature-capturing ability of Transformers with the local feature extraction advantages of CNNs, significantly improving the accuracy of current waveform predictions. Experimental results demonstrate that, compared to traditional SPICE simulations, the proposed algorithm achieves an error of only 0.0098. These results highlight the algorithm's superior capabilities in predicting signal line current waveforms, timing analysis, and power evaluation, making it suitable for a wide range of technology nodes, from 40nm to 3nm.
Forming Auxiliary High-confident Instance-level Loss to Promote Learning from Label Proportions
Nov 15, 2024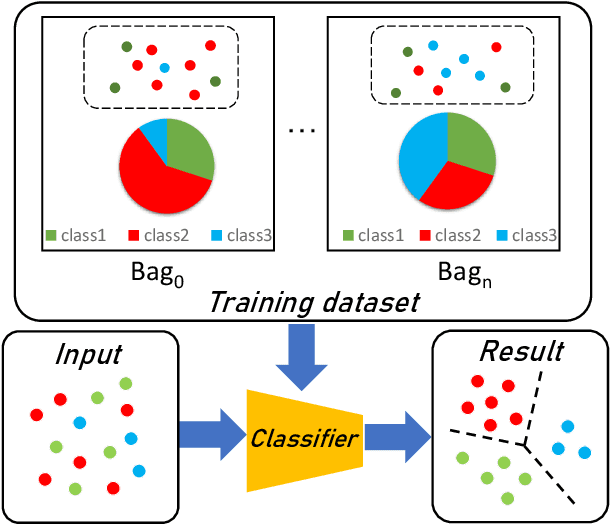
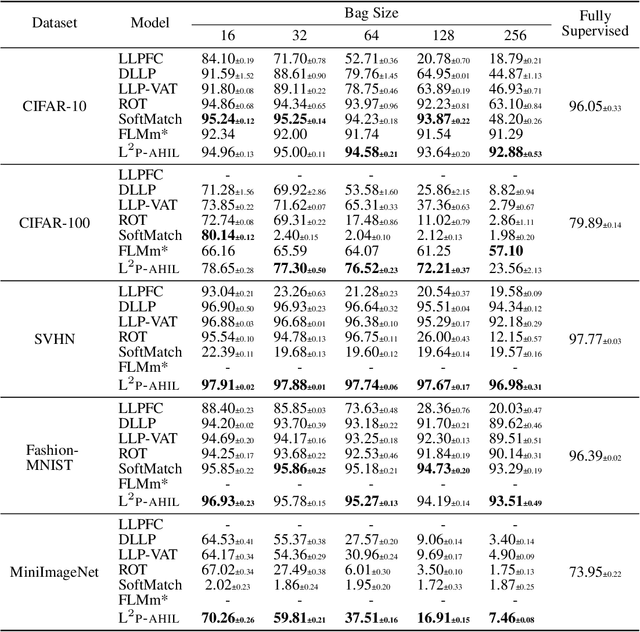

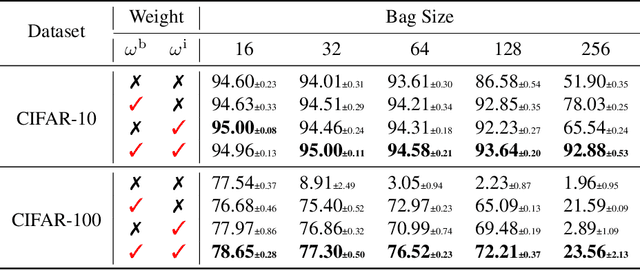
Learning from label proportions (LLP), i.e., a challenging weakly-supervised learning task, aims to train a classifier by using bags of instances and the proportions of classes within bags, rather than annotated labels for each instance. Beyond the traditional bag-level loss, the mainstream methodology of LLP is to incorporate an auxiliary instance-level loss with pseudo-labels formed by predictions. Unfortunately, we empirically observed that the pseudo-labels are are often inaccurate due to over-smoothing, especially for the scenarios with large bag sizes, hurting the classifier induction. To alleviate this problem, we suggest a novel LLP method, namely Learning from Label Proportions with Auxiliary High-confident Instance-level Loss (L^2P-AHIL). Specifically, we propose a dual entropy-based weight (DEW) method to adaptively measure the confidences of pseudo-labels. It simultaneously emphasizes accurate predictions at the bag level and avoids overly smoothed predictions. We then form high-confident instance-level loss with DEW, and jointly optimize it with the bag-level loss in a self-training manner. The experimental results on benchmark datasets show that L^2P-AHIL can surpass the existing baseline methods, and the performance gain can be more significant as the bag size increases.
Federated Learning for Internet of Things: A Federated Learning Framework for On-device Anomaly Data Detection
Jun 15, 2021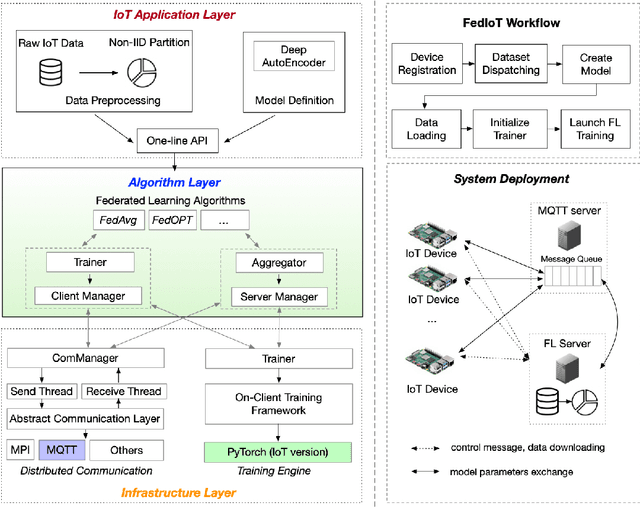
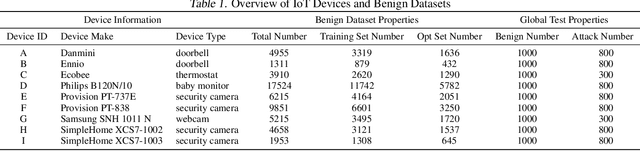

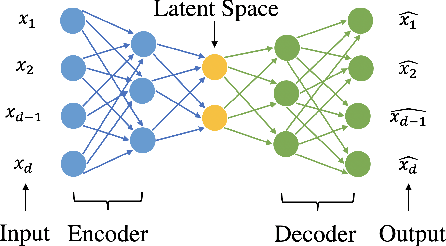
Federated learning can be a promising solution for enabling IoT cybersecurity (i.e., anomaly detection in the IoT environment) while preserving data privacy and mitigating the high communication/storage overhead (e.g., high-frequency data from time-series sensors) of centralized over-the-cloud approaches. In this paper, to further push forward this direction with a comprehensive study in both algorithm and system design, we build FedIoT platform that contains a synthesized dataset using N-BaIoT, FedDetect algorithm, and a system design for IoT devices. Furthermore, the proposed FedDetect learning framework improves the performance by utilizing an adaptive optimizer (e.g., Adam) and a cross-round learning rate scheduler. In a network of realistic IoT devices (Raspberry PI), we evaluate FedIoT platform and FedDetect algorithm in both model and system performance. Our results demonstrate the efficacy of federated learning in detecting a large range of attack types. The system efficiency analysis indicates that both end-to-end training time and memory cost are affordable and promising for resource-constrained IoT devices. The source code is publicly available.