 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-VO: What Should Be Learnt for Visual Odometry?
Paper and Code
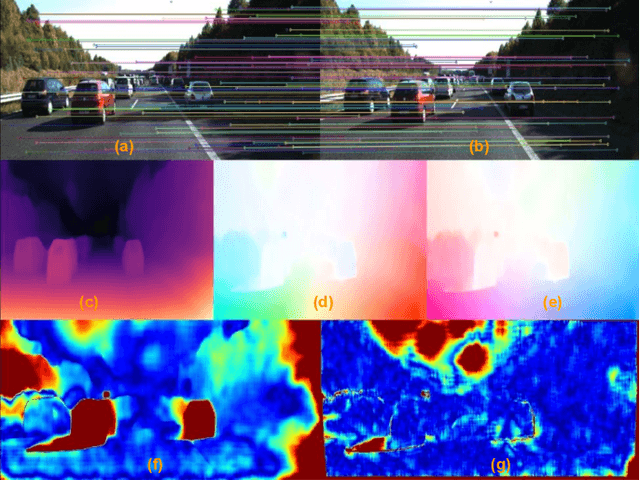
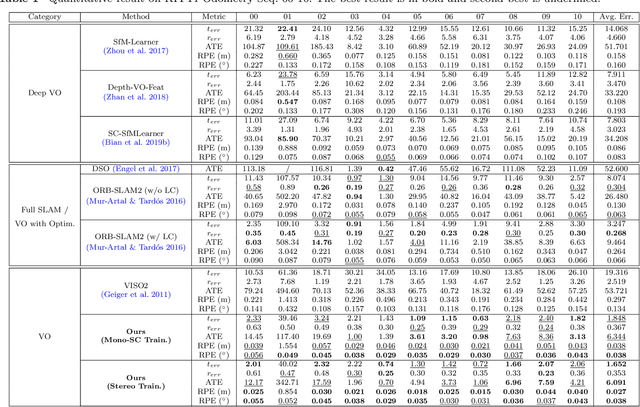
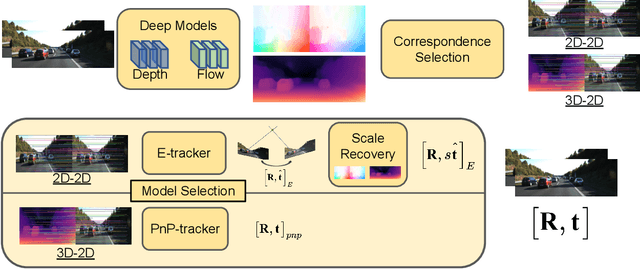

Multi-view geometry-based methods dominate the last few decades in monocular Visual Odometry for their superior performance, while they have been vulnerable to dynamic and low-texture scenes. More importantly, monocular methods suffer from scale-drift issue, i.e., errors accumulate over time. Recent studies show that deep neural networks can learn scene depths and relative camera in a self-supervised manner without acquiring ground truth labels. More surprisingly, they show that the well-trained networks enable scale-consistent predictions over long videos, while the accuracy is still inferior to traditional methods because of ignoring geometric information. Building on top of recent progress in computer vision, we design a simple yet robust VO system by integrating multi-view geometry and deep learning on Depth and optical Flow, namely DF-VO. In this work, a) we propose a method to carefully sample high-quality correspondences from deep flows and recover accurate camera poses with a geometric module; b) we address the scale-drift issue by aligning geometrically triangulated depths to the scale-consistent deep depths, where the dynamic scenes are taken into account. Comprehensive ablation studies show the effectiveness of the proposed method, and extensive evaluation results show the state-of-the-art performance of our system, e.g., Ours (1.652%) v.s. ORB-SLAM (3.247%}) in terms of translation error in KITTI Odometry benchmark. Source code is publicly available at: \href{https://github.com/Huangying-Zhan/DF-VO}{DF-VO}.