 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAD-DCE: An Aggregated Multimodal Attention Mechanism for Early and Late Dynamic Contrast Enhanced Prostate MRI Synthesis
Feb 04, 2025Dynamic Contrast-Enhanced Magnetic Resonance Imaging (DCE-MRI) is a medical imaging technique that plays a crucial role in the detailed visualization and identification of tissue perfusion in abnormal lesions and radiological suggestions for biopsy. However, DCE-MRI involves the administration of a Gadolinium based (Gad) contrast agent, which is associated with a risk of toxicity in the body. Previous deep learning approaches that synthesize DCE-MR images employ unimodal non-contrast or low-dose contrast MRI images lacking focus on the local perfusion information within the anatomy of interest. We propose AAD-DCE, a generative adversarial network (GAN) with an aggregated attention discriminator module consisting of global and local discriminators. The discriminators provide a spatial embedded attention map to drive the generator to synthesize early and late response DCE-MRI images. Our method employs multimodal inputs - T2 weighted (T2W), Apparent Diffusion Coefficient (ADC), and T1 pre-contrast for image synthesis. Extensive comparative and ablation studies on the ProstateX dataset show that our model (i) is agnostic to various generator benchmarks and (ii) outperforms other DCE-MRI synthesis approaches with improvement margins of +0.64 dB PSNR, +0.0518 SSIM, -0.015 MAE for early response and +0.1 dB PSNR, +0.0424 SSIM, -0.021 MAE for late response, and (ii) emphasize the importance of attention ensembling. Our code is available at https://github.com/bhartidivya/AAD-DCE.
DCE-FORMER: A Transformer-based Model With Mutual Information And Frequency-based Loss Functions For Early And Late Response Prediction In Prostate DCE-MRI
Feb 03, 2024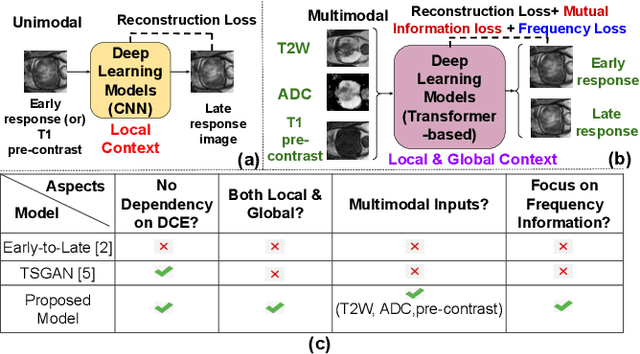
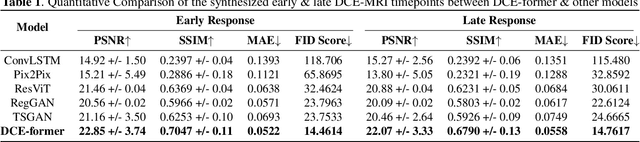
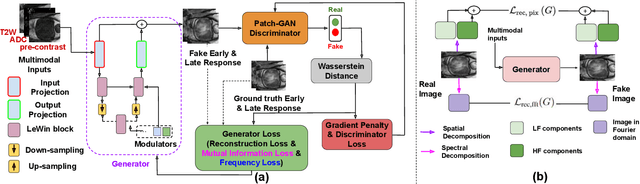
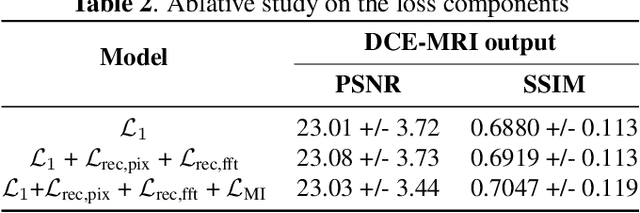
Dynamic Contrast Enhanced Magnetic Resonance Imaging aids in the detection and assessment of tumor aggressiveness by using a Gadolinium-based contrast agent (GBCA). However, GBCA is known to have potential toxic effects. This risk can be avoided if we obtain DCE-MRI images without using GBCA. We propose, DCE-former, a transformer-based neural network to generate early and late response prostate DCE-MRI images from non-contrast multimodal inputs (T2 weighted, Apparent Diffusion Coefficient, and T1 pre-contrast MRI). Additionally, we introduce (i) a mutual information loss function to capture the complementary information about contrast uptake, and (ii) a frequency-based loss function in the pixel and Fourier space to learn local and global hyper-intensity patterns in DCE-MRI. Extensive experiments show that DCE-former outperforms other methods with improvement margins of +1.39 dB and +1.19 db in PSNR, +0.068 and +0.055 in SSIM, and -0.012 and -0.013 in Mean Absolute Error for early and late response DCE-MRI, respectively.
HyperCoil-Recon: A Hypernetwork-based Adaptive Coil Configuration Task Switching Network for MRI Reconstruction
Aug 09, 2023

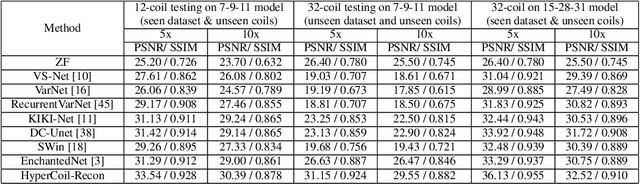

Parallel imaging, a fast MRI technique, involves dynamic adjustments based on the configuration i.e. number, positioning, and sensitivity of the coils with respect to the anatomy under study. Conventional deep learning-based image reconstruction models have to be trained or fine-tuned for each configuration, posing a barrier to clinical translation, given the lack of computational resources and machine learning expertise for clinicians to train models at deployment. Joint training on diverse datasets learns a single weight set that might underfit to deviated configurations. We propose, HyperCoil-Recon, a hypernetwork-based coil configuration task-switching network for multi-coil MRI reconstruction that encodes varying configurations of the numbers of coils in a multi-tasking perspective, posing each configuration as a task. The hypernetworks infer and embed task-specific weights into the reconstruction network, 1) effectively utilizing the contextual knowledge of common and varying image features among the various fields-of-view of the coils, and 2) enabling generality to unseen configurations at test time. Experiments reveal that our approach 1) adapts on the fly to various unseen configurations up to 32 coils when trained on lower numbers (i.e. 7 to 11) of randomly varying coils, and to 120 deviated unseen configurations when trained on 18 configurations in a single model, 2) matches the performance of coil configuration-specific models, and 3) outperforms configuration-invariant models with improvement margins of around 1 dB / 0.03 and 0.3 dB / 0.02 in PSNR / SSIM for knee and brain data. Our code is available at https://github.com/sriprabhar/HyperCoil-Recon
Generalizing Supervised Deep Learning MRI Reconstruction to Multiple and Unseen Contrasts using Meta-Learning Hypernetworks
Jul 13, 2023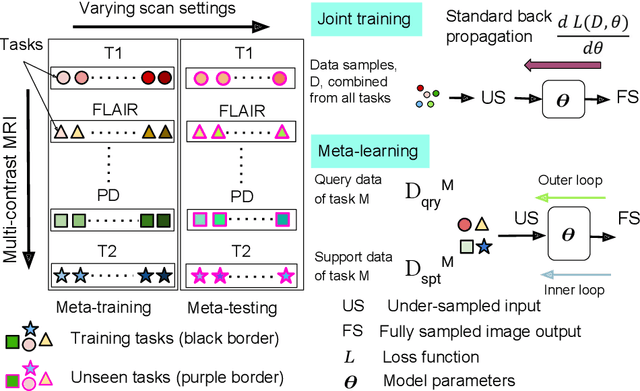
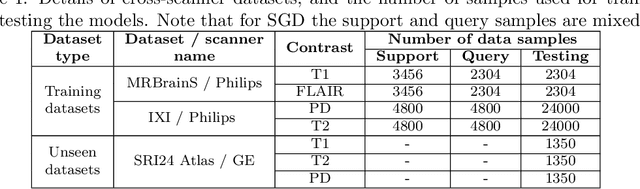
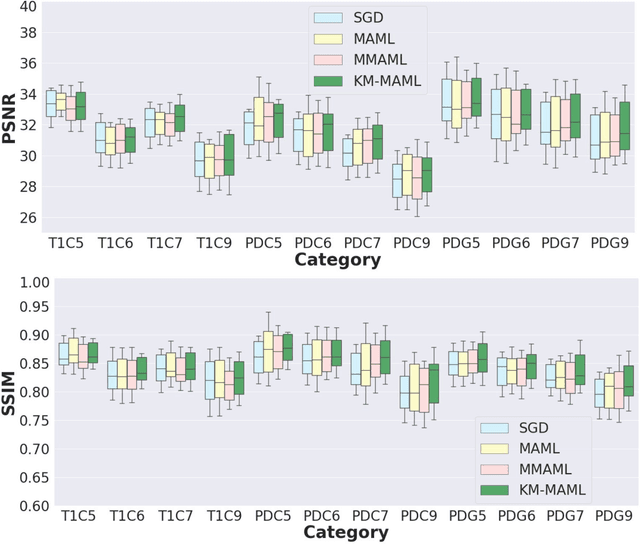
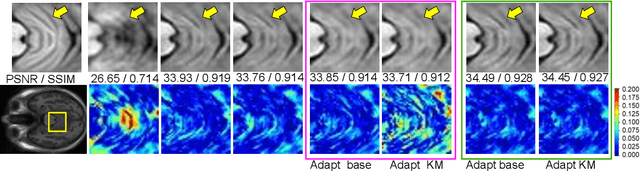
Meta-learning has recently been an emerging data-efficient learning technique for various medical imaging operations and has helped advance contemporary deep learning models. Furthermore, meta-learning enhances the knowledge generalization of the imaging tasks by learning both shared and discriminative weights for various configurations of imaging tasks. However, existing meta-learning models attempt to learn a single set of weight initializations of a neural network that might be restrictive for multimodal data. This work aims to develop a multimodal meta-learning model for image reconstruction, which augments meta-learning with evolutionary capabilities to encompass diverse acquisition settings of multimodal data. Our proposed model called KM-MAML (Kernel Modulation-based Multimodal Meta-Learning), has hypernetworks that evolve to generate mode-specific weights. These weights provide the mode-specific inductive bias for multiple modes by re-calibrating each kernel of the base network for image reconstruction via a low-rank kernel modulation operation. We incorporate gradient-based meta-learning (GBML) in the contextual space to update the weights of the hypernetworks for different modes. The hypernetworks and the reconstruction network in the GBML setting provide discriminative mode-specific features and low-level image features, respectively. Experiments on multi-contrast MRI reconstruction show that our model, (i) exhibits superior reconstruction performance over joint training, other meta-learning methods, and context-specific MRI reconstruction methods, and (ii) better adaptation capabilities with improvement margins of 0.5 dB in PSNR and 0.01 in SSIM. Besides, a representation analysis with U-Net shows that kernel modulation infuses 80% of mode-specific representation changes in the high-resolution layers. Our source code is available at https://github.com/sriprabhar/KM-MAML/.
Generalizable Deep Learning Method for Suppressing Unseen and Multiple MRI Artifacts Using Meta-learning
Apr 13, 2023


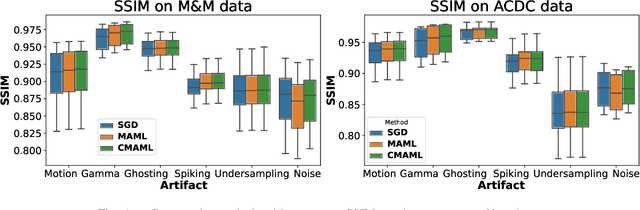
Magnetic Resonance (MR) images suffer from various types of artifacts due to motion, spatial resolution, and under-sampling. Conventional deep learning methods deal with removing a specific type of artifact, leading to separately trained models for each artifact type that lack the shared knowledge generalizable across artifacts. Moreover, training a model for each type and amount of artifact is a tedious process that consumes more training time and storage of models. On the other hand, the shared knowledge learned by jointly training the model on multiple artifacts might be inadequate to generalize under deviations in the types and amounts of artifacts. Model-agnostic meta-learning (MAML), a nested bi-level optimization framework is a promising technique to learn common knowledge across artifacts in the outer level of optimization, and artifact-specific restoration in the inner level. We propose curriculum-MAML (CMAML), a learning process that integrates MAML with curriculum learning to impart the knowledge of variable artifact complexity to adaptively learn restoration of multiple artifacts during training. Comparative studies against Stochastic Gradient Descent and MAML, using two cardiac datasets reveal that CMAML exhibits (i) better generalization with improved PSNR for 83% of unseen types and amounts of artifacts and improved SSIM in all cases, and (ii) better artifact suppression in 4 out of 5 cases of composite artifacts (scans with multiple artifacts).
SFT-KD-Recon: Learning a Student-friendly Teacher for Knowledge Distillation in Magnetic Resonance Image Reconstruction
Apr 11, 2023



Deep cascaded architectures for magnetic resonance imaging (MRI) acceleration have shown remarkable success in providing high-quality reconstruction. However, as the number of cascades increases, the improvements in reconstruction tend to become marginal, indicating possible excess model capacity. Knowledge distillation (KD) is an emerging technique to compress these models, in which a trained deep teacher network is used to distill knowledge to a smaller student network such that the student learns to mimic the behavior of the teacher. Most KD methods focus on effectively training the student with a pre-trained teacher unaware of the student model. We propose SFT-KD-Recon, a student-friendly teacher training approach along with the student as a prior step to KD to make the teacher aware of the structure and capacity of the student and enable aligning the representations of the teacher with the student. In SFT, the teacher is jointly trained with the unfolded branch configurations of the student blocks using three loss terms - teacher-reconstruction loss, student-reconstruction loss, and teacher-student imitation loss, followed by KD of the student. We perform extensive experiments for MRI acceleration in 4x and 5x under-sampling on the brain and cardiac datasets on five KD methods using the proposed approach as a prior step. We consider the DC-CNN architecture and setup teacher as D5C5 (141765 parameters), and student as D3C5 (49285 parameters), denoting a compression of 2.87:1. Results show that (i) our approach consistently improves the KD methods with improved reconstruction performance and image quality, and (ii) the student distilled using our approach is competitive with the teacher, with the performance gap reduced from 0.53 dB to 0.03 dB.
A deep cascade of ensemble of dual domain networks with gradient-based T1 assistance and perceptual refinement for fast MRI reconstruction
Jul 05, 2022
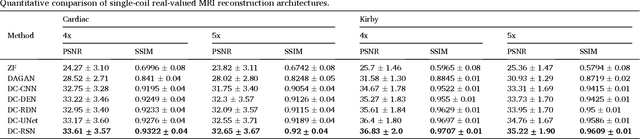
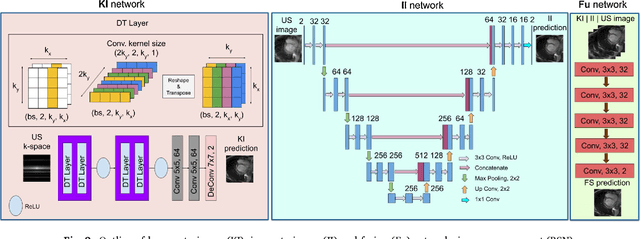
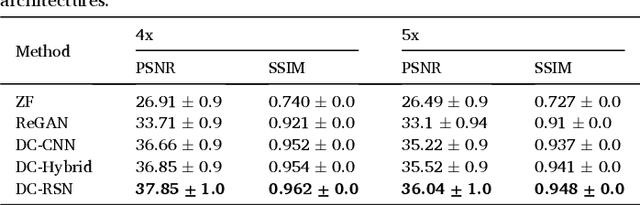
Deep learning networks have shown promising results in fast magnetic resonance imaging (MRI) reconstruction. In our work, we develop deep networks to further improve the quantitative and the perceptual quality of reconstruction. To begin with, we propose reconsynergynet (RSN), a network that combines the complementary benefits of independently operating on both the image and the Fourier domain. For a single-coil acquisition, we introduce deep cascade RSN (DC-RSN), a cascade of RSN blocks interleaved with data fidelity (DF) units. Secondly, we improve the structure recovery of DC-RSN for T2 weighted Imaging (T2WI) through assistance of T1 weighted imaging (T1WI), a sequence with short acquisition time. T1 assistance is provided to DC-RSN through a gradient of log feature (GOLF) fusion. Furthermore, we propose perceptual refinement network (PRN) to refine the reconstructions for better visual information fidelity (VIF), a metric highly correlated to radiologists opinion on the image quality. Lastly, for multi-coil acquisition, we propose variable splitting RSN (VS-RSN), a deep cascade of blocks, each block containing RSN, multi-coil DF unit, and a weighted average module. We extensively validate our models DC-RSN and VS-RSN for single-coil and multi-coil acquisitions and report the state-of-the-art performance. We obtain a SSIM of 0.768, 0.923, 0.878 for knee single-coil-4x, multi-coil-4x, and multi-coil-8x in fastMRI. We also conduct experiments to demonstrate the efficacy of GOLF based T1 assistance and PRN.
MAC-ReconNet: A Multiple Acquisition Context based Convolutional Neural Network for MR Image Reconstruction using Dynamic Weight Prediction
Nov 09, 2021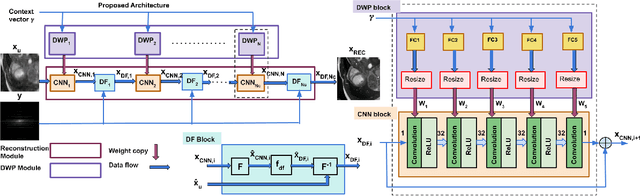

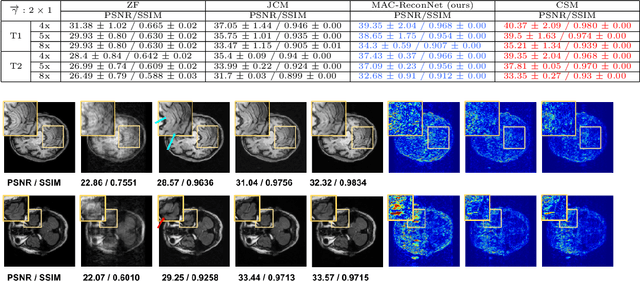
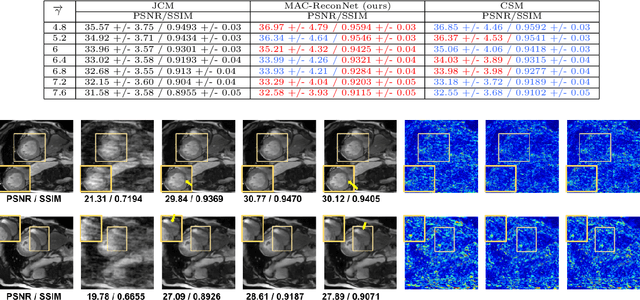
Convolutional Neural network-based MR reconstruction methods have shown to provide fast and high quality reconstructions. A primary drawback with a CNN-based model is that it lacks flexibility and can effectively operate only for a specific acquisition context limiting practical applicability. By acquisition context, we mean a specific combination of three input settings considered namely, the anatomy under study, undersampling mask pattern and acceleration factor for undersampling. The model could be trained jointly on images combining multiple contexts. However the model does not meet the performance of context specific models nor extensible to contexts unseen at train time. This necessitates a modification to the existing architecture in generating context specific weights so as to incorporate flexibility to multiple contexts. We propose a multiple acquisition context based network, called MAC-ReconNet for MRI reconstruction, flexible to multiple acquisition contexts and generalizable to unseen contexts for applicability in real scenarios. The proposed network has an MRI reconstruction module and a dynamic weight prediction (DWP) module. The DWP module takes the corresponding acquisition context information as input and learns the context-specific weights of the reconstruction module which changes dynamically with context at run time. We show that the proposed approach can handle multiple contexts based on cardiac and brain datasets, Gaussian and Cartesian undersampling patterns and five acceleration factors. The proposed network outperforms the naive jointly trained model and gives competitive results with the context-specific models both quantitatively and qualitatively. We also demonstrate the generalizability of our model by testing on contexts unseen at train time.
Reference-based Texture transfer for Single Image Super-resolution of Magnetic Resonance images
Feb 10, 2021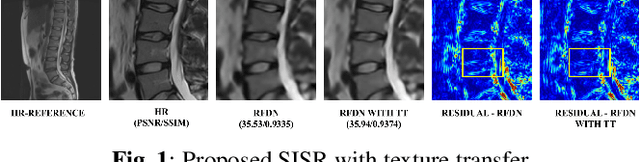
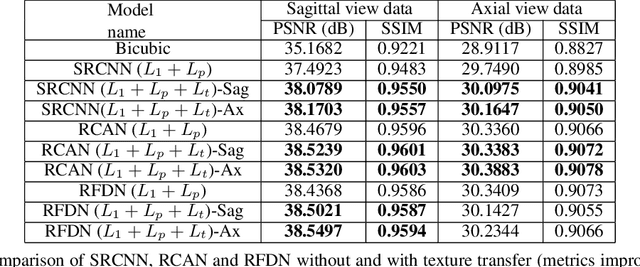
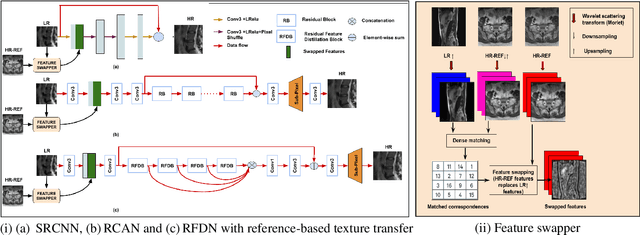
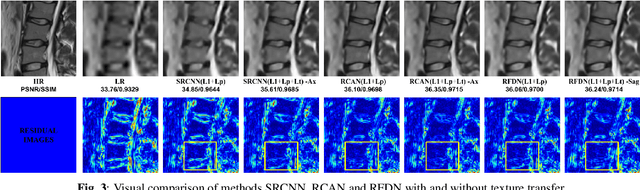
Magnetic Resonance Imaging (MRI) is a valuable clinical diagnostic modality for spine pathologies with excellent characterization for infection, tumor, degenerations, fractures and herniations. However in surgery, image-guided spinal procedures continue to rely on CT and fluoroscopy, as MRI slice resolutions are typically insufficient. Building upon state-of-the-art single image super-resolution, we propose a reference-based, unpaired multi-contrast texture-transfer strategy for deep learning based in-plane and across-plane MRI super-resolution. We use the scattering transform to relate the texture features of image patches to unpaired reference image patches, and additionally a loss term for multi-contrast texture. We apply our scheme in different super-resolution architectures, observing improvement in PSNR and SSIM for 4x super-resolution in most of the cases.
DC-WCNN: A deep cascade of wavelet based convolutional neural networks for MR Image Reconstruction
Jan 08, 2020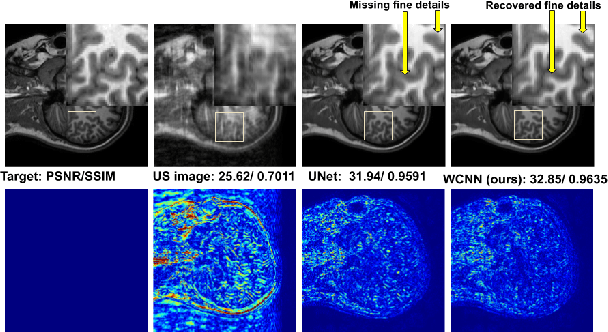
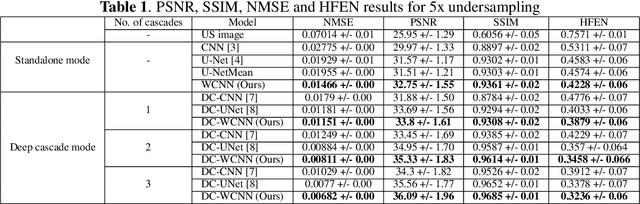
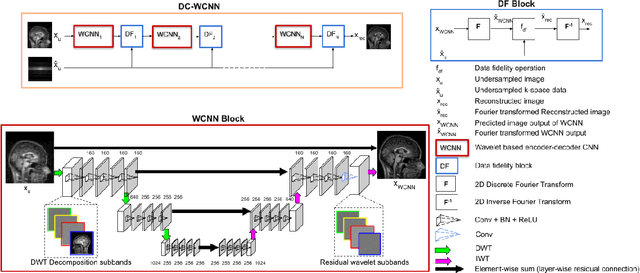

Several variants of Convolutional Neural Networks (CNN) have been developed for Magnetic Resonance (MR) image reconstruction. Among them, U-Net has shown to be the baseline architecture for MR image reconstruction. However, sub-sampling is performed by its pooling layers, causing information loss which in turn leads to blur and missing fine details in the reconstructed image. We propose a modification to the U-Net architecture to recover fine structures. The proposed network is a wavelet packet transform based encoder-decoder CNN with residual learning called CNN. The proposed WCNN has discrete wavelet transform instead of pooling and inverse wavelet transform instead of unpooling layers and residual connections. We also propose a deep cascaded framework (DC-WCNN) which consists of cascades of WCNN and k-space data fidelity units to achieve high quality MR reconstruction. Experimental results show that WCNN and DC-WCNN give promising results in terms of evaluation metrics and better recovery of fine details as compared to other methods.