 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
Revisiting Depth Representations for Feed-Forward 3D Gaussian Splatting
Jun 05, 2025Depth maps are widely used in feed-forward 3D Gaussian Splatting (3DGS) pipelines by unprojecting them into 3D point clouds for novel view synthesis. This approach offers advantages such as efficient training, the use of known camera poses, and accurate geometry estimation. However, depth discontinuities at object boundaries often lead to fragmented or sparse point clouds, degrading rendering quality -- a well-known limitation of depth-based representations. To tackle this issue, we introduce PM-Loss, a novel regularization loss based on a pointmap predicted by a pre-trained transformer. Although the pointmap itself may be less accurate than the depth map, it effectively enforces geometric smoothness, especially around object boundaries. With the improved depth map, our method significantly improves the feed-forward 3DGS across various architectures and scenes, delivering consistently better rendering results. Our project page: https://aim-uofa.github.io/PMLoss
Hyper3D: Efficient 3D Representation via Hybrid Triplane and Octree Feature for Enhanced 3D Shape Variational Auto-Encoders
Mar 13, 2025Recent 3D content generation pipelines often leverage Variational Autoencoders (VAEs) to encode shapes into compact latent representations, facilitating diffusion-based generation. Efficiently compressing 3D shapes while preserving intricate geometric details remains a key challenge. Existing 3D shape VAEs often employ uniform point sampling and 1D/2D latent representations, such as vector sets or triplanes, leading to significant geometric detail loss due to inadequate surface coverage and the absence of explicit 3D representations in the latent space. Although recent work explores 3D latent representations, their large scale hinders high-resolution encoding and efficient training. Given these challenges, we introduce Hyper3D, which enhances VAE reconstruction through efficient 3D representation that integrates hybrid triplane and octree features. First, we adopt an octree-based feature representation to embed mesh information into the network, mitigating the limitations of uniform point sampling in capturing geometric distributions along the mesh surface. Furthermore, we propose a hybrid latent space representation that integrates a high-resolution triplane with a low-resolution 3D grid. This design not only compensates for the lack of explicit 3D representations but also leverages a triplane to preserve high-resolution details. Experimental results demonstrate that Hyper3D outperforms traditional representations by reconstructing 3D shapes with higher fidelity and finer details, making it well-suited for 3D generation pipelines.
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
May 16, 2024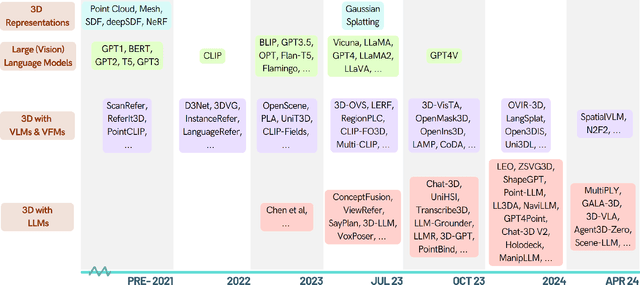
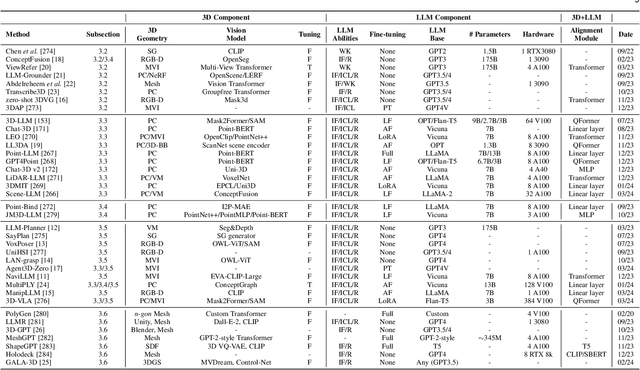
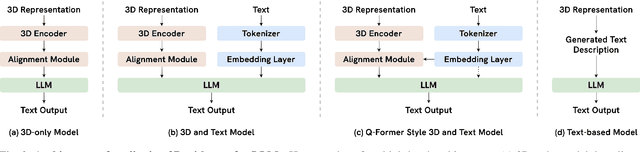
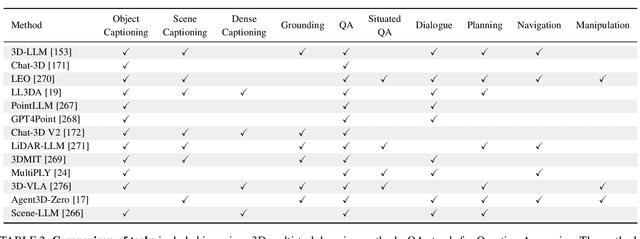
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
GaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
Mar 14, 2024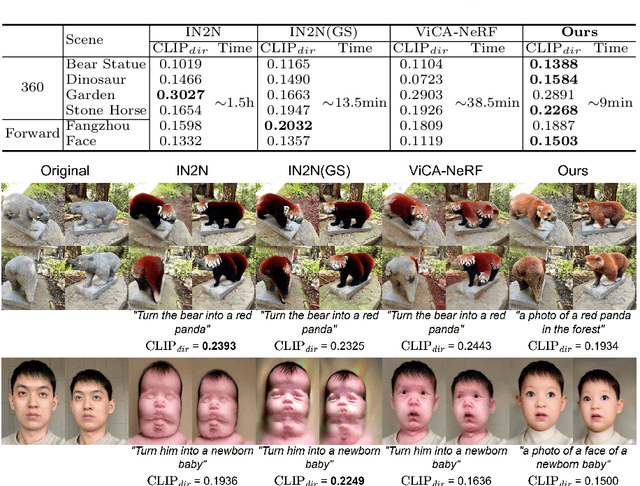



We propose GaussCtrl, a text-driven method to edit a 3D scene reconstructed by the 3D Gaussian Splatting (3DGS). Our method first renders a collection of images by using the 3DGS and edits them by using a pre-trained 2D diffusion model (ControlNet) based on the input prompt, which is then used to optimise the 3D model. Our key contribution is multi-view consistent editing, which enables editing all images together instead of iteratively editing one image while updating the 3D model as in previous works. It leads to faster editing as well as higher visual quality. This is achieved by the two terms: (a) depth-conditioned editing that enforces geometric consistency across multi-view images by leveraging naturally consistent depth maps. (b) attention-based latent code alignment that unifies the appearance of edited images by conditioning their editing to several reference views through self and cross-view attention between images' latent representations. Experiments demonstrate that our method achieves faster editing and better visual results than previous state-of-the-art methods.
MGDepth: Motion-Guided Cost Volume For Self-Supervised Monocular Depth In Dynamic Scenarios
Dec 23, 2023



Despite advancements in self-supervised monocular depth estimation, challenges persist in dynamic scenarios due to the dependence on assumptions about a static world. In this paper, we present MGDepth, a Motion-Guided Cost Volume Depth Net, to achieve precise depth estimation for both dynamic objects and static backgrounds, all while maintaining computational efficiency. To tackle the challenges posed by dynamic content, we incorporate optical flow and coarse monocular depth to create a novel static reference frame. This frame is then utilized to build a motion-guided cost volume in collaboration with the target frame. Additionally, to enhance the accuracy and resilience of the network structure, we introduce an attention-based depth net architecture to effectively integrate information from feature maps with varying resolutions. Compared to methods with similar computational costs, MGDepth achieves a significant reduction of approximately seven percent in root-mean-square error for self-supervised monocular depth estimation on the KITTI-2015 dataset.
PoRF: Pose Residual Field for Accurate Neural Surface Reconstruction
Oct 12, 2023Neural surface reconstruction is sensitive to the camera pose noise, even if state-of-the-art pose estimators like COLMAP or ARKit are used. More importantly, existing Pose-NeRF joint optimisation methods have struggled to improve pose accuracy in challenging real-world scenarios. To overcome the challenges, we introduce the pose residual field (\textbf{PoRF}), a novel implicit representation that uses an MLP for regressing pose updates. This is more robust than the conventional pose parameter optimisation due to parameter sharing that leverages global information over the entire sequence. Furthermore, we propose an epipolar geometry loss to enhance the supervision that leverages the correspondences exported from COLMAP results without the extra computational overhead. Our method yields promising results. On the DTU dataset, we reduce the rotation error by 78\% for COLMAP poses, leading to the decreased reconstruction Chamfer distance from 3.48mm to 0.85mm. On the MobileBrick dataset that contains casually captured unbounded 360-degree videos, our method refines ARKit poses and improves the reconstruction F1 score from 69.18 to 75.67, outperforming that with the dataset provided ground-truth pose (75.14). These achievements demonstrate the efficacy of our approach in refining camera poses and improving the accuracy of neural surface reconstruction in real-world scenarios.
MobileBrick: Building LEGO for 3D Reconstruction on Mobile Devices
Mar 09, 2023High-quality 3D ground-truth shapes are critical for 3D object reconstruction evaluation. However, it is difficult to create a replica of an object in reality, and even 3D reconstructions generated by 3D scanners have artefacts that cause biases in evaluation. To address this issue, we introduce a novel multi-view RGBD dataset captured using a mobile device, which includes highly precise 3D ground-truth annotations for 153 object models featuring a diverse set of 3D structures. We obtain precise 3D ground-truth shape without relying on high-end 3D scanners by utilising LEGO models with known geometry as the 3D structures for image capture. The distinct data modality offered by high-resolution RGB images and low-resolution depth maps captured on a mobile device, when combined with precise 3D geometry annotations, presents a unique opportunity for future research on high-fidelity 3D reconstruction. Furthermore, we evaluate a range of 3D reconstruction algorithms on the proposed dataset. Project page: http://code.active.vision/MobileBrick/
NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
Dec 14, 2022



Training a Neural Radiance Field (NeRF) without pre-computed camera poses is challenging. Recent advances in this direction demonstrate the possibility of jointly optimising a NeRF and camera poses in forward-facing scenes. However, these methods still face difficulties during dramatic camera movement. We tackle this challenging problem by incorporating undistorted monocular depth priors. These priors are generated by correcting scale and shift parameters during training, with which we are then able to constrain the relative poses between consecutive frames. This constraint is achieved using our proposed novel loss functions. Experiments on real-world indoor and outdoor scenes show that our method can handle challenging camera trajectories and outperforms existing methods in terms of novel view rendering quality and pose estimation accuracy.
Deep Negative Correlation Classification
Dec 14, 2022Ensemble learning serves as a straightforward way to improve the performance of almost any machine learning algorithm. Existing deep ensemble methods usually naively train many different models and then aggregate their predictions. This is not optimal in our view from two aspects: i) Naively training multiple models adds much more computational burden, especially in the deep learning era; ii) Purely optimizing each base model without considering their interactions limits the diversity of ensemble and performance gains. We tackle these issues by proposing deep negative correlation classification (DNCC), in which the accuracy and diversity trade-off is systematically controlled by decomposing the loss function seamlessly into individual accuracy and the correlation between individual models and the ensemble. DNCC yields a deep classification ensemble where the individual estimator is both accurate and negatively correlated. Thanks to the optimized diversities, DNCC works well even when utilizing a shared network backbone, which significantly improves its efficiency when compared with most existing ensemble systems. Extensive experiments on multiple benchmark datasets and network structures demonstrate the superiority of the proposed method.