 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastFlow: Accelerating The Generative Flow Matching Models with Bandit Inference
Feb 11, 2026Flow-matching models deliver state-of-the-art fidelity in image and video generation, but the inherent sequential denoising process renders them slower. Existing acceleration methods like distillation, trajectory truncation, and consistency approaches are static, require retraining, and often fail to generalize across tasks. We propose FastFlow, a plug-and-play adaptive inference framework that accelerates generation in flow matching models. FastFlow identifies denoising steps that produce only minor adjustments to the denoising path and approximates them without using the full neural network models used for velocity predictions. The approximation utilizes finite-difference velocity estimates from prior predictions to efficiently extrapolate future states, enabling faster advancements along the denoising path at zero compute cost. This enables skipping computation at intermediary steps. We model the decision of how many steps to safely skip before requiring a full model computation as a multi-armed bandit problem. The bandit learns the optimal skips to balance speed with performance. FastFlow integrates seamlessly with existing pipelines and generalizes across image generation, video generation, and editing tasks. Experiments demonstrate a speedup of over 2.6x while maintaining high-quality outputs. The source code for this work can be found at https://github.com/Div290/FastFlow.
AAD-DCE: An Aggregated Multimodal Attention Mechanism for Early and Late Dynamic Contrast Enhanced Prostate MRI Synthesis
Feb 04, 2025Dynamic Contrast-Enhanced Magnetic Resonance Imaging (DCE-MRI) is a medical imaging technique that plays a crucial role in the detailed visualization and identification of tissue perfusion in abnormal lesions and radiological suggestions for biopsy. However, DCE-MRI involves the administration of a Gadolinium based (Gad) contrast agent, which is associated with a risk of toxicity in the body. Previous deep learning approaches that synthesize DCE-MR images employ unimodal non-contrast or low-dose contrast MRI images lacking focus on the local perfusion information within the anatomy of interest. We propose AAD-DCE, a generative adversarial network (GAN) with an aggregated attention discriminator module consisting of global and local discriminators. The discriminators provide a spatial embedded attention map to drive the generator to synthesize early and late response DCE-MRI images. Our method employs multimodal inputs - T2 weighted (T2W), Apparent Diffusion Coefficient (ADC), and T1 pre-contrast for image synthesis. Extensive comparative and ablation studies on the ProstateX dataset show that our model (i) is agnostic to various generator benchmarks and (ii) outperforms other DCE-MRI synthesis approaches with improvement margins of +0.64 dB PSNR, +0.0518 SSIM, -0.015 MAE for early response and +0.1 dB PSNR, +0.0424 SSIM, -0.021 MAE for late response, and (ii) emphasize the importance of attention ensembling. Our code is available at https://github.com/bhartidivya/AAD-DCE.
Novel Reinforcement Learning Algorithm for Suppressing Synchronization in Closed Loop Deep Brain Stimulators
Dec 30, 2022



Parkinson's disease is marked by altered and increased firing characteristics of pathological oscillations in the brain. In other words, it causes abnormal synchronous oscillations and suppression during neurological processing. In order to examine and regulate the synchronization and pathological oscillations in motor circuits, deep brain stimulators (DBS) are used. Although machine learning methods have been applied for the investigation of suppression, these models require large amounts of training data and computational power, both of which pose challenges to resource-constrained DBS. This research proposes a novel reinforcement learning (RL) framework for suppressing the synchronization in neuronal activity during episodes of neurological disorders with less power consumption. The proposed RL algorithm comprises an ensemble of a temporal representation of stimuli and a twin-delayed deep deterministic (TD3) policy gradient algorithm. We quantify the stability of the proposed framework to noise and reduced synchrony using RL for three pathological signaling regimes: regular, chaotic, and bursting, and further eliminate the undesirable oscillations. Furthermore, metrics such as evaluation rewards, energy supplied to the ensemble, and the mean point of convergence were used and compared to other RL algorithms, specifically the Advantage actor critic (A2C), the Actor critic with Kronecker-featured trust region (ACKTR), and the Proximal policy optimization (PPO).
A Seven-Layer Model for Standardising AI Fairness Assessment
Dec 21, 2022Problem statement: Standardisation of AI fairness rules and benchmarks is challenging because AI fairness and other ethical requirements depend on multiple factors such as context, use case, type of the AI system, and so on. In this paper, we elaborate that the AI system is prone to biases at every stage of its lifecycle, from inception to its usage, and that all stages require due attention for mitigating AI bias. We need a standardised approach to handle AI fairness at every stage. Gap analysis: While AI fairness is a hot research topic, a holistic strategy for AI fairness is generally missing. Most researchers focus only on a few facets of AI model-building. Peer review shows excessive focus on biases in the datasets, fairness metrics, and algorithmic bias. In the process, other aspects affecting AI fairness get ignored. The solution proposed: We propose a comprehensive approach in the form of a novel seven-layer model, inspired by the Open System Interconnection (OSI) model, to standardise AI fairness handling. Despite the differences in the various aspects, most AI systems have similar model-building stages. The proposed model splits the AI system lifecycle into seven abstraction layers, each corresponding to a well-defined AI model-building or usage stage. We also provide checklists for each layer and deliberate on potential sources of bias in each layer and their mitigation methodologies. This work will facilitate layer-wise standardisation of AI fairness rules and benchmarking parameters.
DeePhy: On Deepfake Phylogeny
Sep 19, 2022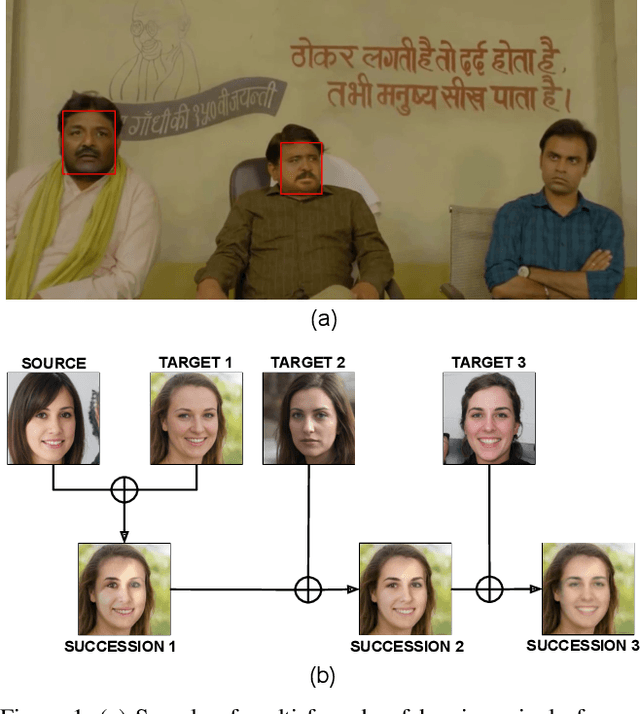
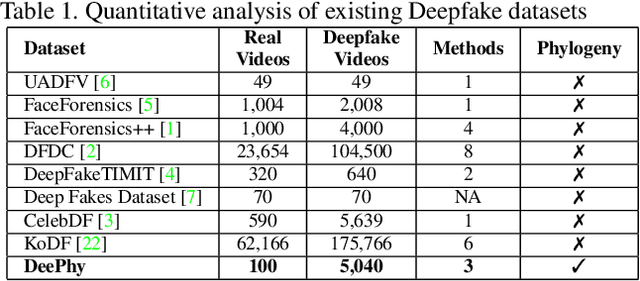

Deepfake refers to tailored and synthetically generated videos which are now prevalent and spreading on a large scale, threatening the trustworthiness of the information available online. While existing datasets contain different kinds of deepfakes which vary in their generation technique, they do not consider progression of deepfakes in a "phylogenetic" manner. It is possible that an existing deepfake face is swapped with another face. This process of face swapping can be performed multiple times and the resultant deepfake can be evolved to confuse the deepfake detection algorithms. Further, many databases do not provide the employed generative model as target labels. Model attribution helps in enhancing the explainability of the detection results by providing information on the generative model employed. In order to enable the research community to address these questions, this paper proposes DeePhy, a novel Deepfake Phylogeny dataset which consists of 5040 deepfake videos generated using three different generation techniques. There are 840 videos of one-time swapped deepfakes, 2520 videos of two-times swapped deepfakes and 1680 videos of three-times swapped deepfakes. With over 30 GBs in size, the database is prepared in over 1100 hours using 18 GPUs of 1,352 GB cumulative memory. We also present the benchmark on DeePhy dataset using six deepfake detection algorithms. The results highlight the need to evolve the research of model attribution of deepfakes and generalize the process over a variety of deepfake generation techniques. The database is available at: http://iab-rubric.org/deephy-database
Fairness Score and Process Standardization: Framework for Fairness Certification in Artificial Intelligence Systems
Jan 10, 2022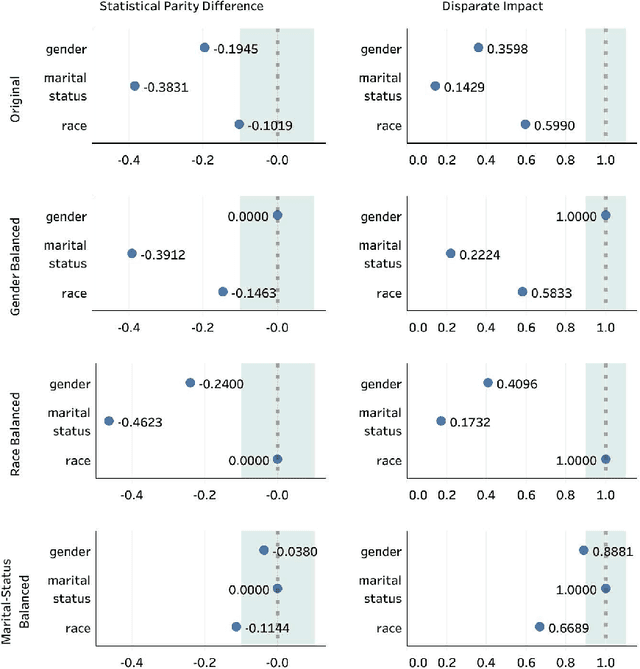
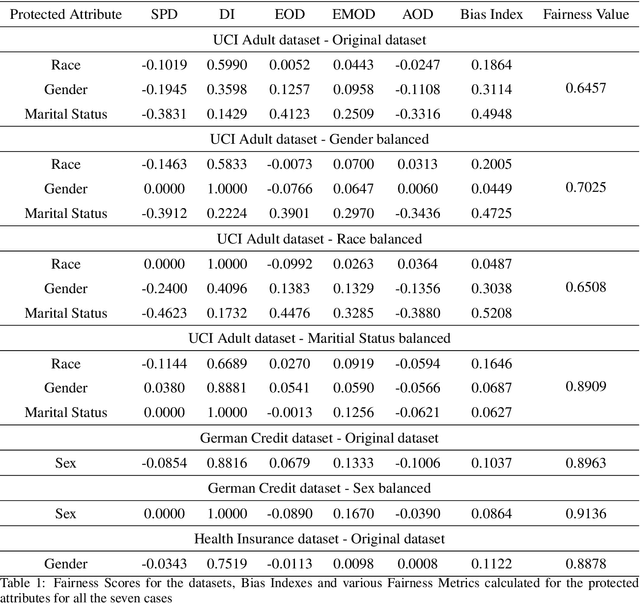
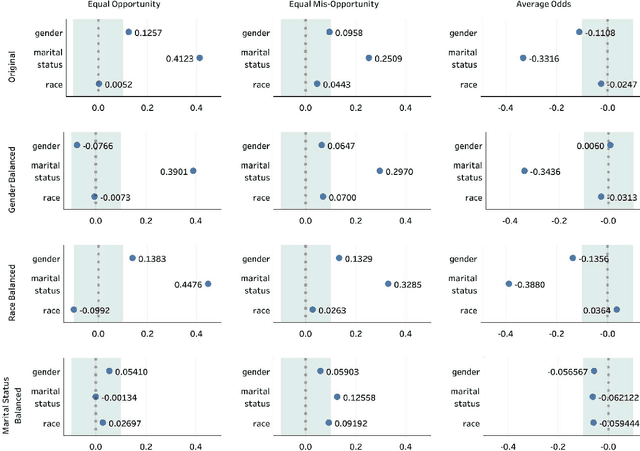
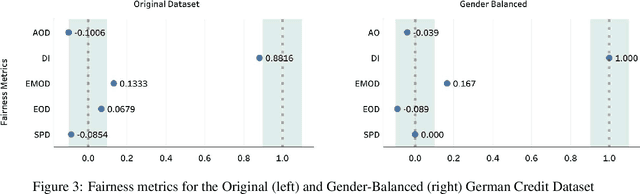
Decisions made by various Artificial Intelligence (AI) systems greatly influence our day-to-day lives. With the increasing use of AI systems, it becomes crucial to know that they are fair, identify the underlying biases in their decision-making, and create a standardized framework to ascertain their fairness. In this paper, we propose a novel Fairness Score to measure the fairness of a data-driven AI system and a Standard Operating Procedure (SOP) for issuing Fairness Certification for such systems. Fairness Score and audit process standardization will ensure quality, reduce ambiguity, enable comparison and improve the trustworthiness of the AI systems. It will also provide a framework to operationalise the concept of fairness and facilitate the commercial deployment of such systems. Furthermore, a Fairness Certificate issued by a designated third-party auditing agency following the standardized process would boost the conviction of the organizations in the AI systems that they intend to deploy. The Bias Index proposed in this paper also reveals comparative bias amongst the various protected attributes within the dataset. To substantiate the proposed framework, we iteratively train a model on biased and unbiased data using multiple datasets and check that the Fairness Score and the proposed process correctly identify the biases and judge the fairness.
Shapes of Emotions: Multimodal Emotion Recognition in Conversations via Emotion Shifts
Dec 03, 2021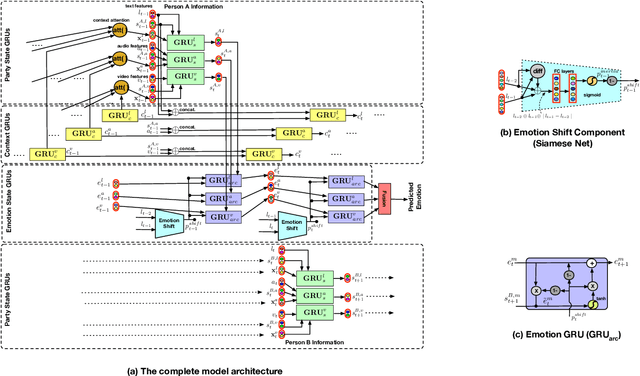
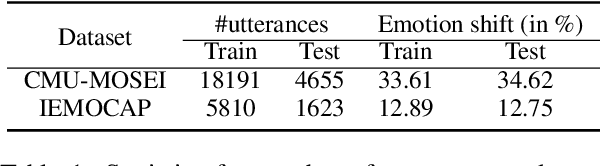
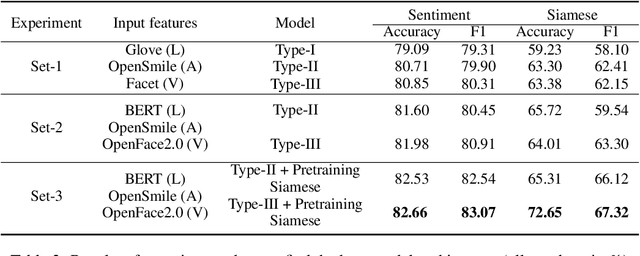
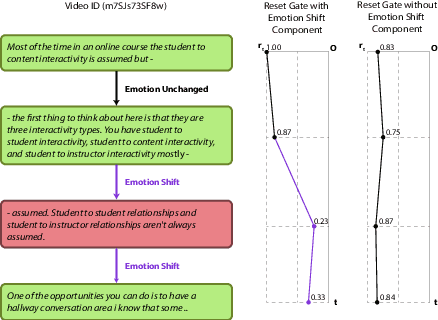
Emotion Recognition in Conversations (ERC) is an important and active research problem. Recent work has shown the benefits of using multiple modalities (e.g., text, audio, and video) for the ERC task. In a conversation, participants tend to maintain a particular emotional state unless some external stimuli evokes a change. There is a continuous ebb and flow of emotions in a conversation. Inspired by this observation, we propose a multimodal ERC model and augment it with an emotion-shift component. The proposed emotion-shift component is modular and can be added to any existing multimodal ERC model (with a few modifications), to improve emotion recognition. We experiment with different variants of the model, and results show that the inclusion of emotion shift signal helps the model to outperform existing multimodal models for ERC and hence showing the state-of-the-art performance on MOSEI and IEMOCAP datasets.
DeepBLE: Generalizing RSSI-based Localization Across Different Devices
Feb 27, 2021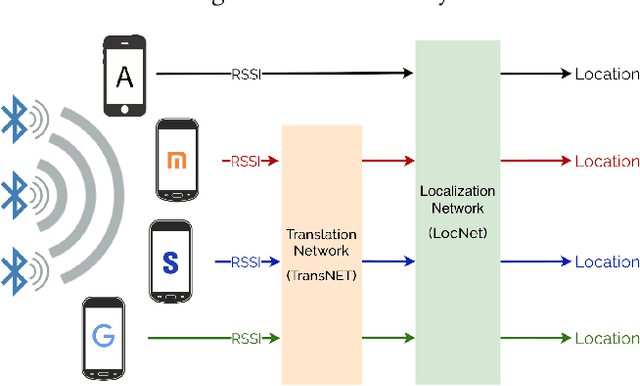
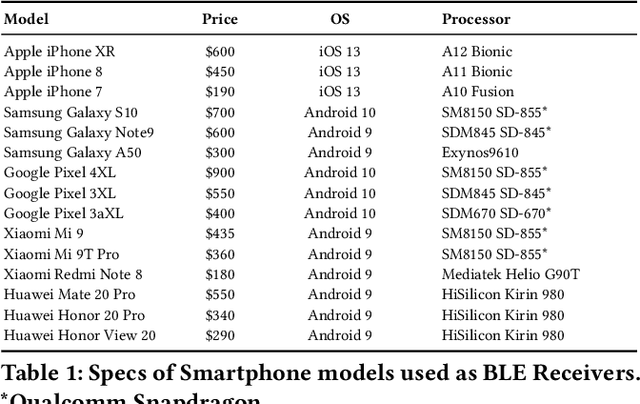
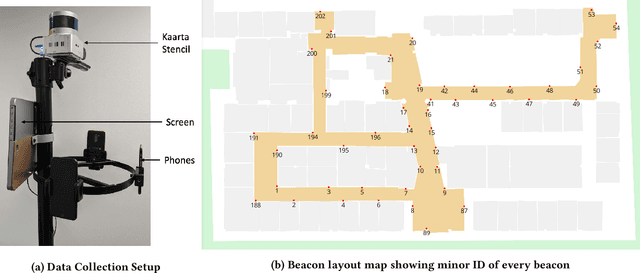
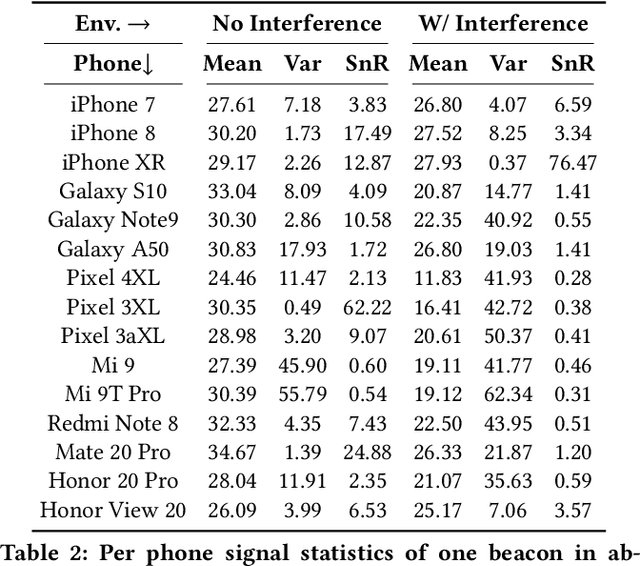
Accurate smartphone localization (< 1-meter error) for indoor navigation using only RSSI received from a set of BLE beacons remains a challenging problem, due to the inherent noise of RSSI measurements. To overcome the large variance in RSSI measurements, we propose a data-driven approach that uses a deep recurrent network, DeepBLE, to localize the smartphone using RSSI measured from multiple beacons in an environment. In particular, we focus on the ability of our approach to generalize across many smartphone brands (e.g., Apple, Samsung) and models (e.g., iPhone 8, S10). Towards this end, we collect a large-scale dataset of 15 hours of smartphone data, which consists of over 50,000 BLE beacon RSSI measurements collected from 47 beacons in a single building using 15 different popular smartphone models, along with precise 2D location annotations. Our experiments show that there is a very high variability of RSSI measurements across smartphone models (especially across brand), making it very difficult to apply supervised learning using only a subset of smartphone models. To address this challenge, we propose a novel statistic similarity loss (SSL) which enables our model to generalize to unseen phones using a semi-supervised learning approach. For known phones, the iPhone XR achieves the best mean distance error of 0.84 meters. For unknown phones, the Huawei Mate20 Pro shows the greatest improvement, cutting error by over 38\% from 2.62 meters to 1.63 meters error using our semi-supervised adaptation method.
BAKSA at SemEval-2020 Task 9: Bolstering CNN with Self-Attention for Sentiment Analysis of Code Mixed Text
Jul 21, 2020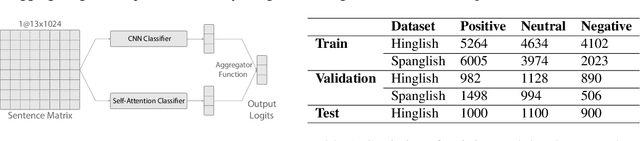
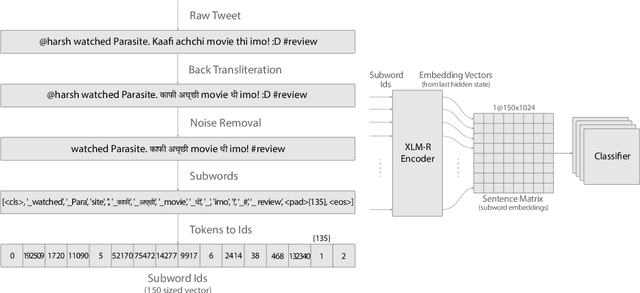
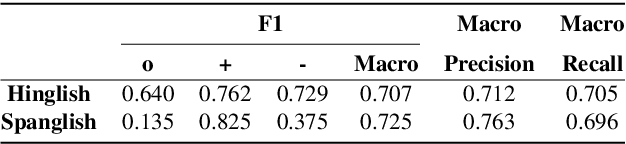
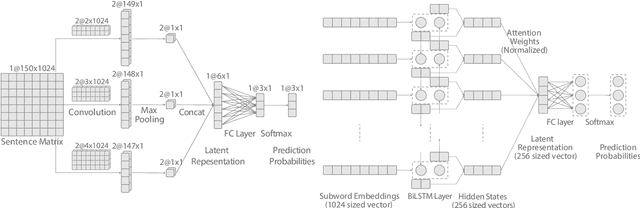
Sentiment Analysis of code-mixed text has diversified applications in opinion mining ranging from tagging user reviews to identifying social or political sentiments of a sub-population. In this paper, we present an ensemble architecture of convolutional neural net (CNN) and self-attention based LSTM for sentiment analysis of code-mixed tweets. While the CNN component helps in the classification of positive and negative tweets, the self-attention based LSTM, helps in the classification of neutral tweets, because of its ability to identify correct sentiment among multiple sentiment bearing units. We achieved F1 scores of 0.707 (ranked 5th) and 0.725 (ranked 13th) on Hindi-English (Hinglish) and Spanish-English (Spanglish) datasets, respectively. The submissions for Hinglish and Spanglish tasks were made under the usernames ayushk and harsh_6 respectively.
Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction
Apr 05, 2018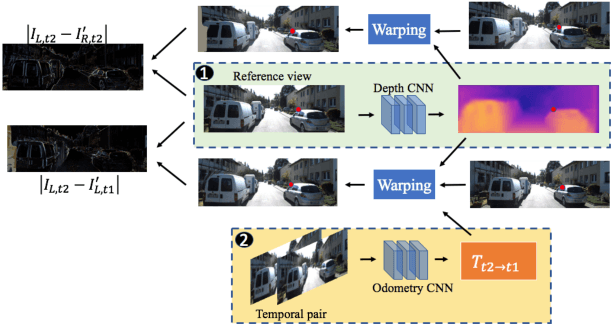
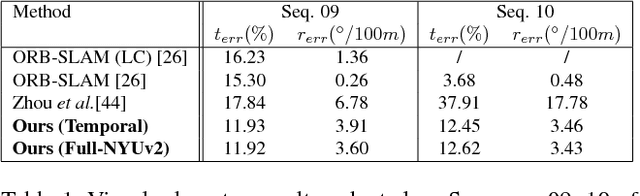
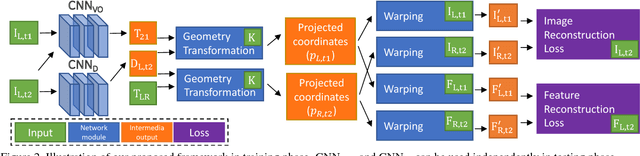
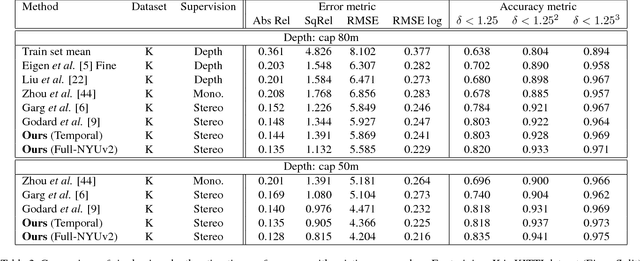
Despite learning based methods showing promising results in single view depth estimation and visual odometry, most existing approaches treat the tasks in a supervised manner. Recent approaches to single view depth estimation explore the possibility of learning without full supervision via minimizing photometric error. In this paper, we explore the use of stereo sequences for learning depth and visual odometry. The use of stereo sequences enables the use of both spatial (between left-right pairs) and temporal (forward backward) photometric warp error, and constrains the scene depth and camera motion to be in a common, real-world scale. At test time our framework is able to estimate single view depth and two-view odometry from a monocular sequence. We also show how we can improve on a standard photometric warp loss by considering a warp of deep features. We show through extensive experiments that: (i) jointly training for single view depth and visual odometry improves depth prediction because of the additional constraint imposed on depths and achieves competitive results for visual odometry; (ii) deep feature-based warping loss improves upon simple photometric warp loss for both single view depth estimation and visual odometry. Our method outperforms existing learning based methods on the KITTI driving dataset in both tasks. The source code is available at https://github.com/Huangying-Zhan/Depth-VO-Feat