 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGmNet: Revisiting Gating Mechanisms From A Frequency View
Mar 28, 2025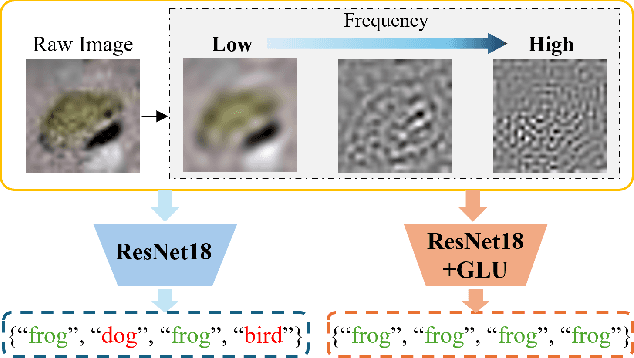
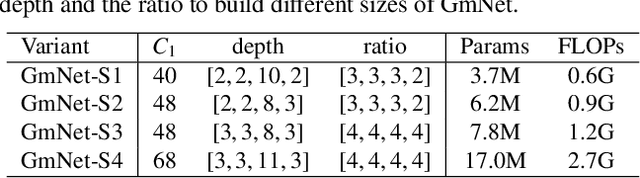
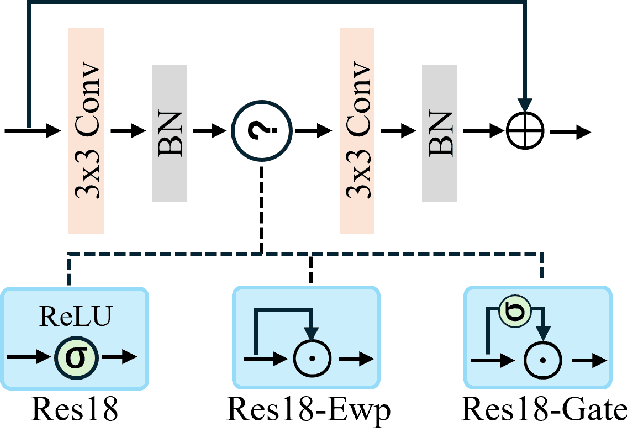
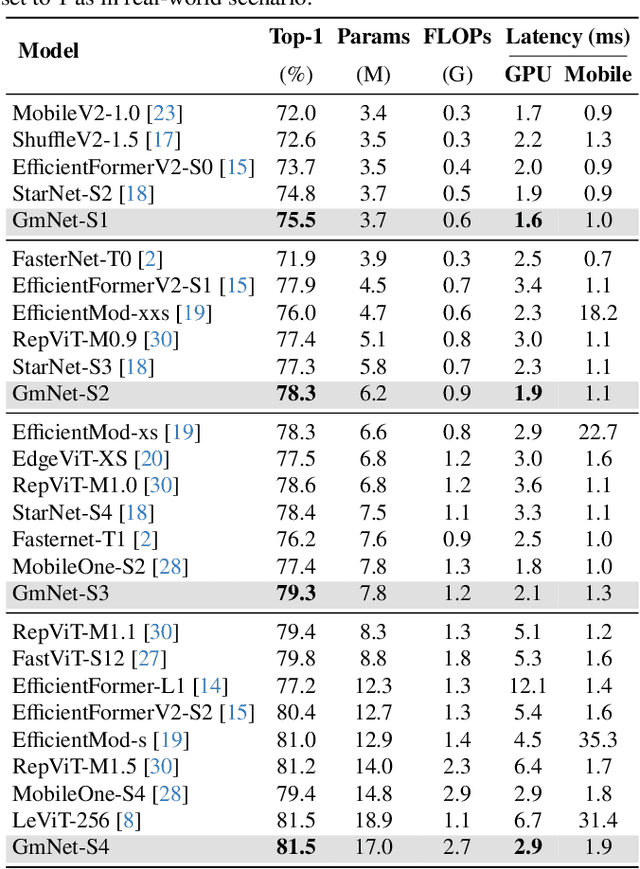
Gating mechanisms have emerged as an effective strategy integrated into model designs beyond recurrent neural networks for addressing long-range dependency problems. In a broad understanding, it provides adaptive control over the information flow while maintaining computational efficiency. However, there is a lack of theoretical analysis on how the gating mechanism works in neural networks. In this paper, inspired by the {convolution theorem}, we systematically explore the effect of gating mechanisms on the training dynamics of neural networks from a frequency perspective. We investigate the interact between the element-wise product and activation functions in managing the responses to different frequency components. Leveraging these insights, we propose a Gating Mechanism Network (GmNet), a lightweight model designed to efficiently utilize the information of various frequency components. It minimizes the low-frequency bias present in existing lightweight models. GmNet achieves impressive performance in terms of both effectiveness and efficiency in the image classification task.
Unleashing the Power of LLMs as Multi-Modal Encoders for Text and Graph-Structured Data
Oct 15, 2024



Graph-structured information offers rich contextual information that can enhance language models by providing structured relationships and hierarchies, leading to more expressive embeddings for various applications such as retrieval, question answering, and classification. However, existing methods for integrating graph and text embeddings, often based on Multi-layer Perceptrons (MLPs) or shallow transformers, are limited in their ability to fully exploit the heterogeneous nature of these modalities. To overcome this, we propose Janus, a simple yet effective framework that leverages Large Language Models (LLMs) to jointly encode text and graph data. Specifically, Janus employs an MLP adapter to project graph embeddings into the same space as text embeddings, allowing the LLM to process both modalities jointly. Unlike prior work, we also introduce contrastive learning to align the graph and text spaces more effectively, thereby improving the quality of learned joint embeddings. Empirical results across six datasets spanning three tasks, knowledge graph-contextualized question answering, graph-text pair classification, and retrieval, demonstrate that Janus consistently outperforms existing baselines, achieving significant improvements across multiple datasets, with gains of up to 11.4% in QA tasks. These results highlight Janus's effectiveness in integrating graph and text data. Ablation studies further validate the effectiveness of our method.
A Survey for Large Language Models in Biomedicine
Aug 29, 2024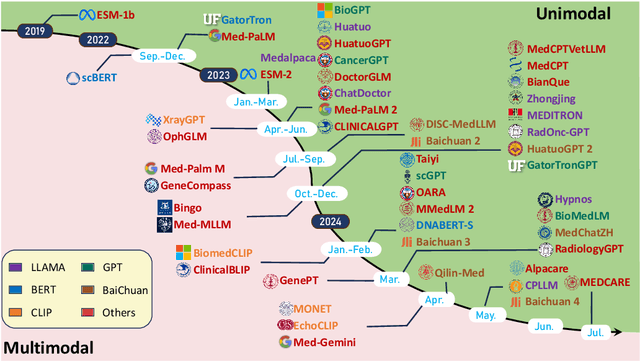
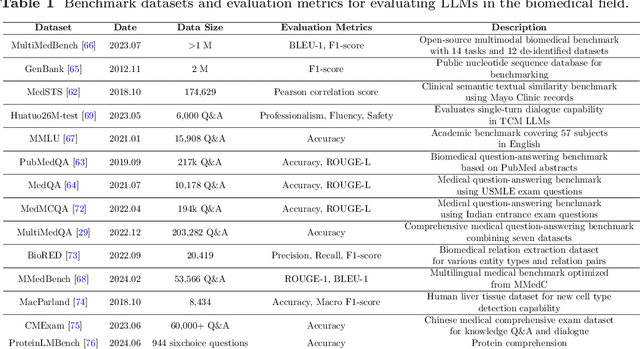
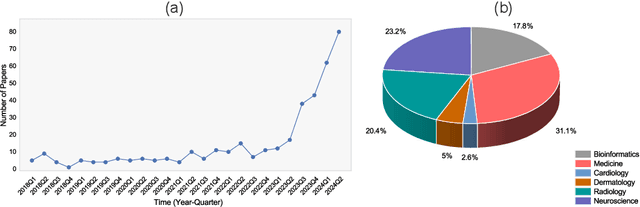
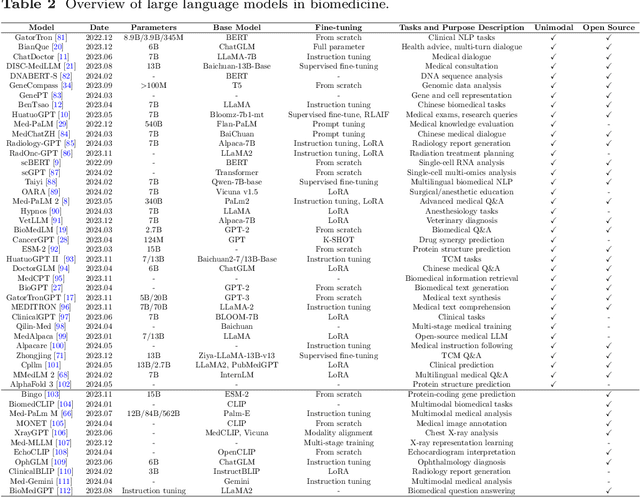
Recent breakthroughs in large language models (LLMs) offer unprecedented natural language understanding and generation capabilities. However, existing surveys on LLMs in biomedicine often focus on specific applications or model architectures, lacking a comprehensive analysis that integrates the latest advancements across various biomedical domains. This review, based on an analysis of 484 publications sourced from databases including PubMed, Web of Science, and arXiv, provides an in-depth examination of the current landscape, applications, challenges, and prospects of LLMs in biomedicine, distinguishing itself by focusing on the practical implications of these models in real-world biomedical contexts. Firstly, we explore the capabilities of LLMs in zero-shot learning across a broad spectrum of biomedical tasks, including diagnostic assistance, drug discovery, and personalized medicine, among others, with insights drawn from 137 key studies. Then, we discuss adaptation strategies of LLMs, including fine-tuning methods for both uni-modal and multi-modal LLMs to enhance their performance in specialized biomedical contexts where zero-shot fails to achieve, such as medical question answering and efficient processing of biomedical literature. Finally, we discuss the challenges that LLMs face in the biomedicine domain including data privacy concerns, limited model interpretability, issues with dataset quality, and ethics due to the sensitive nature of biomedical data, the need for highly reliable model outputs, and the ethical implications of deploying AI in healthcare. To address these challenges, we also identify future research directions of LLM in biomedicine including federated learning methods to preserve data privacy and integrating explainable AI methodologies to enhance the transparency of LLMs.
Automatic Dataset Construction (ADC): Sample Collection, Data Curation, and Beyond
Aug 21, 2024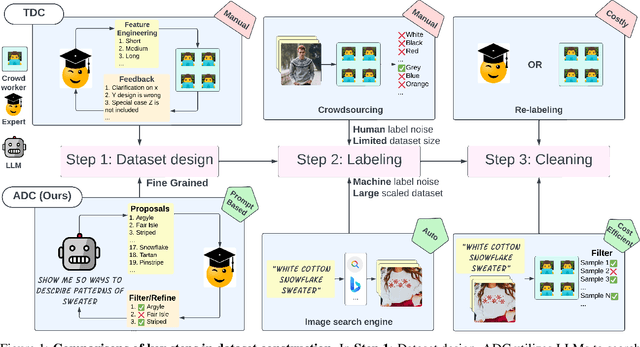

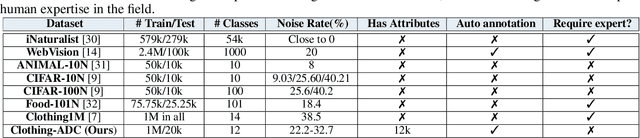
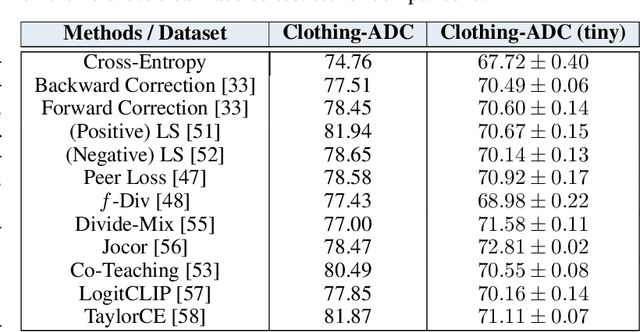
Large-scale data collection is essential for developing personalized training data, mitigating the shortage of training data, and fine-tuning specialized models. However, creating high-quality datasets quickly and accurately remains a challenge due to annotation errors, the substantial time and costs associated with human labor. To address these issues, we propose Automatic Dataset Construction (ADC), an innovative methodology that automates dataset creation with negligible cost and high efficiency. Taking the image classification task as a starting point, ADC leverages LLMs for the detailed class design and code generation to collect relevant samples via search engines, significantly reducing the need for manual annotation and speeding up the data generation process. Despite these advantages, ADC also encounters real-world challenges such as label errors (label noise) and imbalanced data distributions (label bias). We provide open-source software that incorporates existing methods for label error detection, robust learning under noisy and biased data, ensuring a higher-quality training data and more robust model training procedure. Furthermore, we design three benchmark datasets focused on label noise detection, label noise learning, and class-imbalanced learning. These datasets are vital because there are few existing datasets specifically for label noise detection, despite its importance. Finally, we evaluate the performance of existing popular methods on these datasets, thereby facilitating further research in the field.
A Manifold Proximal Linear Method for Sparse Spectral Clustering with Application to Single-Cell RNA Sequencing Data Analysis
Jul 18, 2020

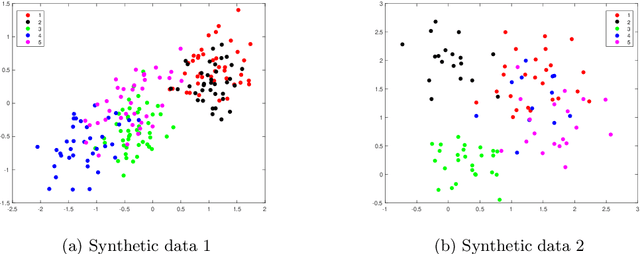
Spectral clustering is one of the fundamental unsupervised learning methods widely used in data analysis. Sparse spectral clustering (SSC) imposes sparsity to the spectral clustering and it improves the interpretability of the model. This paper considers a widely adopted model for SSC, which can be formulated as an optimization problem over the Stiefel manifold with nonsmooth and nonconvex objective. Such an optimization problem is very challenging to solve. Existing methods usually solve its convex relaxation or need to smooth its nonsmooth part using certain smoothing techniques. In this paper, we propose a manifold proximal linear method (ManPL) that solves the original SSC formulation. We also extend the algorithm to solve the multiple-kernel SSC problems, for which an alternating ManPL algorithm is proposed. Convergence and iteration complexity results of the proposed methods are established. We demonstrate the advantage of our proposed methods over existing methods via the single-cell RNA sequencing data analysis.
Zeroth-Order Algorithms for Nonconvex Minimax Problems with Improved Complexities
Jan 22, 2020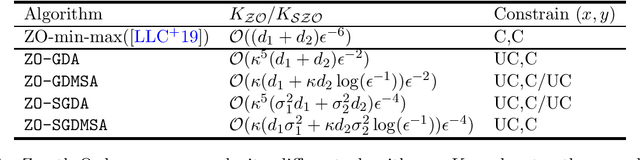
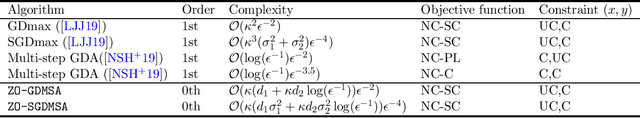
In this paper, we study zeroth-order algorithms for minimax optimization problems that are nonconvex in one variable and strongly-concave in the other variable. Such minimax optimization problems have attracted significant attention lately due to their applications in modern machine learning tasks. We first design and analyze the Zeroth-Order Gradient Descent Ascent (\texttt{ZO-GDA}) algorithm, and provide improved results compared to existing works, in terms of oracle complexity. Next, we propose the Zeroth-Order Gradient Descent Multi-Step Ascent (\texttt{ZO-GDMSA}) algorithm that significantly improves the oracle complexity of \texttt{ZO-GDA}. We also provide stochastic version of \texttt{ZO-GDA} and \texttt{ZO-GDMSA} to handle stochastic nonconvex minimax problems, and provide oracle complexity results.
Nonconvex Stochastic Nested Optimization via Stochastic ADMM
Nov 12, 2019We consider the stochastic nested composition optimization problem where the objective is a composition of two expected-value functions. We proposed the stochastic ADMM to solve this complicated objective. In order to find an $\epsilon$ stationary point where the expected norm of the subgradient of corresponding augmented Lagrangian is smaller than $\epsilon$, the total sample complexity of our method is $\mathcal{O}(\epsilon^{-3})$ for the online case and $\mathcal{O} \Bigl((2N_1 + N_2) + (2N_1 + N_2)^{1/2}\epsilon^{-2}\Bigr)$ for the finite sum case. The computational complexity is consistent with proximal version proposed in \cite{zhang2019multi}, but our algorithm can solve more general problem when the proximal mapping of the penalty is not easy to compute.