 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Margin: Margin-based Label Smoothing for Network Calibration
Paper and Code
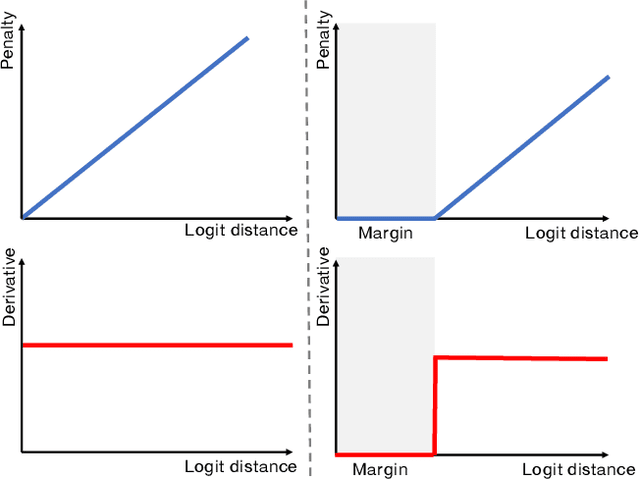



In spite of the dominant performances of deep neural networks, recent works have shown that they are poorly calibrated, resulting in over-confident predictions. Miscalibration can be exacerbated by overfitting due to the minimization of the cross-entropy during training, as it promotes the predicted softmax probabilities to match the one-hot label assignments. This yields a pre-softmax activation of the correct class that is significantly larger than the remaining activations. Recent evidence from the literature suggests that loss functions that embed implicit or explicit maximization of the entropy of predictions yield state-of-the-art calibration performances. We provide a unifying constrained-optimization perspective of current state-of-the-art calibration losses. Specifically, these losses could be viewed as approximations of a linear penalty (or a Lagrangian) imposing equality constraints on logit distances. This points to an important limitation of such underlying equality constraints, whose ensuing gradients constantly push towards a non-informative solution, which might prevent from reaching the best compromise between the discriminative performance and calibration of the model during gradient-based optimization. Following our observations, we propose a simple and flexible generalization based on inequality constraints, which imposes a controllable margin on logit distances. Comprehensive experiments on a variety of image classification, semantic segmentation and NLP benchmarks demonstrate that our method sets novel state-of-the-art results on these tasks in terms of network calibration, without affecting the discriminative performance. The code is available at https://github.com/by-liu/MbLS .