 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Hybrid Rice Breeding with Parametric Dual Projection
Jul 16, 2025



Hybrid rice breeding crossbreeds different rice lines and cultivates the resulting hybrids in fields to select those with desirable agronomic traits, such as higher yields. Recently, genomic selection has emerged as an efficient way for hybrid rice breeding. It predicts the traits of hybrids based on their genes, which helps exclude many undesired hybrids, largely reducing the workload of field cultivation. However, due to the limited accuracy of genomic prediction models, breeders still need to combine their experience with the models to identify regulatory genes that control traits and select hybrids, which remains a time-consuming process. To ease this process, in this paper, we proposed a visual analysis method to facilitate interactive hybrid rice breeding. Regulatory gene identification and hybrid selection naturally ensemble a dual-analysis task. Therefore, we developed a parametric dual projection method with theoretical guarantees to facilitate interactive dual analysis. Based on this dual projection method, we further developed a gene visualization and a hybrid visualization to verify the identified regulatory genes and hybrids. The effectiveness of our method is demonstrated through the quantitative evaluation of the parametric dual projection method, identified regulatory genes and desired hybrids in the case study, and positive feedback from breeders.
S-Crescendo: A Nested Transformer Weaving Framework for Scalable Nonlinear System in S-Domain Representation
May 17, 2025Simulation of high-order nonlinear system requires extensive computational resources, especially in modern VLSI backend design where bifurcation-induced instability and chaos-like transient behaviors pose challenges. We present S-Crescendo - a nested transformer weaving framework that synergizes S-domain with neural operators for scalable time-domain prediction in high-order nonlinear networks, alleviating the computational bottlenecks of conventional solvers via Newton-Raphson method. By leveraging the partial-fraction decomposition of an n-th order transfer function into first-order modal terms with repeated poles and residues, our method bypasses the conventional Jacobian matrix-based iterations and efficiently reduces computational complexity from cubic $O(n^3)$ to linear $O(n)$.The proposed architecture seamlessly integrates an S-domain encoder with an attention-based correction operator to simultaneously isolate dominant response and adaptively capture higher-order non-linearities. Validated on order-1 to order-10 networks, our method achieves up to 0.99 test-set ($R^2$) accuracy against HSPICE golden waveforms and accelerates simulation by up to 18(X), providing a scalable, physics-aware framework for high-dimensional nonlinear modeling.
Fusing Global and Local: Transformer-CNN Synergy for Next-Gen Current Estimation
Apr 08, 2025This paper presents a hybrid model combining Transformer and CNN for predicting the current waveform in signal lines. Unlike traditional approaches such as current source models, driver linear representations, waveform functional fitting, or equivalent load capacitance methods, our model does not rely on fixed simplified models of standard-cell drivers or RC loads. Instead, it replaces the complex Newton iteration process used in traditional SPICE simulations, leveraging the powerful sequence modeling capabilities of the Transformer framework to directly predict current responses without iterative solving steps. The hybrid architecture effectively integrates the global feature-capturing ability of Transformers with the local feature extraction advantages of CNNs, significantly improving the accuracy of current waveform predictions. Experimental results demonstrate that, compared to traditional SPICE simulations, the proposed algorithm achieves an error of only 0.0098. These results highlight the algorithm's superior capabilities in predicting signal line current waveforms, timing analysis, and power evaluation, making it suitable for a wide range of technology nodes, from 40nm to 3nm.
FedFixer: Mitigating Heterogeneous Label Noise in Federated Learning
Mar 25, 2024Federated Learning (FL) heavily depends on label quality for its performance. However, the label distribution among individual clients is always both noisy and heterogeneous. The high loss incurred by client-specific samples in heterogeneous label noise poses challenges for distinguishing between client-specific and noisy label samples, impacting the effectiveness of existing label noise learning approaches. To tackle this issue, we propose FedFixer, where the personalized model is introduced to cooperate with the global model to effectively select clean client-specific samples. In the dual models, updating the personalized model solely at a local level can lead to overfitting on noisy data due to limited samples, consequently affecting both the local and global models' performance. To mitigate overfitting, we address this concern from two perspectives. Firstly, we employ a confidence regularizer to alleviate the impact of unconfident predictions caused by label noise. Secondly, a distance regularizer is implemented to constrain the disparity between the personalized and global models. We validate the effectiveness of FedFixer through extensive experiments on benchmark datasets. The results demonstrate that FedFixer can perform well in filtering noisy label samples on different clients, especially in highly heterogeneous label noise scenarios.
Towards Trustworthy Explanation: On Causal Rationalization
Jun 25, 2023With recent advances in natural language processing, rationalization becomes an essential self-explaining diagram to disentangle the black box by selecting a subset of input texts to account for the major variation in prediction. Yet, existing association-based approaches on rationalization cannot identify true rationales when two or more snippets are highly inter-correlated and thus provide a similar contribution to prediction accuracy, so-called spuriousness. To address this limitation, we novelly leverage two causal desiderata, non-spuriousness and efficiency, into rationalization from the causal inference perspective. We formally define a series of probabilities of causation based on a newly proposed structural causal model of rationalization, with its theoretical identification established as the main component of learning necessary and sufficient rationales. The superior performance of the proposed causal rationalization is demonstrated on real-world review and medical datasets with extensive experiments compared to state-of-the-art methods.
FD-GATDR: A Federated-Decentralized-Learning Graph Attention Network for Doctor Recommendation Using EHR
Jul 11, 2022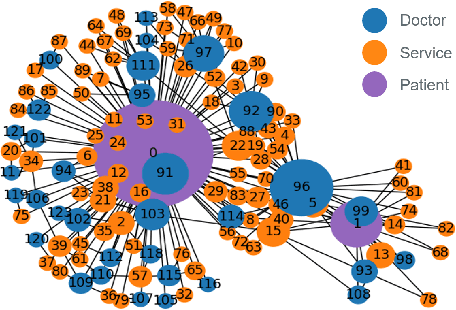
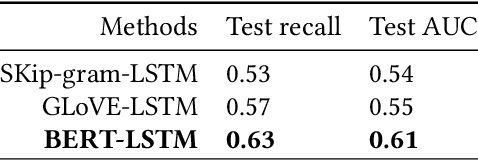
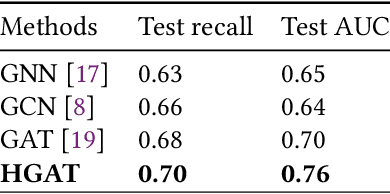
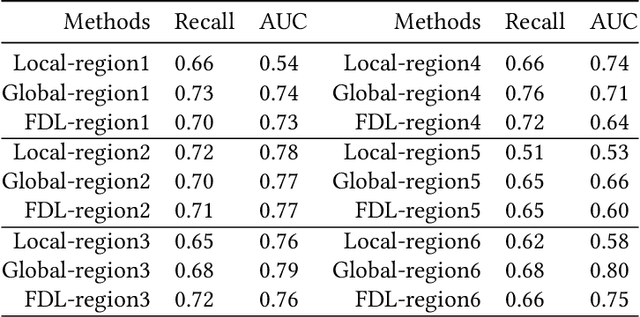
In the past decade, with the development of big data technology, an increasing amount of patient information has been stored as electronic health records (EHRs). Leveraging these data, various doctor recommendation systems have been proposed. Typically, such studies process the EHR data in a flat-structured manner, where each encounter was treated as an unordered set of features. Nevertheless, the heterogeneous structured information such as service sequence stored in claims shall not be ignored. This paper presents a doctor recommendation system with time embedding to reconstruct the potential connections between patients and doctors using heterogeneous graph attention network. Besides, to address the privacy issue of patient data sharing crossing hospitals, a federated decentralized learning method based on a minimization optimization model is also proposed. The graph-based recommendation system has been validated on a EHR dataset. Compared to baseline models, the proposed method improves the AUC by up to 6.2%. And our proposed federated-based algorithm not only yields the fictitious fusion center's performance but also enjoys a convergence rate of O(1/T).
Predicting Treatment Initiation from Clinical Time Series Data via Graph-Augmented Time-Sensitive Model
Jul 01, 2019

Many computational models were proposed to extract temporal patterns from clinical time series for each patient and among patient group for predictive healthcare. However, the common relations among patients (e.g., share the same doctor) were rarely considered. In this paper, we represent patients and clinicians relations by bipartite graphs addressing for example from whom a patient get a diagnosis. We then solve for the top eigenvectors of the graph Laplacian, and include the eigenvectors as latent representations of the similarity between patient-clinician pairs into a time-sensitive prediction model. We conducted experiments using real-world data to predict the initiation of first-line treatment for Chronic Lymphocytic Leukemia (CLL) patients. Results show that relational similarity can improve prediction over multiple baselines, for example a 5% incremental over long-short term memory baseline in terms of area under precision-recall curve.
Rare Disease Detection by Sequence Modeling with Generative Adversarial Networks
Jul 01, 2019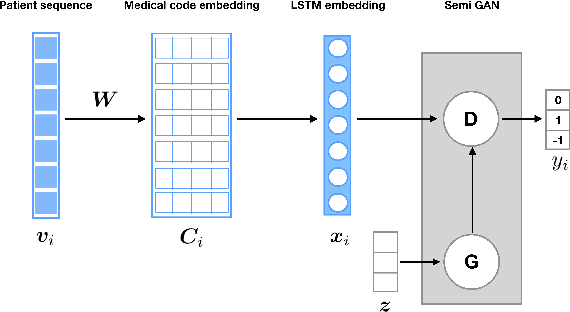
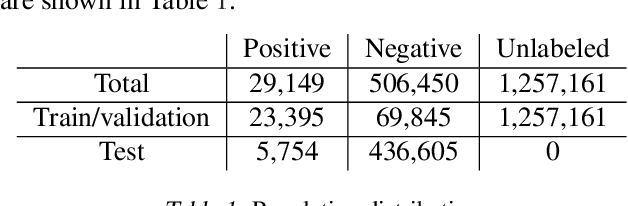
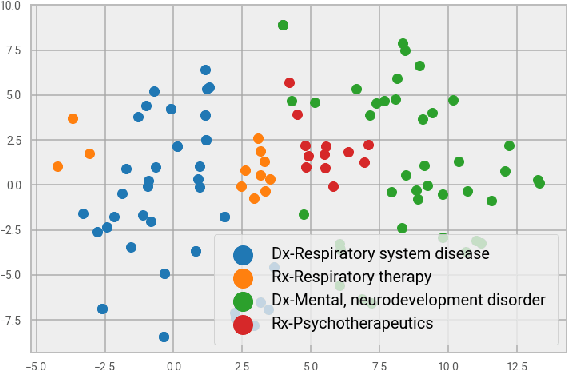
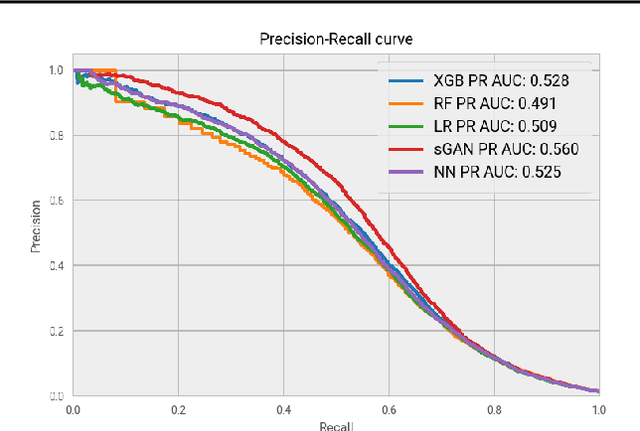
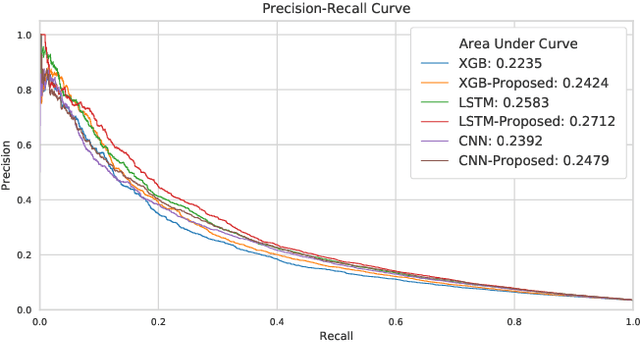
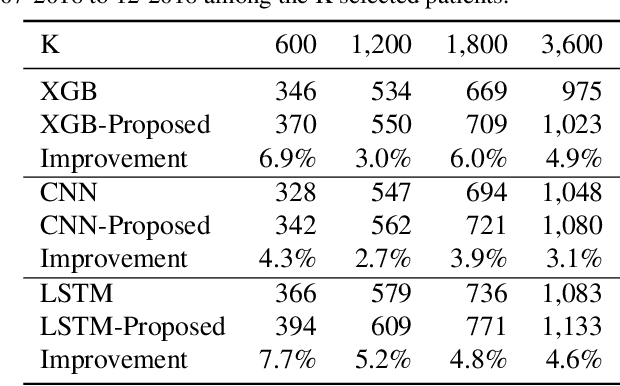
Rare diseases affecting 350 million individuals are commonly associated with delay in diagnosis or misdiagnosis. To improve those patients' outcome, rare disease detection is an important task for identifying patients with rare conditions based on longitudinal medical claims. In this paper, we present a deep learning method for detecting patients with exocrine pancreatic insufficiency (EPI) (a rare disease). The contribution includes 1) a large longitudinal study using 7 years medical claims from 1.8 million patients including 29,149 EPI patients, 2) a new deep learning model using generative adversarial networks (GANs) to boost rare disease class, and also leveraging recurrent neural networks to model patient sequence data, 3) an accurate prediction with 0.56 PR-AUC which outperformed benchmark models in terms of precision and recall.
Semi-supervised Rare Disease Detection Using Generative Adversarial Network
Dec 03, 2018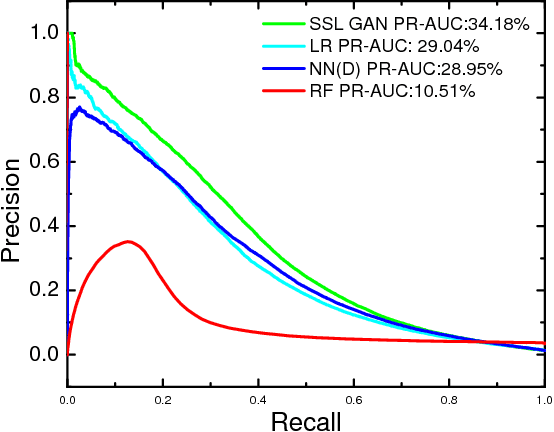

Rare diseases affect a relatively small number of people, which limits investment in research for treatments and cures. Developing an efficient method for rare disease detection is a crucial first step towards subsequent clinical research. In this paper, we present a semi-supervised learning framework for rare disease detection using generative adversarial networks. Our method takes advantage of the large amount of unlabeled data for disease detection and achieves the best results in terms of precision-recall score compared to baseline techniques.
Rare Disease Physician Targeting: A Factor Graph Approach
Jan 19, 2017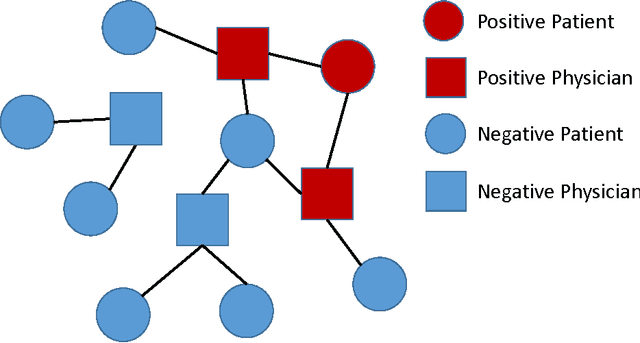

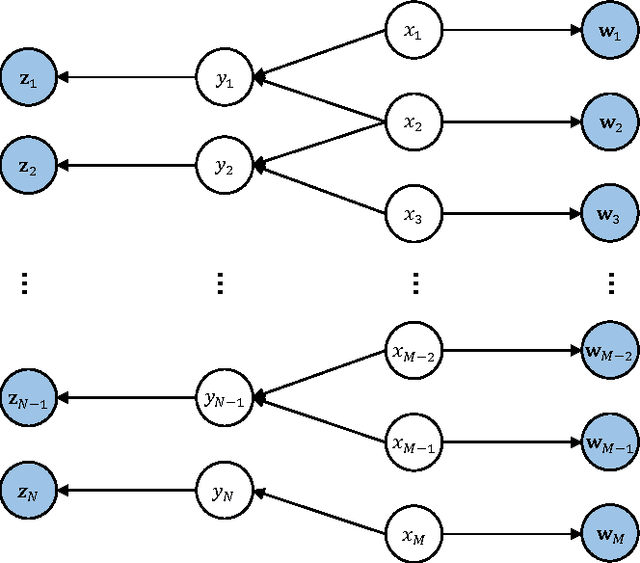
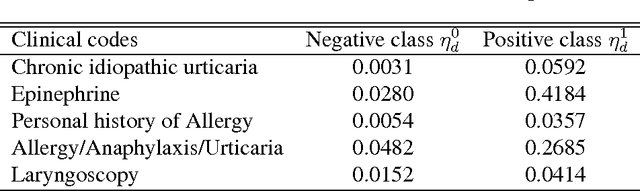
In rare disease physician targeting, a major challenge is how to identify physicians who are treating diagnosed or underdiagnosed rare diseases patients. Rare diseases have extremely low incidence rate. For a specified rare disease, only a small number of patients are affected and a fractional of physicians are involved. The existing targeting methodologies, such as segmentation and profiling, are developed under mass market assumption. They are not suitable for rare disease market where the target classes are extremely imbalanced. The authors propose a graphical model approach to predict targets by jointly modeling physician and patient features from different data spaces and utilizing the extra relational information. Through an empirical example with medical claim and prescription data, the proposed approach demonstrates better accuracy in finding target physicians. The graph representation also provides visual interpretability of relationship among physicians and patients. The model can be extended to incorporate more complex dependency structures. This article contributes to the literature of exploring the benefit of utilizing relational dependencies among entities in healthcare industry.