 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-VO: What Should Be Learnt for Visual Odometry?
Mar 01, 2021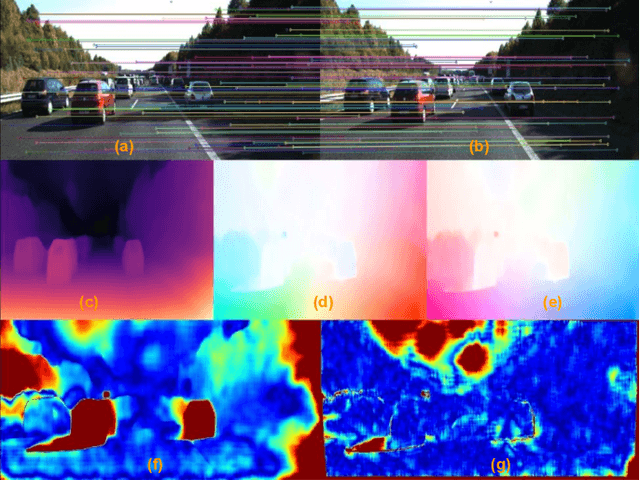
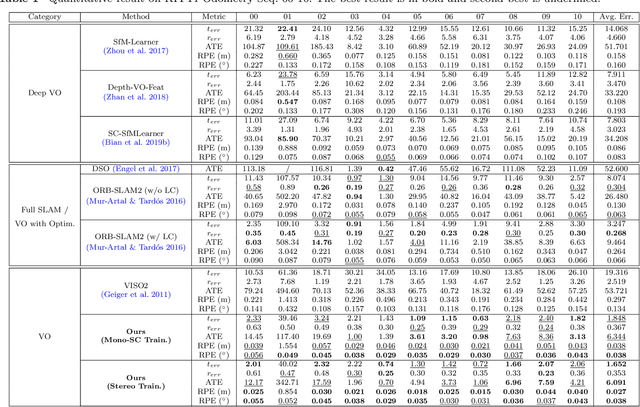
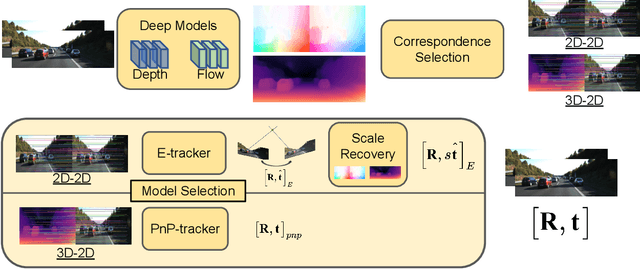

Multi-view geometry-based methods dominate the last few decades in monocular Visual Odometry for their superior performance, while they have been vulnerable to dynamic and low-texture scenes. More importantly, monocular methods suffer from scale-drift issue, i.e., errors accumulate over time. Recent studies show that deep neural networks can learn scene depths and relative camera in a self-supervised manner without acquiring ground truth labels. More surprisingly, they show that the well-trained networks enable scale-consistent predictions over long videos, while the accuracy is still inferior to traditional methods because of ignoring geometric information. Building on top of recent progress in computer vision, we design a simple yet robust VO system by integrating multi-view geometry and deep learning on Depth and optical Flow, namely DF-VO. In this work, a) we propose a method to carefully sample high-quality correspondences from deep flows and recover accurate camera poses with a geometric module; b) we address the scale-drift issue by aligning geometrically triangulated depths to the scale-consistent deep depths, where the dynamic scenes are taken into account. Comprehensive ablation studies show the effectiveness of the proposed method, and extensive evaluation results show the state-of-the-art performance of our system, e.g., Ours (1.652%) v.s. ORB-SLAM (3.247%}) in terms of translation error in KITTI Odometry benchmark. Source code is publicly available at: \href{https://github.com/Huangying-Zhan/DF-VO}{DF-VO}.
Visual Odometry Revisited: What Should Be Learnt?
Oct 03, 2019

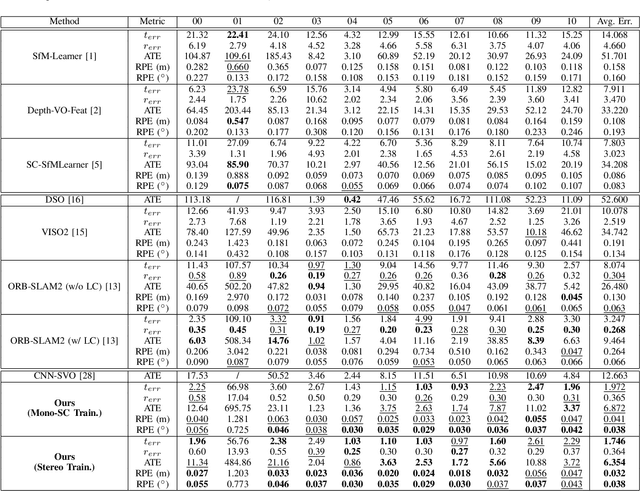
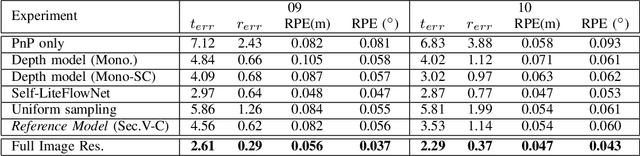
In this work we present a monocular visual odometry (VO) algorithm which leverages geometry-based methods and deep learning. Most existing VO/SLAM systems with superior performance are based on geometry and have to be carefully designed for different application scenarios. Moreover, most monocular systems suffer from scale-drift issue. Some recent deep learning works learn VO in an end-to-end manner but the performance of these deep systems is still not comparable to geometry-based methods. In this work, we revisit the basics of VO and explore the right way for integrating deep learning with epipolar geometry and Perspective-n-Point (PnP) method. Specifically, we train two convolutional neural networks (CNNs) for estimating single-view depths and two-view optical flows as intermediate outputs. With the deep predictions, we design a simple but robust frame-to-frame VO algorithm (DF-VO) which outperforms pure deep learning-based and geometry-based methods. More importantly, our system does not suffer from the scale-drift issue being aided by a scale consistent single-view depth CNN. Extensive experiments on KITTI dataset shows the robustness of our system and a detailed ablation study shows the effect of different factors in our system.
Self-supervised Learning for Single View Depth and Surface Normal Estimation
Mar 01, 2019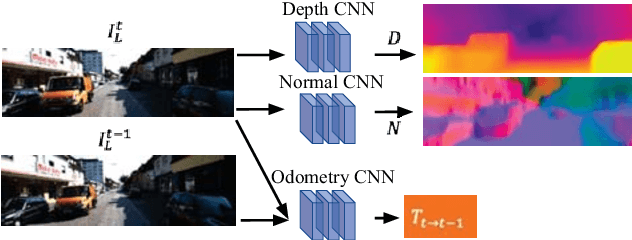
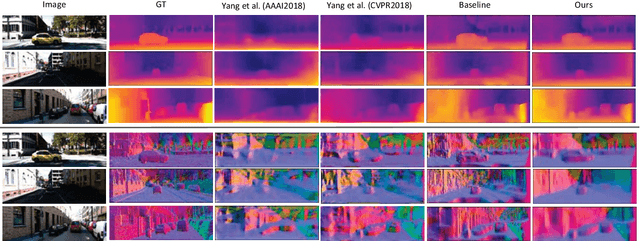
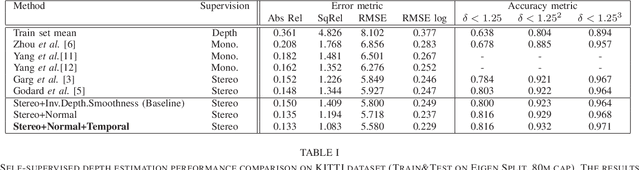
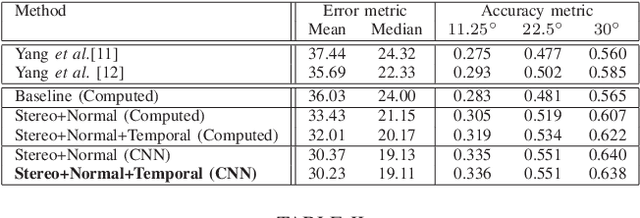
In this work we present a self-supervised learning framework to simultaneously train two Convolutional Neural Networks (CNNs) to predict depth and surface normals from a single image. In contrast to most existing frameworks which represent outdoor scenes as fronto-parallel planes at piece-wise smooth depth, we propose to predict depth with surface orientation while assuming that natural scenes have piece-wise smooth normals. We show that a simple depth-normal consistency as a soft-constraint on the predictions is sufficient and effective for training both these networks simultaneously. The trained normal network provides state-of-the-art predictions while the depth network, relying on much realistic smooth normal assumption, outperforms the traditional self-supervised depth prediction network by a large margin on the KITTI benchmark. Demo video: https://youtu.be/ZD-ZRsw7hdM
Just-in-Time Reconstruction: Inpainting Sparse Maps using Single View Depth Predictors as Priors
May 11, 2018

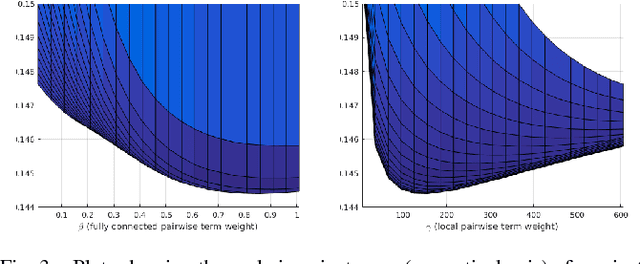
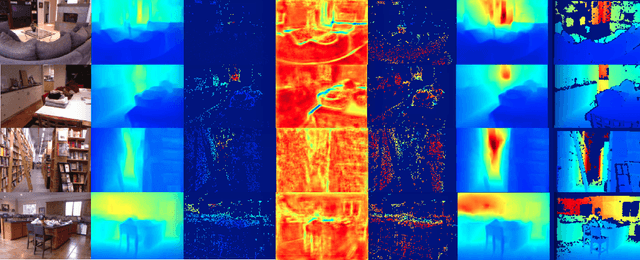
We present ``just-in-time reconstruction" as real-time image-guided inpainting of a map with arbitrary scale and sparsity to generate a fully dense depth map for the image. In particular, our goal is to inpaint a sparse map --- obtained from either a monocular visual SLAM system or a sparse sensor --- using a single-view depth prediction network as a virtual depth sensor. We adopt a fairly standard approach to data fusion, to produce a fused depth map by performing inference over a novel fully-connected Conditional Random Field (CRF) which is parameterized by the input depth maps and their pixel-wise confidence weights. Crucially, we obtain the confidence weights that parameterize the CRF model in a data-dependent manner via Convolutional Neural Networks (CNNs) which are trained to model the conditional depth error distributions given each source of input depth map and the associated RGB image. Our CRF model penalises absolute depth error in its nodes and pairwise scale-invariant depth error in its edges, and the confidence-based fusion minimizes the impact of outlier input depth values on the fused result. We demonstrate the flexibility of our method by real-time inpainting of ORB-SLAM, Kinect, and LIDAR depth maps acquired both indoors and outdoors at arbitrary scale and varied amount of irregular sparsity.
Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction
Apr 05, 2018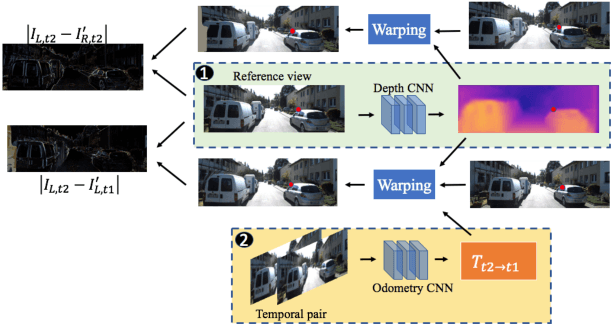
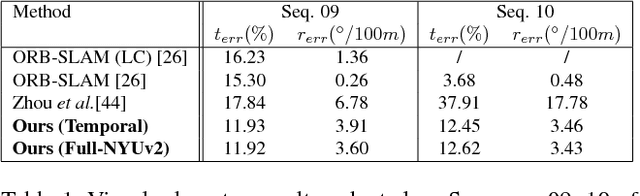
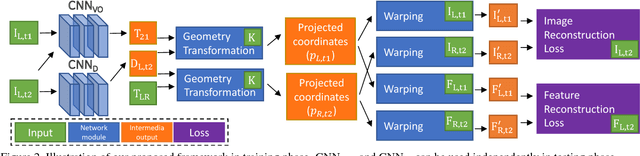
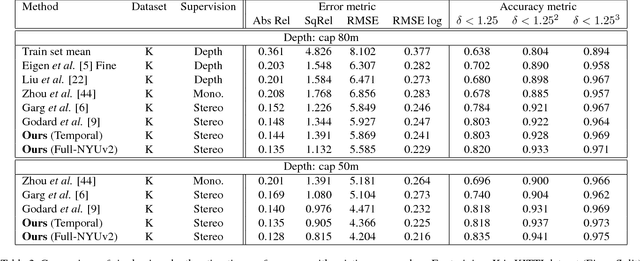
Despite learning based methods showing promising results in single view depth estimation and visual odometry, most existing approaches treat the tasks in a supervised manner. Recent approaches to single view depth estimation explore the possibility of learning without full supervision via minimizing photometric error. In this paper, we explore the use of stereo sequences for learning depth and visual odometry. The use of stereo sequences enables the use of both spatial (between left-right pairs) and temporal (forward backward) photometric warp error, and constrains the scene depth and camera motion to be in a common, real-world scale. At test time our framework is able to estimate single view depth and two-view odometry from a monocular sequence. We also show how we can improve on a standard photometric warp loss by considering a warp of deep features. We show through extensive experiments that: (i) jointly training for single view depth and visual odometry improves depth prediction because of the additional constraint imposed on depths and achieves competitive results for visual odometry; (ii) deep feature-based warping loss improves upon simple photometric warp loss for both single view depth estimation and visual odometry. Our method outperforms existing learning based methods on the KITTI driving dataset in both tasks. The source code is available at https://github.com/Huangying-Zhan/Depth-VO-Feat
Learning Deeply Supervised Visual Descriptors for Dense Monocular Reconstruction
Nov 16, 2017
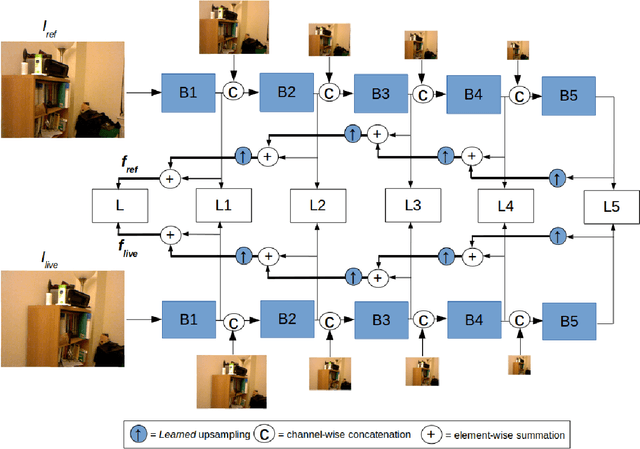


Visual SLAM (Simultaneous Localization and Mapping) methods typically rely on handcrafted visual features or raw RGB values for establishing correspondences between images. These features, while suitable for sparse mapping, often lead to ambiguous matches at texture-less regions when performing dense reconstruction due to the aperture problem. In this work, we explore the use of learned features for the matching task in dense monocular reconstruction. We propose a novel convolutional neural network (CNN) architecture along with a deeply supervised feature learning scheme for pixel-wise regression of visual descriptors from an image which are best suited for dense monocular SLAM. In particular, our learning scheme minimizes a multi-view matching cost-volume loss with respect to the regressed features at multiple stages within the network, for explicitly learning contextual features that are suitable for dense matching between images captured by a moving monocular camera along the epipolar line. We utilize the learned features from our model for depth estimation inside a real-time dense monocular SLAM framework, where photometric error is replaced by our learned descriptor error. Our evaluation on several challenging indoor scenes demonstrate greatly improved accuracy in dense reconstructions of the well celebrated dense SLAM systems like DTAM, without compromising their real-time performance.