 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistorted or Fabricated? A Survey on Hallucination in Video LLMs
Apr 14, 2026Despite significant progress in video-language modeling, hallucinations remain a persistent challenge in Video Large Language Models (Vid-LLMs), referring to outputs that appear plausible yet contradict the content of the input video. This survey presents a comprehensive analysis of hallucinations in Vid-LLMs and introduces a systematic taxonomy that categorizes them into two core types: dynamic distortion and content fabrication, each comprising two subtypes with representative cases. Building on this taxonomy, we review recent advances in the evaluation and mitigation of hallucinations, covering key benchmarks, metrics, and intervention strategies. We further analyze the root causes of dynamic distortion and content fabrication, which often result from limited capacity for temporal representation and insufficient visual grounding. These insights inform several promising directions for future work, including the development of motion-aware visual encoders and the integration of counterfactual learning techniques. This survey consolidates scattered progress to foster a systematic understanding of hallucinations in Vid-LLMs, laying the groundwork for building robust and reliable video-language systems. An up-to-date curated list of related works is maintained at https://github.com/hukcc/Awesome-Video-Hallucination .
The Indra Representation Hypothesis for Multimodal Alignment
Apr 06, 2026Recent studies have uncovered an interesting phenomenon: unimodal foundation models tend to learn convergent representations, regardless of differences in architecture, training objectives, or data modalities. However, these representations are essentially internal abstractions of samples that characterize samples independently, leading to limited expressiveness. In this paper, we propose The Indra Representation Hypothesis, inspired by the philosophical metaphor of Indra's Net. We argue that representations from unimodal foundation models are converging to implicitly reflect a shared relational structure underlying reality, akin to the relational ontology of Indra's Net. We formalize this hypothesis using the V-enriched Yoneda embedding from category theory, defining the Indra representation as a relational profile of each sample with respect to others. This formulation is shown to be unique, complete, and structure-preserving under a given cost function. We instantiate the Indra representation using angular distance and evaluate it in cross-model and cross-modal scenarios involving vision, language, and audio. Extensive experiments demonstrate that Indra representations consistently enhance robustness and alignment across architectures and modalities, providing a theoretically grounded and practical framework for training-free alignment of unimodal foundation models. Our code is available at https://github.com/Jianglin954/Indra.
Ref-Adv: Exploring MLLM Visual Reasoning in Referring Expression Tasks
Feb 27, 2026Referring Expression Comprehension (REC) links language to region level visual perception. Standard benchmarks (RefCOCO, RefCOCO+, RefCOCOg) have progressed rapidly with multimodal LLMs but remain weak tests of visual reasoning and grounding: (i) many expressions are very short, leaving little reasoning demand; (ii) images often contain few distractors, making the target easy to find; and (iii) redundant descriptors enable shortcut solutions that bypass genuine text understanding and visual reasoning. We introduce Ref-Adv, a modern REC benchmark that suppresses shortcuts by pairing linguistically nontrivial expressions with only the information necessary to uniquely identify the target. The dataset contains referring expressions on real images, curated with hard distractors and annotated with reasoning facets including negation. We conduct comprehensive ablations (word order perturbations and descriptor deletion sufficiency) to show that solving Ref-Adv requires reasoning beyond simple cues, and we evaluate a broad suite of contemporary multimodal LLMs on Ref-Adv. Despite strong results on RefCOCO, RefCOCO+, and RefCOCOg, models drop markedly on Ref-Adv, revealing reliance on shortcuts and gaps in visual reasoning and grounding. We provide an in depth failure analysis and aim for Ref-Adv to guide future work on visual reasoning and grounding in MLLMs.
Fine-T2I: An Open, Large-Scale, and Diverse Dataset for High-Quality T2I Fine-Tuning
Feb 10, 2026High-quality and open datasets remain a major bottleneck for text-to-image (T2I) fine-tuning. Despite rapid progress in model architectures and training pipelines, most publicly available fine-tuning datasets suffer from low resolution, poor text-image alignment, or limited diversity, resulting in a clear performance gap between open research models and enterprise-grade models. In this work, we present Fine-T2I, a large-scale, high-quality, and fully open dataset for T2I fine-tuning. Fine-T2I spans 10 task combinations, 32 prompt categories, 11 visual styles, and 5 prompt templates, and combines synthetic images generated by strong modern models with carefully curated real images from professional photographers. All samples are rigorously filtered for text-image alignment, visual fidelity, and prompt quality, with over 95% of initial candidates removed. The final dataset contains over 6 million text-image pairs, around 2 TB on disk, approaching the scale of pretraining datasets while maintaining fine-tuning-level quality. Across a diverse set of pretrained diffusion and autoregressive models, fine-tuning on Fine-T2I consistently improves both generation quality and instruction adherence, as validated by human evaluation, visual comparison, and automatic metrics. We release Fine-T2I under an open license to help close the data gap in T2I fine-tuning in the open community.
CompSRT: Quantization and Pruning for Image Super Resolution Transformers
Jan 28, 2026Model compression has become an important tool for making image super resolution models more efficient. However, the gap between the best compressed models and the full precision model still remains large and a need for deeper understanding of compression theory on more performant models remains. Prior research on quantization of LLMs has shown that Hadamard transformations lead to weights and activations with reduced outliers, which leads to improved performance. We argue that while the Hadamard transform does reduce the effect of outliers, an empirical analysis on how the transform functions remains needed. By studying the distributions of weights and activations of SwinIR-light, we show with statistical analysis that lower errors is caused by the Hadamard transforms ability to reduce the ranges, and increase the proportion of values around $0$. Based on these findings, we introduce CompSRT, a more performant way to compress the image super resolution transformer network SwinIR-light. We perform Hadamard-based quantization, and we also perform scalar decomposition to introduce two additional trainable parameters. Our quantization performance statistically significantly surpasses the SOTA in metrics with gains as large as 1.53 dB, and visibly improves visual quality by reducing blurriness at all bitwidths. At $3$-$4$ bits, to show our method is compatible with pruning for increased compression, we also prune $40\%$ of weights and show that we can achieve $6.67$-$15\%$ reduction in bits per parameter with comparable performance to SOTA.
MTS-DMAE: Dual-Masked Autoencoder for Unsupervised Multivariate Time Series Representation Learning
Sep 19, 2025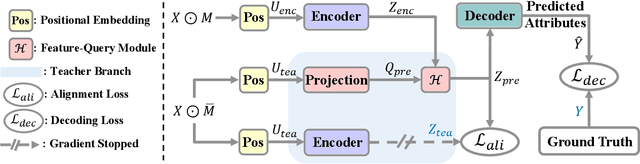
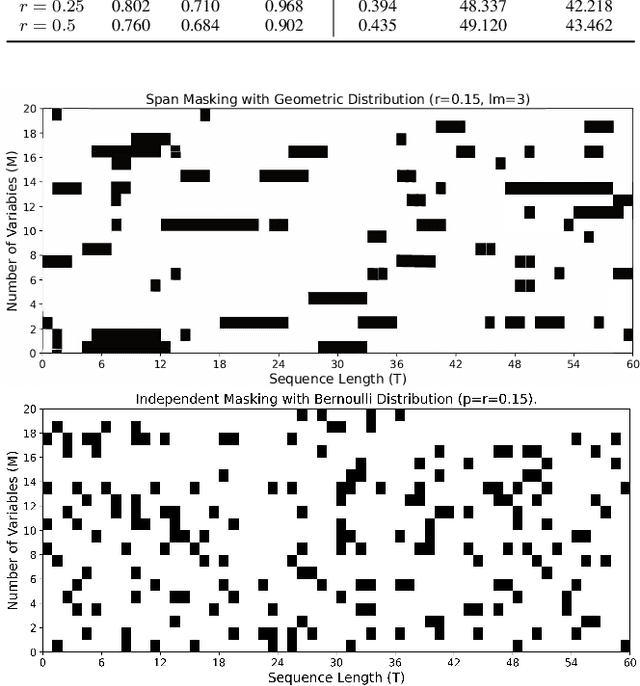
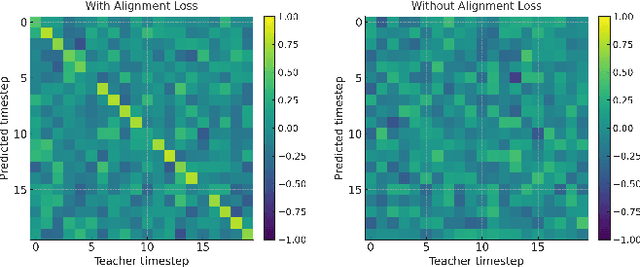
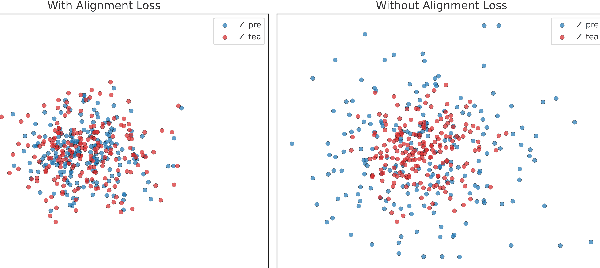
Unsupervised multivariate time series (MTS) representation learning aims to extract compact and informative representations from raw sequences without relying on labels, enabling efficient transfer to diverse downstream tasks. In this paper, we propose Dual-Masked Autoencoder (DMAE), a novel masked time-series modeling framework for unsupervised MTS representation learning. DMAE formulates two complementary pretext tasks: (1) reconstructing masked values based on visible attributes, and (2) estimating latent representations of masked features, guided by a teacher encoder. To further improve representation quality, we introduce a feature-level alignment constraint that encourages the predicted latent representations to align with the teacher's outputs. By jointly optimizing these objectives, DMAE learns temporally coherent and semantically rich representations. Comprehensive evaluations across classification, regression, and forecasting tasks demonstrate that our approach achieves consistent and superior performance over competitive baselines.
SKOLR: Structured Koopman Operator Linear RNN for Time-Series Forecasting
Jun 17, 2025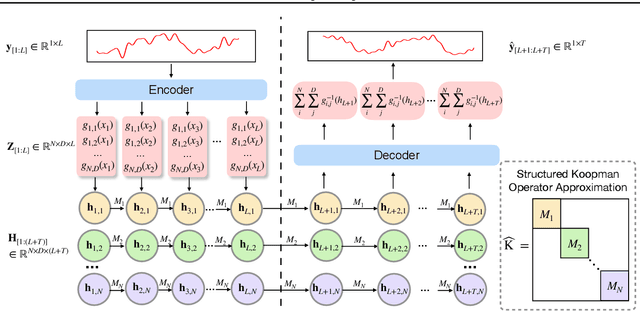



Koopman operator theory provides a framework for nonlinear dynamical system analysis and time-series forecasting by mapping dynamics to a space of real-valued measurement functions, enabling a linear operator representation. Despite the advantage of linearity, the operator is generally infinite-dimensional. Therefore, the objective is to learn measurement functions that yield a tractable finite-dimensional Koopman operator approximation. In this work, we establish a connection between Koopman operator approximation and linear Recurrent Neural Networks (RNNs), which have recently demonstrated remarkable success in sequence modeling. We show that by considering an extended state consisting of lagged observations, we can establish an equivalence between a structured Koopman operator and linear RNN updates. Building on this connection, we present SKOLR, which integrates a learnable spectral decomposition of the input signal with a multilayer perceptron (MLP) as the measurement functions and implements a structured Koopman operator via a highly parallel linear RNN stack. Numerical experiments on various forecasting benchmarks and dynamical systems show that this streamlined, Koopman-theory-based design delivers exceptional performance.
S-Crescendo: A Nested Transformer Weaving Framework for Scalable Nonlinear System in S-Domain Representation
May 17, 2025Simulation of high-order nonlinear system requires extensive computational resources, especially in modern VLSI backend design where bifurcation-induced instability and chaos-like transient behaviors pose challenges. We present S-Crescendo - a nested transformer weaving framework that synergizes S-domain with neural operators for scalable time-domain prediction in high-order nonlinear networks, alleviating the computational bottlenecks of conventional solvers via Newton-Raphson method. By leveraging the partial-fraction decomposition of an n-th order transfer function into first-order modal terms with repeated poles and residues, our method bypasses the conventional Jacobian matrix-based iterations and efficiently reduces computational complexity from cubic $O(n^3)$ to linear $O(n)$.The proposed architecture seamlessly integrates an S-domain encoder with an attention-based correction operator to simultaneously isolate dominant response and adaptively capture higher-order non-linearities. Validated on order-1 to order-10 networks, our method achieves up to 0.99 test-set ($R^2$) accuracy against HSPICE golden waveforms and accelerates simulation by up to 18(X), providing a scalable, physics-aware framework for high-dimensional nonlinear modeling.
Fusing Global and Local: Transformer-CNN Synergy for Next-Gen Current Estimation
Apr 08, 2025This paper presents a hybrid model combining Transformer and CNN for predicting the current waveform in signal lines. Unlike traditional approaches such as current source models, driver linear representations, waveform functional fitting, or equivalent load capacitance methods, our model does not rely on fixed simplified models of standard-cell drivers or RC loads. Instead, it replaces the complex Newton iteration process used in traditional SPICE simulations, leveraging the powerful sequence modeling capabilities of the Transformer framework to directly predict current responses without iterative solving steps. The hybrid architecture effectively integrates the global feature-capturing ability of Transformers with the local feature extraction advantages of CNNs, significantly improving the accuracy of current waveform predictions. Experimental results demonstrate that, compared to traditional SPICE simulations, the proposed algorithm achieves an error of only 0.0098. These results highlight the algorithm's superior capabilities in predicting signal line current waveforms, timing analysis, and power evaluation, making it suitable for a wide range of technology nodes, from 40nm to 3nm.
GmNet: Revisiting Gating Mechanisms From A Frequency View
Mar 28, 2025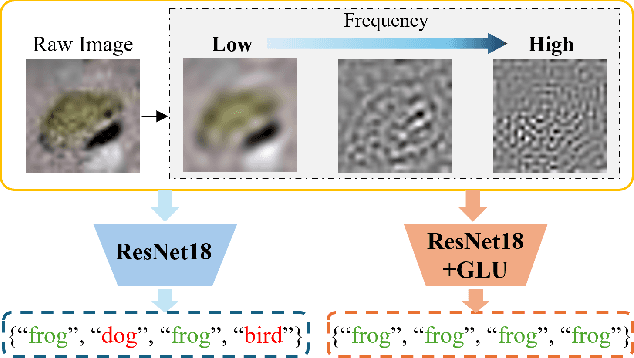
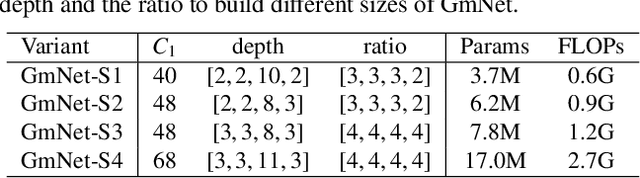
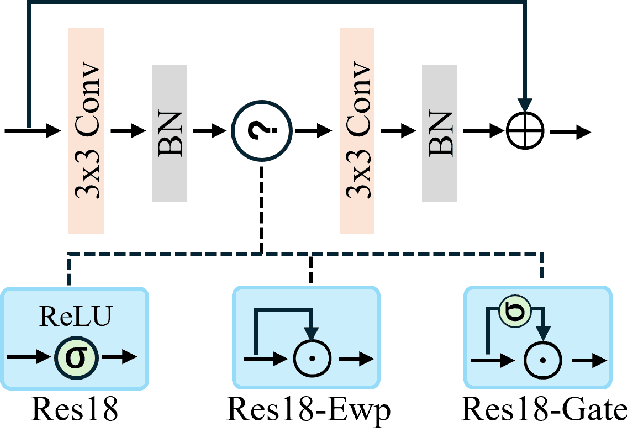
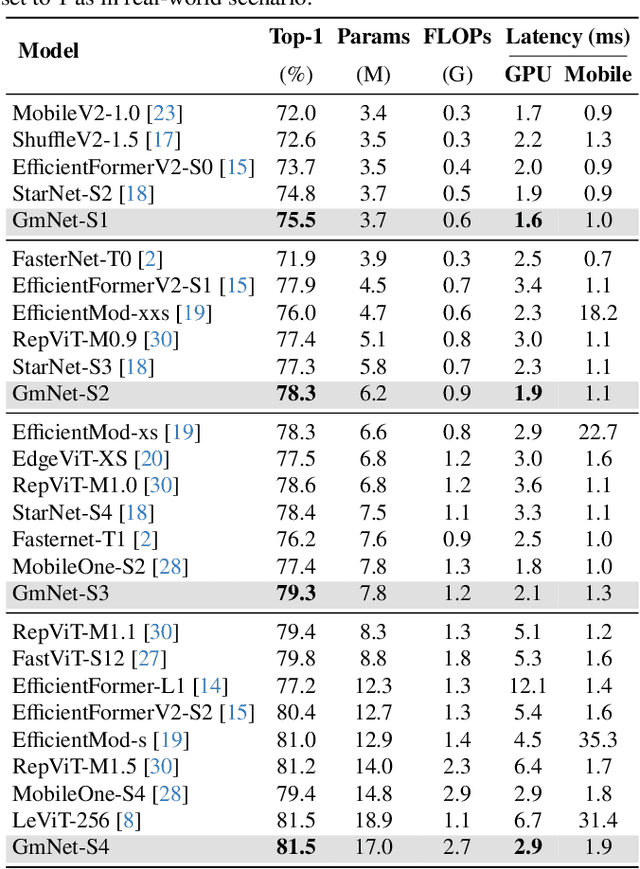
Gating mechanisms have emerged as an effective strategy integrated into model designs beyond recurrent neural networks for addressing long-range dependency problems. In a broad understanding, it provides adaptive control over the information flow while maintaining computational efficiency. However, there is a lack of theoretical analysis on how the gating mechanism works in neural networks. In this paper, inspired by the {convolution theorem}, we systematically explore the effect of gating mechanisms on the training dynamics of neural networks from a frequency perspective. We investigate the interact between the element-wise product and activation functions in managing the responses to different frequency components. Leveraging these insights, we propose a Gating Mechanism Network (GmNet), a lightweight model designed to efficiently utilize the information of various frequency components. It minimizes the low-frequency bias present in existing lightweight models. GmNet achieves impressive performance in terms of both effectiveness and efficiency in the image classification task.