 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGIS: Evidence-Based Multi-Agent Reasoning for Interpretable Strabismus Clinical Decision-Making
Jun 08, 2026Strabismus is a common ocular disorder that requires fine-grained subtype diagnosis for individualized treatment planning. However, existing deep learning methods mainly provide diagnostic predictions without transparent reasoning, while recent large vision-language models (LVLMs), although promising for joint image understanding and report generation, remain highly prone to hallucination in this evidence-sensitive and rule-driven medical task. To address these challenges, we propose MAGIS, an evidence-based Multi-AGent reasoning for Interpretable Strabismus diagnosis framework. MAGIS transforms black-box end-to-end generation into a structured diagnostic process consisting of candidate hypothesis generation, dual-evidence constrained context, evidence-based corrective verification, and report generation. Specifically, we introduce a Dual-Evidence Constrained Context (DECC) mechanism that jointly organizes visual evidence from the photograph of the nine cardinal positions of gaze and evidence-based clinical diagnostic rules into a constrained context for reliable diagnostic reasoning. We further develop an Evidence-Based Corrective Verification (EBCV) mechanism that verifies whether the current diagnostic hypothesis is supported by visual evidence, heatmap-based visual cues, and evidence-based clinical diagnostic rules. Hypothesis refinement is triggered when inconsistency is detected. Experiments on a fine-grained strabismus benchmark demonstrate that MAGIS not only significantly outperforms other state-of-the-art diagnostic systems, improving the weighted F1 score from 72.0% to 91.3%, but also substantially improves the clinical reliability (consistency, alignment, and completeness) of generated diagnostic reports. These results demonstrate that MAGIS provides an effective solution for building accurate, evidence-based, and clinically interpretable strabismus diagnosis systems.
IterInject: Indirect Prompt Injection Against LLM Agents via Feedback-Guided Iterative Optimization
May 23, 2026LLM-based agents are increasingly deployed for complex tasks requiring planning, tool use, and interaction with external services. Their reliance on untrusted external content exposes them to indirect prompt injection (IPI), in which adversarial instructions embedded in retrieved data hijack agent behavior. Existing attacks rely on static payloads that cannot adapt to agent-specific defenses; even recent adaptive methods lack structured feedback to guide optimization. We introduce \oursys, a feedback-guided iterative framework that closes the loop between injection, diagnosis, and refinement: a rule-based diagnoser produces structured outcome labels with behavioral descriptions, and an LLM-based optimizer refines payloads conditioned on the full optimization history. A synthesis step generates new disguise seeds from failure patterns, enabling the strategy space to self-evolve. On AgentDojo and InjectAgent, \oursys substantially outperforms static baselines and existing adaptive methods across four victim models. Extension experiments on Claude Code, a production-grade coding agent with layered defenses, show that optimized payloads achieve full success on 5 of 9 targets; even those that resist full exploitation exhibit measurable improvement from iterative refinement. We further present a mechanistic analysis of IPI, identifying an attention-mediated threshold mechanism in mid-to-late layers; three causal interventions validate this finding and point to concrete defense directions.
Pair2Scene: Learning Local Object Relations for Procedural Scene Generation
Apr 13, 2026Generating high-fidelity 3D indoor scenes remains a significant challenge due to data scarcity and the complexity of modeling intricate spatial relations. Current methods often struggle to scale beyond training distribution to dense scenes or rely on LLMs/VLMs that lack the ability for precise spatial reasoning. Building on top of the observation that object placement relies mainly on local dependencies instead of information-redundant global distributions, in this paper, we propose Pair2Scene, a novel procedural generation framework that integrates learned local rules with scene hierarchies and physics-based algorithms. These rules mainly capture two types of inter-object relations, namely support relations that follow physical hierarchies, and functional relations that reflect semantic links. We model these rules through a network, which estimates spatial position distributions of dependent objects conditioned on position and geometry of the anchor ones. Accordingly, we curate a dataset 3D-Pairs from existing scene data to train the model. During inference, our framework can generate scenes by recursively applying our model within a hierarchical structure, leveraging collision-aware rejection sampling to align local rules into coherent global layouts. Extensive experiments demonstrate that our framework outperforms existing methods in generating complex environments that go beyond training data while maintaining physical and semantic plausibility.
AgentLTV: An Agent-Based Unified Search-and-Evolution Framework for Automated Lifetime Value Prediction
Feb 25, 2026Lifetime Value (LTV) prediction is critical in advertising, recommender systems, and e-commerce. In practice, LTV data patterns vary across decision scenarios. As a result, practitioners often build complex, scenario-specific pipelines and iterate over feature processing, objective design, and tuning. This process is expensive and hard to transfer. We propose AgentLTV, an agent-based unified search-and-evolution framework for automated LTV modeling. AgentLTV treats each candidate solution as an {executable pipeline program}. LLM-driven agents generate code, run and repair pipelines, and analyze execution feedback. Two decision agents coordinate a two-stage search. The Monte Carlo Tree Search (MCTS) stage explores a broad space of modeling choices under a fixed budget, guided by the Polynomial Upper Confidence bounds for Trees criterion and a Pareto-aware multi-metric value function. The Evolutionary Algorithm (EA) stage refines the best MCTS program via island-based evolution with crossover, mutation, and migration. Experiments on a large-scale proprietary dataset and a public benchmark show that AgentLTV consistently discovers strong models across ranking and error metrics. Online bucket-level analysis further indicates improved ranking consistency and value calibration, especially for high-value and negative-LTV segments. We summarize practitioner-oriented takeaways: use MCTS for rapid adaptation to new data patterns, use EA for stable refinement, and validate deployment readiness with bucket-level ranking and calibration diagnostics. The proposed AgentLTV has been successfully deployed online.
Fine-Tuning a Large Vision-Language Model for Artwork's Scoring and Critique
Feb 09, 2026Assessing artistic creativity is foundational to creativity research and arts education, yet manual scoring (e.g., Torrance Tests of Creative Thinking) is labor-intensive at scale. Prior machine-learning approaches show promise for visual creativity scoring, but many rely mainly on image features and provide limited or no explanatory feedback. We propose a framework for automated creativity assessment of human paintings by fine-tuning the vision-language model Qwen2-VL-7B with multi-task learning. Our dataset contains 1000 human-created paintings scored on a 1-100 scale and paired with a short human-written description (content or artist explanation). Two expert raters evaluated each work using a five-dimension rubric (originality, color, texture, composition, content) and provided written critiques; we use an 80/20 train-test split. We add a lightweight regression head on the visual encoder output so the model can predict a numerical score and generate rubric-aligned feedback in a single forward pass. By embedding the structured rubric and the artwork description in the system prompt, we constrain the generated text to match the quantitative prediction. Experiments show strong accuracy, achieving Pearson r > 0.97 and MAE about 3.95 on the 100-point scale. Qualitative evaluation indicates the generated feedback is semantically close to expert critiques (average SBERT cosine similarity = 0.798). The proposed approach bridges computer vision and art assessment and offers a scalable tool for creativity research and classroom feedback.
Physical Transformer
Jan 05, 2026Digital AI systems spanning large language models, vision models, and generative architectures that operate primarily in symbolic, linguistic, or pixel domains. They have achieved striking progress, but almost all of this progress lives in virtual spaces. These systems transform embeddings and tokens, yet do not themselves touch the world and rarely admit a physical interpretation. In this work we propose a physical transformer that couples modern transformer style computation with geometric representation and physical dynamics. At the micro level, attention heads, and feed-forward blocks are modeled as interacting spins governed by effective Hamiltonians plus non-Hamiltonian bath terms. At the meso level, their aggregated state evolves on a learned Neural Differential Manifold (NDM) under Hamiltonian flows and Hamilton, Jacobi, Bellman (HJB) optimal control, discretized by symplectic layers that approximately preserve geometric and energetic invariants. At the macro level, the model maintains a generative semantic workspace and a two-dimensional information-phase portrait that tracks uncertainty and information gain over a reasoning trajectory. Within this hierarchy, reasoning tasks are formulated as controlled information flows on the manifold, with solutions corresponding to low cost trajectories that satisfy geometric, energetic, and workspace-consistency constraints. On simple toy problems involving numerical integration and dynamical systems, the physical transformer outperforms naive baselines in stability and long-horizon accuracy, highlighting the benefits of respecting underlying geometric and Hamiltonian structure. More broadly, the framework suggests a path toward physical AI that unify digital reasoning with physically grounded manifolds, opening a route to more interpretable and potentially unified models of reasoning, control, and interaction with the real world.
S-Crescendo: A Nested Transformer Weaving Framework for Scalable Nonlinear System in S-Domain Representation
May 17, 2025Simulation of high-order nonlinear system requires extensive computational resources, especially in modern VLSI backend design where bifurcation-induced instability and chaos-like transient behaviors pose challenges. We present S-Crescendo - a nested transformer weaving framework that synergizes S-domain with neural operators for scalable time-domain prediction in high-order nonlinear networks, alleviating the computational bottlenecks of conventional solvers via Newton-Raphson method. By leveraging the partial-fraction decomposition of an n-th order transfer function into first-order modal terms with repeated poles and residues, our method bypasses the conventional Jacobian matrix-based iterations and efficiently reduces computational complexity from cubic $O(n^3)$ to linear $O(n)$.The proposed architecture seamlessly integrates an S-domain encoder with an attention-based correction operator to simultaneously isolate dominant response and adaptively capture higher-order non-linearities. Validated on order-1 to order-10 networks, our method achieves up to 0.99 test-set ($R^2$) accuracy against HSPICE golden waveforms and accelerates simulation by up to 18(X), providing a scalable, physics-aware framework for high-dimensional nonlinear modeling.
Fusing Global and Local: Transformer-CNN Synergy for Next-Gen Current Estimation
Apr 08, 2025This paper presents a hybrid model combining Transformer and CNN for predicting the current waveform in signal lines. Unlike traditional approaches such as current source models, driver linear representations, waveform functional fitting, or equivalent load capacitance methods, our model does not rely on fixed simplified models of standard-cell drivers or RC loads. Instead, it replaces the complex Newton iteration process used in traditional SPICE simulations, leveraging the powerful sequence modeling capabilities of the Transformer framework to directly predict current responses without iterative solving steps. The hybrid architecture effectively integrates the global feature-capturing ability of Transformers with the local feature extraction advantages of CNNs, significantly improving the accuracy of current waveform predictions. Experimental results demonstrate that, compared to traditional SPICE simulations, the proposed algorithm achieves an error of only 0.0098. These results highlight the algorithm's superior capabilities in predicting signal line current waveforms, timing analysis, and power evaluation, making it suitable for a wide range of technology nodes, from 40nm to 3nm.
On the Performance Analysis of Momentum Method: A Frequency Domain Perspective
Nov 29, 2024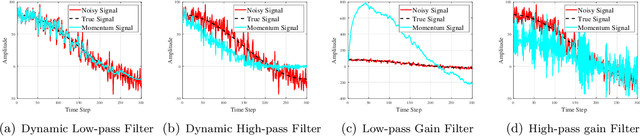

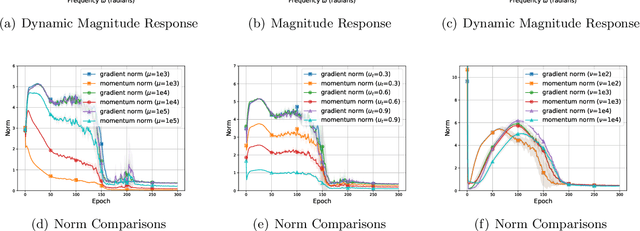

Momentum-based optimizers are widely adopted for training neural networks. However, the optimal selection of momentum coefficients remains elusive. This uncertainty impedes a clear understanding of the role of momentum in stochastic gradient methods. In this paper, we present a frequency domain analysis framework that interprets the momentum method as a time-variant filter for gradients, where adjustments to momentum coefficients modify the filter characteristics. Our experiments support this perspective and provide a deeper understanding of the mechanism involved. Moreover, our analysis reveals the following significant findings: high-frequency gradient components are undesired in the late stages of training; preserving the original gradient in the early stages, and gradually amplifying low-frequency gradient components during training both enhance generalization performance. Based on these insights, we propose Frequency Stochastic Gradient Descent with Momentum (FSGDM), a heuristic optimizer that dynamically adjusts the momentum filtering characteristic with an empirically effective dynamic magnitude response. Experimental results demonstrate the superiority of FSGDM over conventional momentum optimizers.
Using a CNN Model to Assess Visual Artwork's Creativity
Aug 02, 2024



Assessing artistic creativity has long challenged researchers, with traditional methods proving time-consuming. Recent studies have applied machine learning to evaluate creativity in drawings, but not paintings. Our research addresses this gap by developing a CNN model to automatically assess the creativity of students' paintings. Using a dataset of 600 paintings by professionals and children, our model achieved 90% accuracy and faster evaluation times than human raters. This approach demonstrates the potential of machine learning in advancing artistic creativity assessment, offering a more efficient alternative to traditional methods.