 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKDPhys: An Attention Guided 3D to 2D Knowledge Distillation for Real-time Video-Based Physiological Measurement
Jan 02, 2026Camera-based physiological monitoring, such as remote photoplethysmography (rPPG), captures subtle variations in skin optical properties caused by pulsatile blood volume changes using standard digital camera sensors. The demand for real-time, non-contact physiological measurement has increased significantly, particularly during the SARS-CoV-2 pandemic, to support telehealth and remote health monitoring applications. In this work, we propose an attention-based knowledge distillation (KD) framework, termed KDPhys, for extracting rPPG signals from facial video sequences. The proposed method distills global temporal representations from a 3D convolutional neural network (CNN) teacher model to a lightweight 2D CNN student model through effective 3D-to-2D feature distillation. To the best of our knowledge, this is the first application of knowledge distillation in the rPPG domain. Furthermore, we introduce a Distortion Loss incorporating Shape and Time (DILATE), which jointly accounts for both morphological and temporal characteristics of rPPG signals. Extensive qualitative and quantitative evaluations are conducted on three benchmark datasets. The proposed model achieves a significant reduction in computational complexity, using only half the parameters of existing methods while operating 56.67% faster. With just 0.23M parameters, it achieves an 18.15% reduction in Mean Absolute Error (MAE) compared to state-of-the-art approaches, attaining an average MAE of 1.78 bpm across all datasets. Additional experiments under diverse environmental conditions and activity scenarios further demonstrate the robustness and adaptability of the proposed approach.
* This paper has been published in Biomedical Signal Processing and Control
Robust Calibration of Large Vision-Language Adapters
Jul 18, 2024This paper addresses the critical issue of miscalibration in CLIP-based model adaptation, particularly in the challenging scenario of out-of-distribution (OOD) samples, which has been overlooked in the existing literature on CLIP adaptation. We empirically demonstrate that popular CLIP adaptation approaches, such as Adapters, Prompt Learning, and Test-Time Adaptation, substantially degrade the calibration capabilities of the zero-shot baseline in the presence of distributional drift. We identify the increase in logit ranges as the underlying cause of miscalibration of CLIP adaptation methods, contrasting with previous work on calibrating fully-supervised models. Motivated by these observations, we present a simple and model-agnostic solution to mitigate miscalibration, by scaling the logit range of each sample to its zero-shot prediction logits. We explore three different alternatives to achieve this, which can be either integrated during adaptation or directly used at inference time. Comprehensive experiments on popular OOD classification benchmarks demonstrate the effectiveness of the proposed approaches in mitigating miscalibration while maintaining discriminative performance, whose improvements are consistent across the three families of these increasingly popular approaches. The code is publicly available at: https://github.com/Bala93/CLIPCalib
Do not trust what you trust: Miscalibration in Semi-supervised Learning
Mar 22, 2024State-of-the-art semi-supervised learning (SSL) approaches rely on highly confident predictions to serve as pseudo-labels that guide the training on unlabeled samples. An inherent drawback of this strategy stems from the quality of the uncertainty estimates, as pseudo-labels are filtered only based on their degree of uncertainty, regardless of the correctness of their predictions. Thus, assessing and enhancing the uncertainty of network predictions is of paramount importance in the pseudo-labeling process. In this work, we empirically demonstrate that SSL methods based on pseudo-labels are significantly miscalibrated, and formally demonstrate the minimization of the min-entropy, a lower bound of the Shannon entropy, as a potential cause for miscalibration. To alleviate this issue, we integrate a simple penalty term, which enforces the logit distances of the predictions on unlabeled samples to remain low, preventing the network predictions to become overconfident. Comprehensive experiments on a variety of SSL image classification benchmarks demonstrate that the proposed solution systematically improves the calibration performance of relevant SSL models, while also enhancing their discriminative power, being an appealing addition to tackle SSL tasks.
Class and Region-Adaptive Constraints for Network Calibration
Mar 19, 2024In this work, we present a novel approach to calibrate segmentation networks that considers the inherent challenges posed by different categories and object regions. In particular, we present a formulation that integrates class and region-wise constraints into the learning objective, with multiple penalty weights to account for class and region differences. Finding the optimal penalty weights manually, however, might be unfeasible, and potentially hinder the optimization process. To overcome this limitation, we propose an approach based on Class and Region-Adaptive constraints (CRaC), which allows to learn the class and region-wise penalty weights during training. CRaC is based on a general Augmented Lagrangian method, a well-established technique in constrained optimization. Experimental results on two popular segmentation benchmarks, and two well-known segmentation networks, demonstrate the superiority of CRaC compared to existing approaches. The code is available at: https://github.com/Bala93/CRac/
Neighbor-Aware Calibration of Segmentation Networks with Penalty-Based Constraints
Jan 25, 2024Ensuring reliable confidence scores from deep neural networks is of paramount significance in critical decision-making systems, particularly in real-world domains such as healthcare. Recent literature on calibrating deep segmentation networks has resulted in substantial progress. Nevertheless, these approaches are strongly inspired by the advancements in classification tasks, and thus their uncertainty is usually modeled by leveraging the information of individual pixels, disregarding the local structure of the object of interest. Indeed, only the recent Spatially Varying Label Smoothing (SVLS) approach considers pixel spatial relationships across classes, by softening the pixel label assignments with a discrete spatial Gaussian kernel. In this work, we first present a constrained optimization perspective of SVLS and demonstrate that it enforces an implicit constraint on soft class proportions of surrounding pixels. Furthermore, our analysis shows that SVLS lacks a mechanism to balance the contribution of the constraint with the primary objective, potentially hindering the optimization process. Based on these observations, we propose NACL (Neighbor Aware CaLibration), a principled and simple solution based on equality constraints on the logit values, which enables to control explicitly both the enforced constraint and the weight of the penalty, offering more flexibility. Comprehensive experiments on a wide variety of well-known segmentation benchmarks demonstrate the superior calibration performance of the proposed approach, without affecting its discriminative power. Furthermore, ablation studies empirically show the model agnostic nature of our approach, which can be used to train a wide span of deep segmentation networks.
Prompting classes: Exploring the Power of Prompt Class Learning in Weakly Supervised Semantic Segmentation
Jul 08, 2023Recently, CLIP-based approaches have exhibited remarkable performance on generalization and few-shot learning tasks, fueled by the power of contrastive language-vision pre-training. In particular, prompt tuning has emerged as an effective strategy to adapt the pre-trained language-vision models to downstream tasks by employing task-related textual tokens. Motivated by this progress, in this work we question whether other fundamental problems, such as weakly supervised semantic segmentation (WSSS), can benefit from prompt tuning. Our findings reveal two interesting observations that shed light on the impact of prompt tuning on WSSS. First, modifying only the class token of the text prompt results in a greater impact on the Class Activation Map (CAM), compared to arguably more complex strategies that optimize the context. And second, the class token associated with the image ground truth does not necessarily correspond to the category that yields the best CAM. Motivated by these observations, we introduce a novel approach based on a PrOmpt cLass lEarning (POLE) strategy. Through extensive experiments we demonstrate that our simple, yet efficient approach achieves SOTA performance in a well-known WSSS benchmark. These results highlight not only the benefits of language-vision models in WSSS but also the potential of prompt learning for this problem. The code is available at https://github.com/rB080/WSS_POLE.
Trust your neighbours: Penalty-based constraints for model calibration
Mar 11, 2023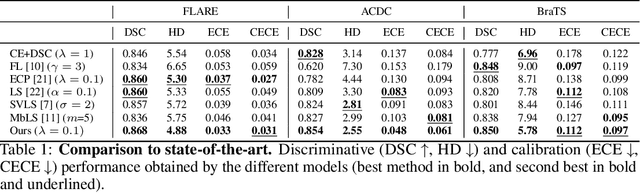
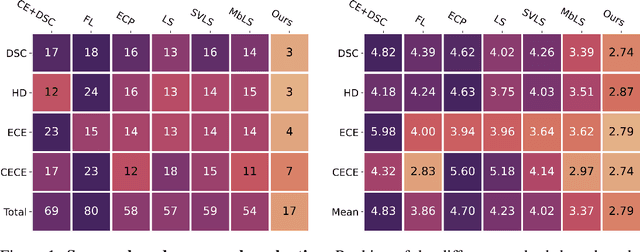

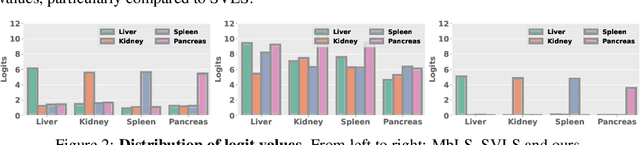
Ensuring reliable confidence scores from deep networks is of pivotal importance in critical decision-making systems, notably in the medical domain. While recent literature on calibrating deep segmentation networks has led to significant progress, their uncertainty is usually modeled by leveraging the information of individual pixels, which disregards the local structure of the object of interest. In particular, only the recent Spatially Varying Label Smoothing (SVLS) approach addresses this issue by softening the pixel label assignments with a discrete spatial Gaussian kernel. In this work, we first present a constrained optimization perspective of SVLS and demonstrate that it enforces an implicit constraint on soft class proportions of surrounding pixels. Furthermore, our analysis shows that SVLS lacks a mechanism to balance the contribution of the constraint with the primary objective, potentially hindering the optimization process. Based on these observations, we propose a principled and simple solution based on equality constraints on the logit values, which enables to control explicitly both the enforced constraint and the weight of the penalty, offering more flexibility. Comprehensive experiments on a variety of well-known segmentation benchmarks demonstrate the superior performance of the proposed approach.
Calibrating Segmentation Networks with Margin-based Label Smoothing
Sep 09, 2022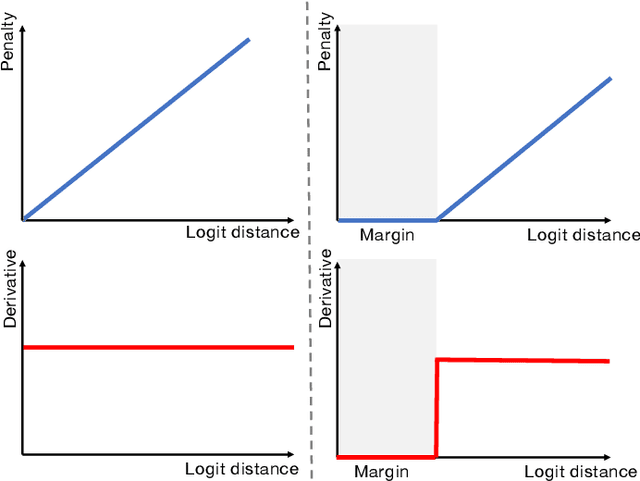
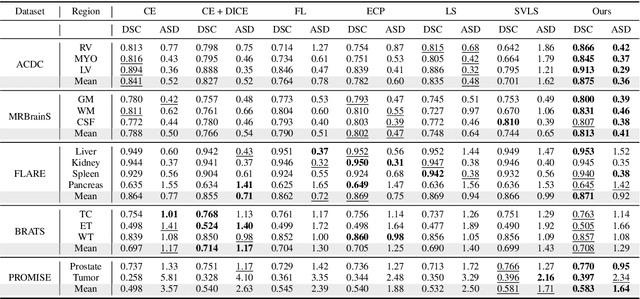

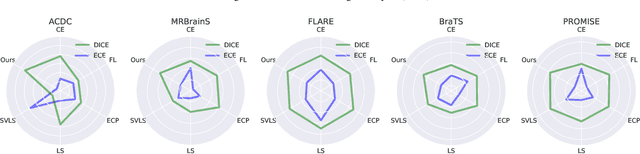
Despite the undeniable progress in visual recognition tasks fueled by deep neural networks, there exists recent evidence showing that these models are poorly calibrated, resulting in over-confident predictions. The standard practices of minimizing the cross entropy loss during training promote the predicted softmax probabilities to match the one-hot label assignments. Nevertheless, this yields a pre-softmax activation of the correct class that is significantly larger than the remaining activations, which exacerbates the miscalibration problem. Recent observations from the classification literature suggest that loss functions that embed implicit or explicit maximization of the entropy of predictions yield state-of-the-art calibration performances. Despite these findings, the impact of these losses in the relevant task of calibrating medical image segmentation networks remains unexplored. In this work, we provide a unifying constrained-optimization perspective of current state-of-the-art calibration losses. Specifically, these losses could be viewed as approximations of a linear penalty (or a Lagrangian term) imposing equality constraints on logit distances. This points to an important limitation of such underlying equality constraints, whose ensuing gradients constantly push towards a non-informative solution, which might prevent from reaching the best compromise between the discriminative performance and calibration of the model during gradient-based optimization. Following our observations, we propose a simple and flexible generalization based on inequality constraints, which imposes a controllable margin on logit distances. Comprehensive experiments on a variety of public medical image segmentation benchmarks demonstrate that our method sets novel state-of-the-art results on these tasks in terms of network calibration, whereas the discriminative performance is also improved.
Deep learning based non-contact physiological monitoring in Neonatal Intensive Care Unit
Jul 25, 2022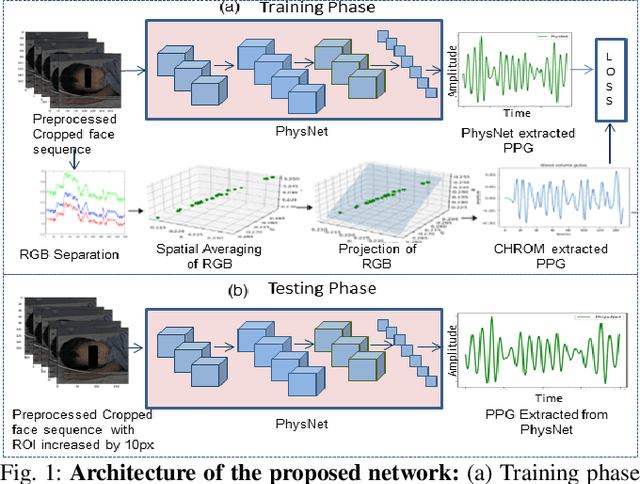
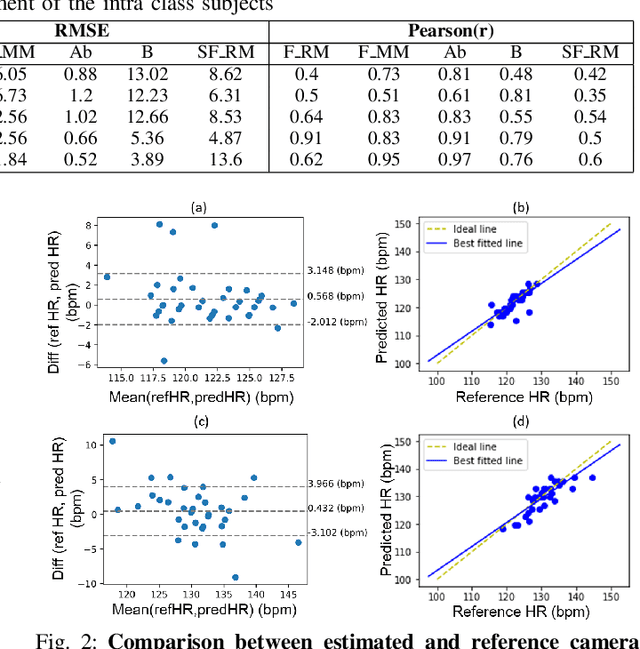
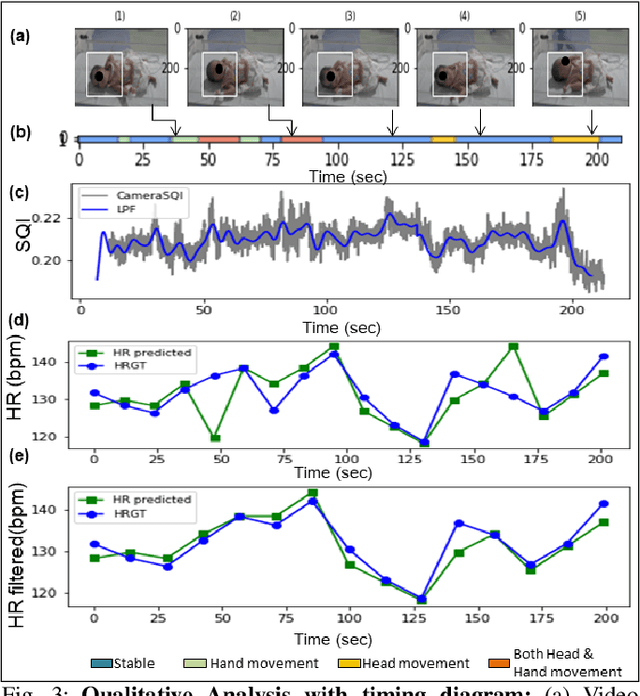
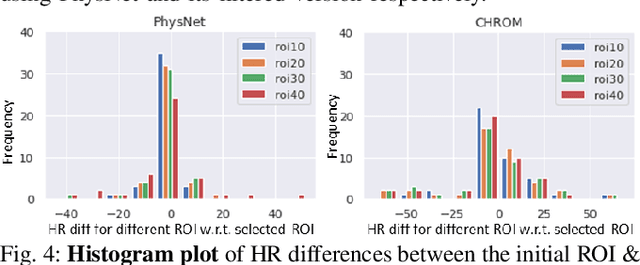
Preterm babies in the Neonatal Intensive Care Unit (NICU) have to undergo continuous monitoring of their cardiac health. Conventional monitoring approaches are contact-based, making the neonates prone to various nosocomial infections. Video-based monitoring approaches have opened up potential avenues for contactless measurement. This work presents a pipeline for remote estimation of cardiopulmonary signals from videos in NICU setup. We have proposed an end-to-end deep learning (DL) model that integrates a non-learning based approach to generate surrogate ground truth (SGT) labels for supervision, thus refraining from direct dependency on true ground truth labels. We have performed an extended qualitative and quantitative analysis to examine the efficacy of our proposed DL-based pipeline and achieved an overall average mean absolute error of 4.6 beats per minute (bpm) and root mean square error of 6.2 bpm in the estimated heart rate.
A deep cascade of ensemble of dual domain networks with gradient-based T1 assistance and perceptual refinement for fast MRI reconstruction
Jul 05, 2022
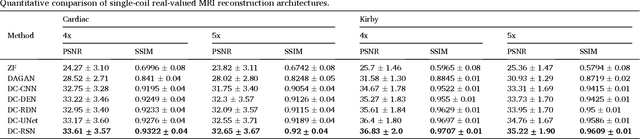
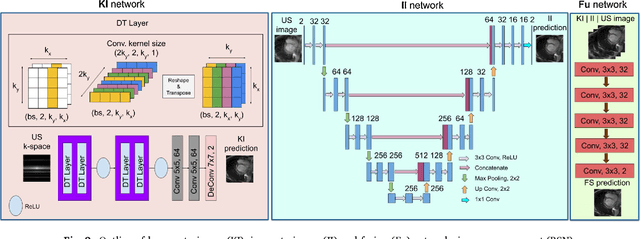
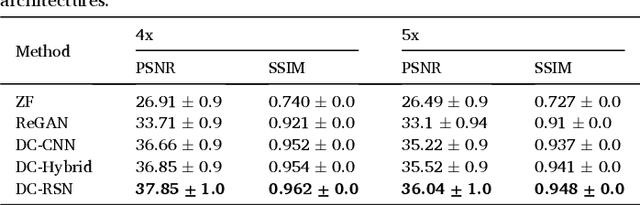
Deep learning networks have shown promising results in fast magnetic resonance imaging (MRI) reconstruction. In our work, we develop deep networks to further improve the quantitative and the perceptual quality of reconstruction. To begin with, we propose reconsynergynet (RSN), a network that combines the complementary benefits of independently operating on both the image and the Fourier domain. For a single-coil acquisition, we introduce deep cascade RSN (DC-RSN), a cascade of RSN blocks interleaved with data fidelity (DF) units. Secondly, we improve the structure recovery of DC-RSN for T2 weighted Imaging (T2WI) through assistance of T1 weighted imaging (T1WI), a sequence with short acquisition time. T1 assistance is provided to DC-RSN through a gradient of log feature (GOLF) fusion. Furthermore, we propose perceptual refinement network (PRN) to refine the reconstructions for better visual information fidelity (VIF), a metric highly correlated to radiologists opinion on the image quality. Lastly, for multi-coil acquisition, we propose variable splitting RSN (VS-RSN), a deep cascade of blocks, each block containing RSN, multi-coil DF unit, and a weighted average module. We extensively validate our models DC-RSN and VS-RSN for single-coil and multi-coil acquisitions and report the state-of-the-art performance. We obtain a SSIM of 0.768, 0.923, 0.878 for knee single-coil-4x, multi-coil-4x, and multi-coil-8x in fastMRI. We also conduct experiments to demonstrate the efficacy of GOLF based T1 assistance and PRN.