 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Distraction in Long-Context Language Models by Focused Learning
Nov 08, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced their capacity to process long contexts. However, effectively utilizing this long context remains a challenge due to the issue of distraction, where irrelevant information dominates lengthy contexts, causing LLMs to lose focus on the most relevant segments. To address this, we propose a novel training method that enhances LLMs' ability to discern relevant information through a unique combination of retrieval-based data augmentation and contrastive learning. Specifically, during fine-tuning with long contexts, we employ a retriever to extract the most relevant segments, serving as augmented inputs. We then introduce an auxiliary contrastive learning objective to explicitly ensure that outputs from the original context and the retrieved sub-context are closely aligned. Extensive experiments on long single-document and multi-document QA benchmarks demonstrate the effectiveness of our proposed method.
Neighbor-Aware Calibration of Segmentation Networks with Penalty-Based Constraints
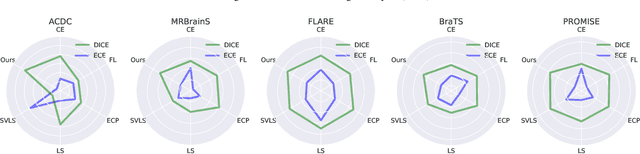
Jan 25, 2024Ensuring reliable confidence scores from deep neural networks is of paramount significance in critical decision-making systems, particularly in real-world domains such as healthcare. Recent literature on calibrating deep segmentation networks has resulted in substantial progress. Nevertheless, these approaches are strongly inspired by the advancements in classification tasks, and thus their uncertainty is usually modeled by leveraging the information of individual pixels, disregarding the local structure of the object of interest. Indeed, only the recent Spatially Varying Label Smoothing (SVLS) approach considers pixel spatial relationships across classes, by softening the pixel label assignments with a discrete spatial Gaussian kernel. In this work, we first present a constrained optimization perspective of SVLS and demonstrate that it enforces an implicit constraint on soft class proportions of surrounding pixels. Furthermore, our analysis shows that SVLS lacks a mechanism to balance the contribution of the constraint with the primary objective, potentially hindering the optimization process. Based on these observations, we propose NACL (Neighbor Aware CaLibration), a principled and simple solution based on equality constraints on the logit values, which enables to control explicitly both the enforced constraint and the weight of the penalty, offering more flexibility. Comprehensive experiments on a wide variety of well-known segmentation benchmarks demonstrate the superior calibration performance of the proposed approach, without affecting its discriminative power. Furthermore, ablation studies empirically show the model agnostic nature of our approach, which can be used to train a wide span of deep segmentation networks.
Trust your neighbours: Penalty-based constraints for model calibration
Mar 11, 2023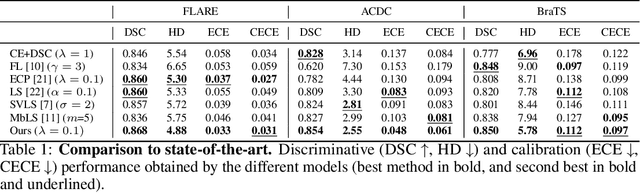

Ensuring reliable confidence scores from deep networks is of pivotal importance in critical decision-making systems, notably in the medical domain. While recent literature on calibrating deep segmentation networks has led to significant progress, their uncertainty is usually modeled by leveraging the information of individual pixels, which disregards the local structure of the object of interest. In particular, only the recent Spatially Varying Label Smoothing (SVLS) approach addresses this issue by softening the pixel label assignments with a discrete spatial Gaussian kernel. In this work, we first present a constrained optimization perspective of SVLS and demonstrate that it enforces an implicit constraint on soft class proportions of surrounding pixels. Furthermore, our analysis shows that SVLS lacks a mechanism to balance the contribution of the constraint with the primary objective, potentially hindering the optimization process. Based on these observations, we propose a principled and simple solution based on equality constraints on the logit values, which enables to control explicitly both the enforced constraint and the weight of the penalty, offering more flexibility. Comprehensive experiments on a variety of well-known segmentation benchmarks demonstrate the superior performance of the proposed approach.
Class Adaptive Network Calibration
Nov 28, 2022
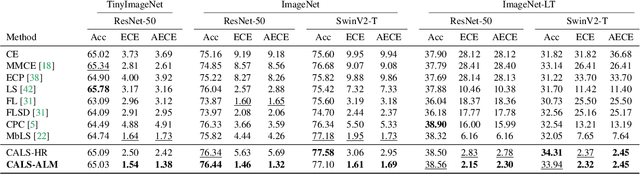
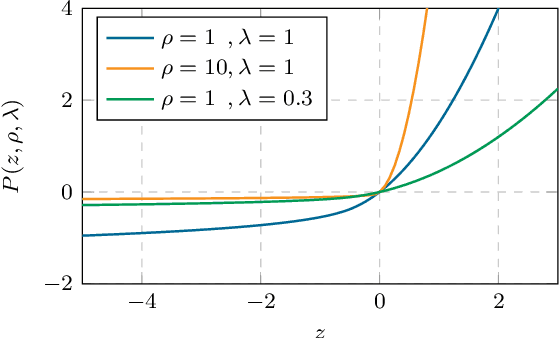
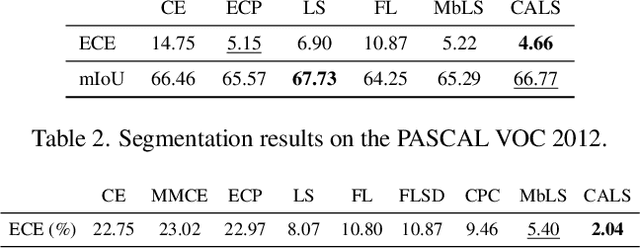
Recent studies have revealed that, beyond conventional accuracy, calibration should also be considered for training modern deep neural networks. To address miscalibration during learning, some methods have explored different penalty functions as part of the learning objective, alongside a standard classification loss, with a hyper-parameter controlling the relative contribution of each term. Nevertheless, these methods share two major drawbacks: 1) the scalar balancing weight is the same for all classes, hindering the ability to address different intrinsic difficulties or imbalance among classes; and 2) the balancing weight is usually fixed without an adaptive strategy, which may prevent from reaching the best compromise between accuracy and calibration, and requires hyper-parameter search for each application. We propose Class Adaptive Label Smoothing (CALS) for calibrating deep networks, which allows to learn class-wise multipliers during training, yielding a powerful alternative to common label smoothing penalties. Our method builds on a general Augmented Lagrangian approach, a well-established technique in constrained optimization, but we introduce several modifications to tailor it for large-scale, class-adaptive training. Comprehensive evaluation and multiple comparisons on a variety of benchmarks, including standard and long-tailed image classification, semantic segmentation, and text classification, demonstrate the superiority of the proposed method. The code is available at https://github.com/by-liu/CALS.
Calibrating Segmentation Networks with Margin-based Label Smoothing
Sep 09, 2022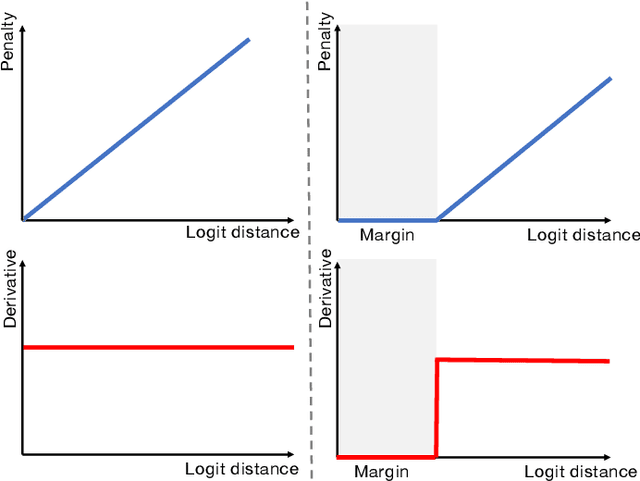
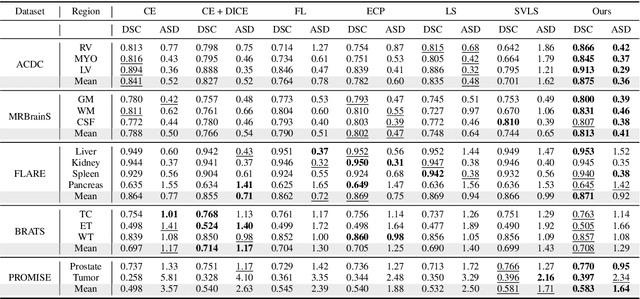

Despite the undeniable progress in visual recognition tasks fueled by deep neural networks, there exists recent evidence showing that these models are poorly calibrated, resulting in over-confident predictions. The standard practices of minimizing the cross entropy loss during training promote the predicted softmax probabilities to match the one-hot label assignments. Nevertheless, this yields a pre-softmax activation of the correct class that is significantly larger than the remaining activations, which exacerbates the miscalibration problem. Recent observations from the classification literature suggest that loss functions that embed implicit or explicit maximization of the entropy of predictions yield state-of-the-art calibration performances. Despite these findings, the impact of these losses in the relevant task of calibrating medical image segmentation networks remains unexplored. In this work, we provide a unifying constrained-optimization perspective of current state-of-the-art calibration losses. Specifically, these losses could be viewed as approximations of a linear penalty (or a Lagrangian term) imposing equality constraints on logit distances. This points to an important limitation of such underlying equality constraints, whose ensuing gradients constantly push towards a non-informative solution, which might prevent from reaching the best compromise between the discriminative performance and calibration of the model during gradient-based optimization. Following our observations, we propose a simple and flexible generalization based on inequality constraints, which imposes a controllable margin on logit distances. Comprehensive experiments on a variety of public medical image segmentation benchmarks demonstrate that our method sets novel state-of-the-art results on these tasks in terms of network calibration, whereas the discriminative performance is also improved.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022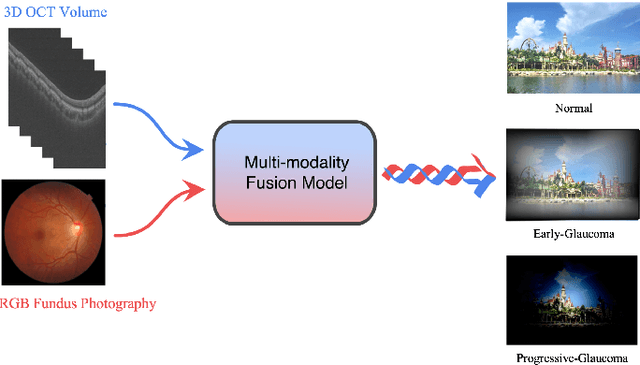
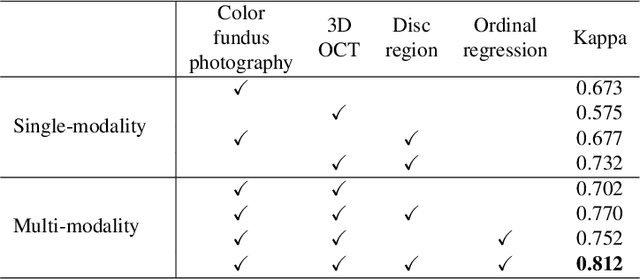
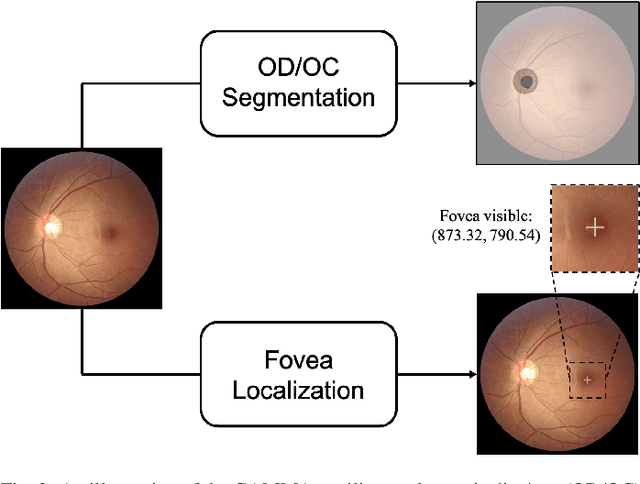
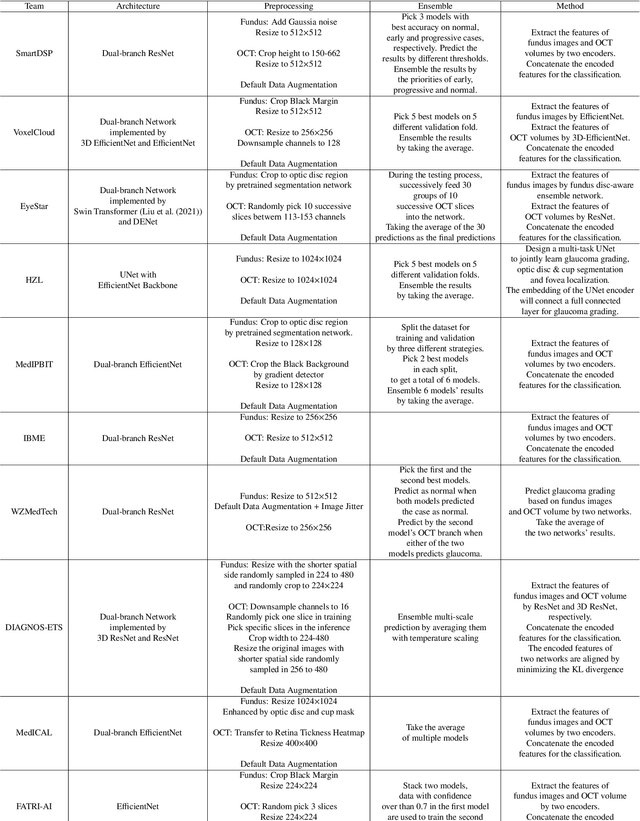
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
The Devil is in the Margin: Margin-based Label Smoothing for Network Calibration
Nov 30, 2021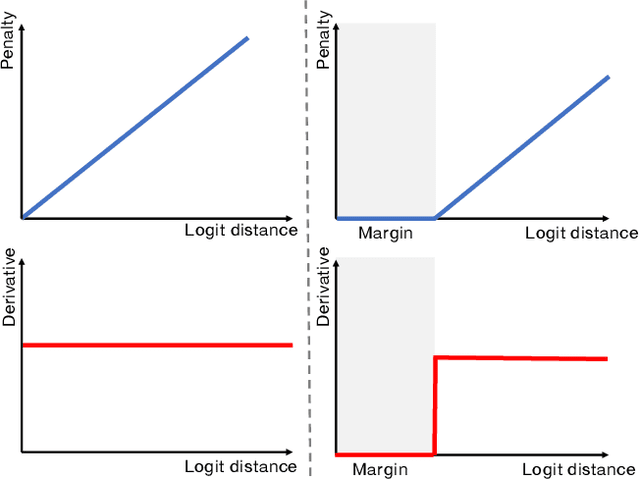



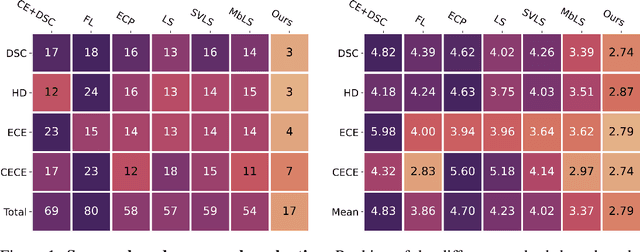
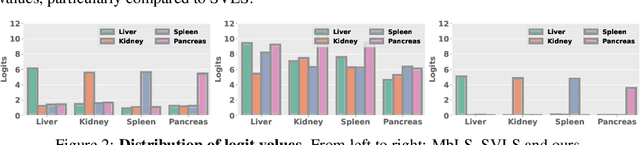
In spite of the dominant performances of deep neural networks, recent works have shown that they are poorly calibrated, resulting in over-confident predictions. Miscalibration can be exacerbated by overfitting due to the minimization of the cross-entropy during training, as it promotes the predicted softmax probabilities to match the one-hot label assignments. This yields a pre-softmax activation of the correct class that is significantly larger than the remaining activations. Recent evidence from the literature suggests that loss functions that embed implicit or explicit maximization of the entropy of predictions yield state-of-the-art calibration performances. We provide a unifying constrained-optimization perspective of current state-of-the-art calibration losses. Specifically, these losses could be viewed as approximations of a linear penalty (or a Lagrangian) imposing equality constraints on logit distances. This points to an important limitation of such underlying equality constraints, whose ensuing gradients constantly push towards a non-informative solution, which might prevent from reaching the best compromise between the discriminative performance and calibration of the model during gradient-based optimization. Following our observations, we propose a simple and flexible generalization based on inequality constraints, which imposes a controllable margin on logit distances. Comprehensive experiments on a variety of image classification, semantic segmentation and NLP benchmarks demonstrate that our method sets novel state-of-the-art results on these tasks in terms of network calibration, without affecting the discriminative performance. The code is available at https://github.com/by-liu/MbLS .
Robust High-Dimensional Regression with Coefficient Thresholding and its Application to Imaging Data Analysis
Sep 30, 2021
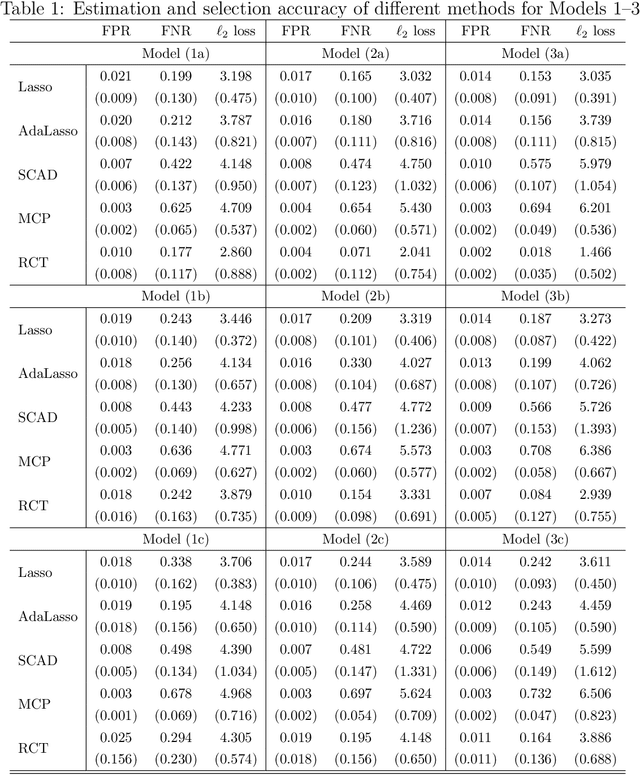

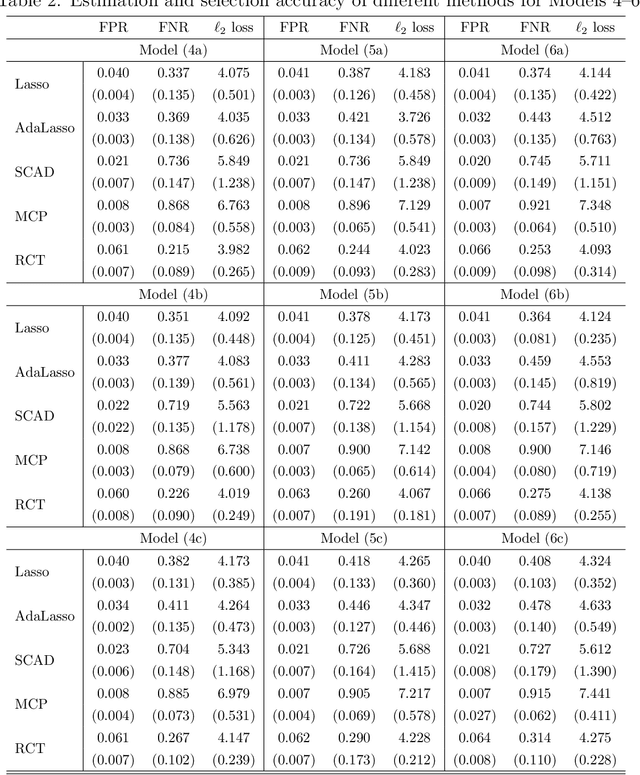
It is of importance to develop statistical techniques to analyze high-dimensional data in the presence of both complex dependence and possible outliers in real-world applications such as imaging data analyses. We propose a new robust high-dimensional regression with coefficient thresholding, in which an efficient nonconvex estimation procedure is proposed through a thresholding function and the robust Huber loss. The proposed regularization method accounts for complex dependence structures in predictors and is robust against outliers in outcomes. Theoretically, we analyze rigorously the landscape of the population and empirical risk functions for the proposed method. The fine landscape enables us to establish both {statistical consistency and computational convergence} under the high-dimensional setting. The finite-sample properties of the proposed method are examined by extensive simulation studies. An illustration of real-world application concerns a scalar-on-image regression analysis for an association of psychiatric disorder measured by the general factor of psychopathology with features extracted from the task functional magnetic resonance imaging data in the Adolescent Brain Cognitive Development study.
Mixed-supervised segmentation: Confidence maximization helps knowledge distillation
Sep 24, 2021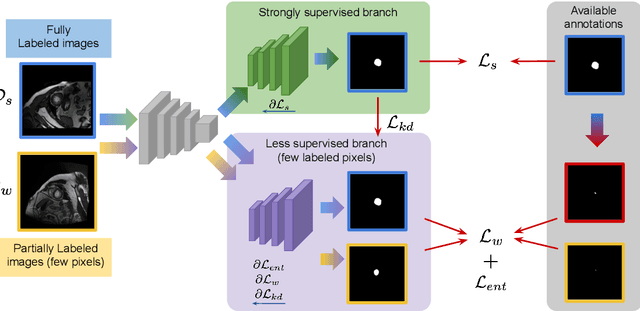
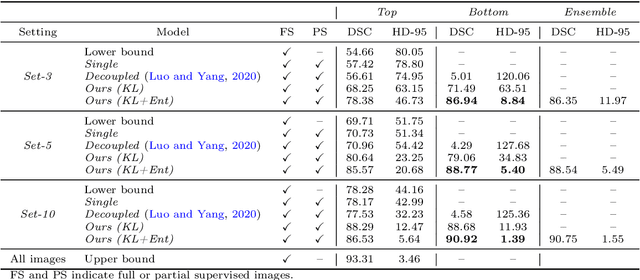

Despite achieving promising results in a breadth of medical image segmentation tasks, deep neural networks require large training datasets with pixel-wise annotations. Obtaining these curated datasets is a cumbersome process which limits the application in scenarios where annotated images are scarce. Mixed supervision is an appealing alternative for mitigating this obstacle, where only a small fraction of the data contains complete pixel-wise annotations and other images have a weaker form of supervision. In this work, we propose a dual-branch architecture, where the upper branch (teacher) receives strong annotations, while the bottom one (student) is driven by limited supervision and guided by the upper branch. Combined with a standard cross-entropy loss over the labeled pixels, our novel formulation integrates two important terms: (i) a Shannon entropy loss defined over the less-supervised images, which encourages confident student predictions in the bottom branch; and (ii) a Kullback-Leibler (KL) divergence term, which transfers the knowledge of the strongly supervised branch to the less-supervised branch and guides the entropy (student-confidence) term to avoid trivial solutions. We show that the synergy between the entropy and KL divergence yields substantial improvements in performance. We also discuss an interesting link between Shannon-entropy minimization and standard pseudo-mask generation, and argue that the former should be preferred over the latter for leveraging information from unlabeled pixels. Quantitative and qualitative results on two publicly available datasets demonstrate that our method significantly outperforms other strategies for semantic segmentation within a mixed-supervision framework, as well as recent semi-supervised approaches. Moreover, we show that the branch trained with reduced supervision and guided by the top branch largely outperforms the latter.
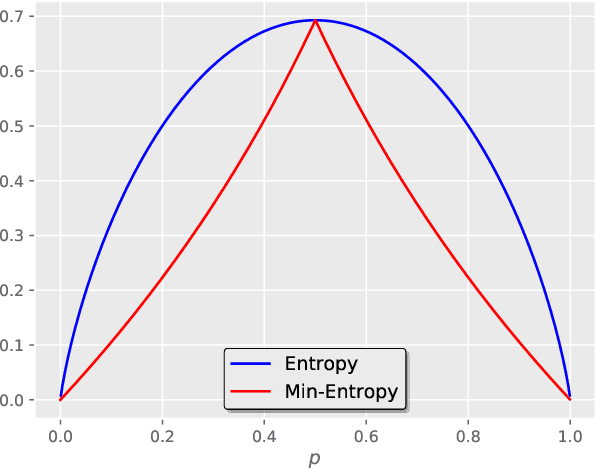
The hidden label-marginal biases of segmentation losses
Apr 18, 2021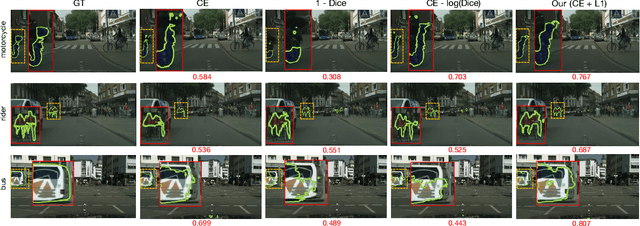
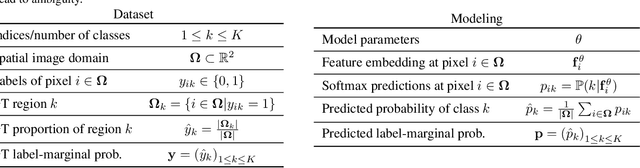
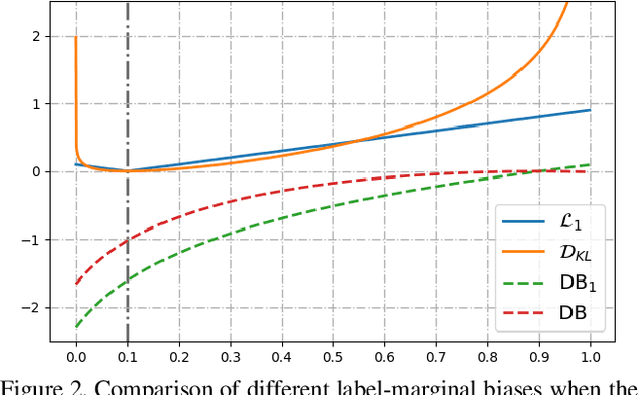
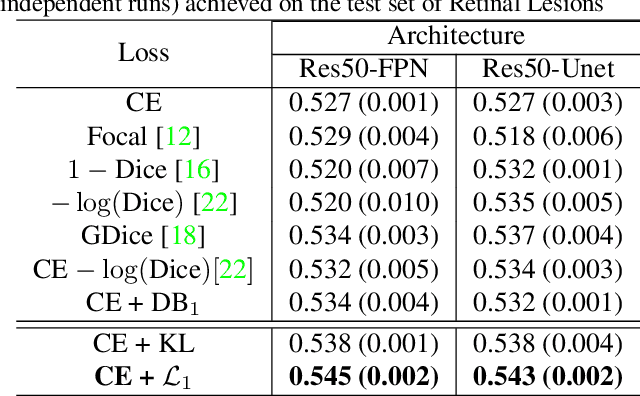
Most segmentation losses are arguably variants of the Cross-Entropy (CE) or Dice loss. In the literature, there is no clear consensus as to which of these losses is a better choice, with varying performances for each across different benchmarks and applications. We develop a theoretical analysis that links these two types of losses, exposing their advantages and weaknesses. First, we explicitly demonstrate that CE and Dice share a much deeper connection than previously thought: CE is an upper bound on both logarithmic and linear Dice losses. Furthermore, we provide an information-theoretic analysis, which highlights hidden label-marginal biases : Dice has an intrinsic bias towards imbalanced solutions, whereas CE implicitly encourages the ground-truth region proportions. Our theoretical results explain the wide experimental evidence in the medical-imaging literature, whereby Dice losses bring improvements for imbalanced segmentation. It also explains why CE dominates natural-image problems with diverse class proportions, in which case Dice might have difficulty adapting to different label-marginal distributions. Based on our theoretical analysis, we propose a principled and simple solution, which enables to control explicitly the label-marginal bias. Our loss integrates CE with explicit ${\cal L}_1$ regularization, which encourages label marginals to match target class proportions, thereby mitigating class imbalance but without losing generality. Comprehensive experiments and ablation studies over different losses and applications validate our theoretical analysis, as well as the effectiveness of our explicit label-marginal regularizers.