 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Coordinate Reconstruction Priors
Oct 14, 2025Scene coordinate regression (SCR) models have proven to be powerful implicit scene representations for 3D vision, enabling visual relocalization and structure-from-motion. SCR models are trained specifically for one scene. If training images imply insufficient multi-view constraints SCR models degenerate. We present a probabilistic reinterpretation of training SCR models, which allows us to infuse high-level reconstruction priors. We investigate multiple such priors, ranging from simple priors over the distribution of reconstructed depth values to learned priors over plausible scene coordinate configurations. For the latter, we train a 3D point cloud diffusion model on a large corpus of indoor scans. Our priors push predicted 3D scene points towards plausible geometry at each training step to increase their likelihood. On three indoor datasets our priors help learning better scene representations, resulting in more coherent scene point clouds, higher registration rates and better camera poses, with a positive effect on down-stream tasks such as novel view synthesis and camera relocalization.
Active View Selector: Fast and Accurate Active View Selection with Cross Reference Image Quality Assessment
Jun 24, 2025We tackle active view selection in novel view synthesis and 3D reconstruction. Existing methods like FisheRF and ActiveNeRF select the next best view by minimizing uncertainty or maximizing information gain in 3D, but they require specialized designs for different 3D representations and involve complex modelling in 3D space. Instead, we reframe this as a 2D image quality assessment (IQA) task, selecting views where current renderings have the lowest quality. Since ground-truth images for candidate views are unavailable, full-reference metrics like PSNR and SSIM are inapplicable, while no-reference metrics, such as MUSIQ and MANIQA, lack the essential multi-view context. Inspired by a recent cross-referencing quality framework CrossScore, we train a model to predict SSIM within a multi-view setup and use it to guide view selection. Our cross-reference IQA framework achieves substantial quantitative and qualitative improvements across standard benchmarks, while being agnostic to 3D representations, and runs 14-33 times faster than previous methods.
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
Jun 04, 2025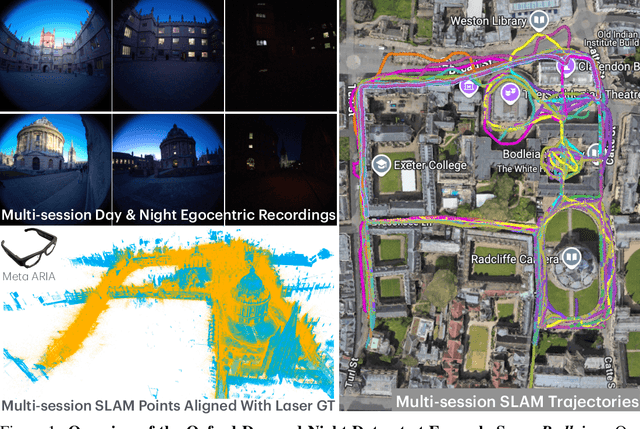


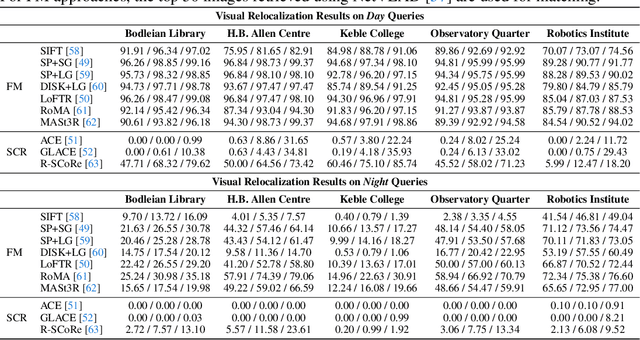
We introduce Oxford Day-and-Night, a large-scale, egocentric dataset for novel view synthesis (NVS) and visual relocalisation under challenging lighting conditions. Existing datasets often lack crucial combinations of features such as ground-truth 3D geometry, wide-ranging lighting variation, and full 6DoF motion. Oxford Day-and-Night addresses these gaps by leveraging Meta ARIA glasses to capture egocentric video and applying multi-session SLAM to estimate camera poses, reconstruct 3D point clouds, and align sequences captured under varying lighting conditions, including both day and night. The dataset spans over 30 $\mathrm{km}$ of recorded trajectories and covers an area of 40,000 $\mathrm{m}^2$, offering a rich foundation for egocentric 3D vision research. It supports two core benchmarks, NVS and relocalisation, providing a unique platform for evaluating models in realistic and diverse environments.
Splatt3R: Zero-shot Gaussian Splatting from Uncalibarated Image Pairs
Aug 25, 2024In this paper, we introduce Splatt3R, a pose-free, feed-forward method for in-the-wild 3D reconstruction and novel view synthesis from stereo pairs. Given uncalibrated natural images, Splatt3R can predict 3D Gaussian Splats without requiring any camera parameters or depth information. For generalizability, we start from a 'foundation' 3D geometry reconstruction method, MASt3R, and extend it to be a full 3D structure and appearance reconstructor. Specifically, unlike the original MASt3R which reconstructs only 3D point clouds, we predict the additional Gaussian attributes required to construct a Gaussian primitive for each point. Hence, unlike other novel view synthesis methods, Splatt3R is first trained by optimizing the 3D point cloud's geometry loss, and then a novel view synthesis objective. By doing this, we avoid the local minima present in training 3D Gaussian Splats from stereo views. We also propose a novel loss masking strategy that we empirically find is critical for strong performance on extrapolated viewpoints. We train Splatt3R on the ScanNet++ dataset and demonstrate excellent generalisation to uncalibrated, in-the-wild images. Splatt3R can reconstruct scenes at 4FPS at 512 x 512 resolution, and the resultant splats can be rendered in real-time.
GSLoc: Efficient Camera Pose Refinement via 3D Gaussian Splatting
Aug 20, 2024



We leverage 3D Gaussian Splatting (3DGS) as a scene representation and propose a novel test-time camera pose refinement framework, GSLoc. This framework enhances the localization accuracy of state-of-the-art absolute pose regression and scene coordinate regression methods. The 3DGS model renders high-quality synthetic images and depth maps to facilitate the establishment of 2D-3D correspondences. GSLoc obviates the need for training feature extractors or descriptors by operating directly on RGB images, utilizing the 3D vision foundation model, MASt3R, for precise 2D matching. To improve the robustness of our model in challenging outdoor environments, we incorporate an exposure-adaptive module within the 3DGS framework. Consequently, GSLoc enables efficient pose refinement given a single RGB query and a coarse initial pose estimation. Our proposed approach surpasses leading NeRF-based optimization methods in both accuracy and runtime across indoor and outdoor visual localization benchmarks, achieving state-of-the-art accuracy on two indoor datasets.
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
May 16, 2024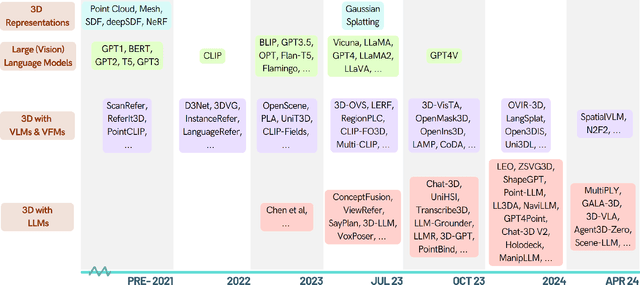
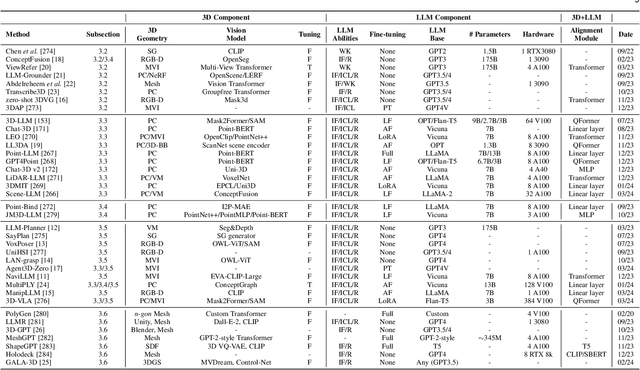
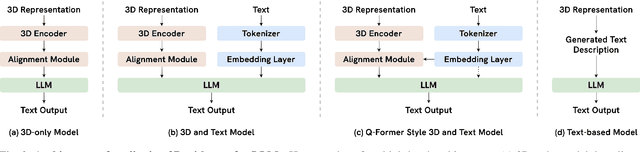
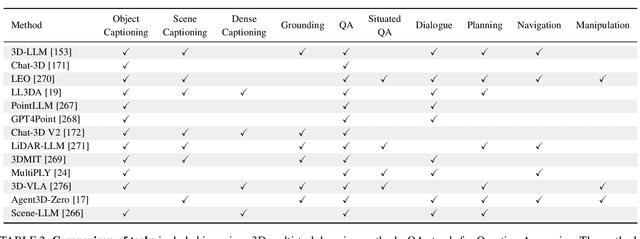
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
CrossScore: Towards Multi-View Image Evaluation and Scoring
Apr 22, 2024We introduce a novel cross-reference image quality assessment method that effectively fills the gap in the image assessment landscape, complementing the array of established evaluation schemes -- ranging from full-reference metrics like SSIM, no-reference metrics such as NIQE, to general-reference metrics including FID, and Multi-modal-reference metrics, e.g., CLIPScore. Utilising a neural network with the cross-attention mechanism and a unique data collection pipeline from NVS optimisation, our method enables accurate image quality assessment without requiring ground truth references. By comparing a query image against multiple views of the same scene, our method addresses the limitations of existing metrics in novel view synthesis (NVS) and similar tasks where direct reference images are unavailable. Experimental results show that our method is closely correlated to the full-reference metric SSIM, while not requiring ground truth references.
Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
Apr 22, 2024We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
Map-Relative Pose Regression for Visual Re-Localization
Apr 15, 2024Pose regression networks predict the camera pose of a query image relative to a known environment. Within this family of methods, absolute pose regression (APR) has recently shown promising accuracy in the range of a few centimeters in position error. APR networks encode the scene geometry implicitly in their weights. To achieve high accuracy, they require vast amounts of training data that, realistically, can only be created using novel view synthesis in a days-long process. This process has to be repeated for each new scene again and again. We present a new approach to pose regression, map-relative pose regression (marepo), that satisfies the data hunger of the pose regression network in a scene-agnostic fashion. We condition the pose regressor on a scene-specific map representation such that its pose predictions are relative to the scene map. This allows us to train the pose regressor across hundreds of scenes to learn the generic relation between a scene-specific map representation and the camera pose. Our map-relative pose regressor can be applied to new map representations immediately or after mere minutes of fine-tuning for the highest accuracy. Our approach outperforms previous pose regression methods by far on two public datasets, indoor and outdoor. Code is available: https://nianticlabs.github.io/marepo
Matching 2D Images in 3D: Metric Relative Pose from Metric Correspondences
Apr 09, 2024



Given two images, we can estimate the relative camera pose between them by establishing image-to-image correspondences. Usually, correspondences are 2D-to-2D and the pose we estimate is defined only up to scale. Some applications, aiming at instant augmented reality anywhere, require scale-metric pose estimates, and hence, they rely on external depth estimators to recover the scale. We present MicKey, a keypoint matching pipeline that is able to predict metric correspondences in 3D camera space. By learning to match 3D coordinates across images, we are able to infer the metric relative pose without depth measurements. Depth measurements are also not required for training, nor are scene reconstructions or image overlap information. MicKey is supervised only by pairs of images and their relative poses. MicKey achieves state-of-the-art performance on the Map-Free Relocalisation benchmark while requiring less supervision than competing approaches.