 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching 2D Images in 3D: Metric Relative Pose from Metric Correspondences
Apr 09, 2024



Given two images, we can estimate the relative camera pose between them by establishing image-to-image correspondences. Usually, correspondences are 2D-to-2D and the pose we estimate is defined only up to scale. Some applications, aiming at instant augmented reality anywhere, require scale-metric pose estimates, and hence, they rely on external depth estimators to recover the scale. We present MicKey, a keypoint matching pipeline that is able to predict metric correspondences in 3D camera space. By learning to match 3D coordinates across images, we are able to infer the metric relative pose without depth measurements. Depth measurements are also not required for training, nor are scene reconstructions or image overlap information. MicKey is supervised only by pairs of images and their relative poses. MicKey achieves state-of-the-art performance on the Map-Free Relocalisation benchmark while requiring less supervision than competing approaches.
Few-Shot Point Cloud Region Annotation with Human in the Loop
Jun 11, 2019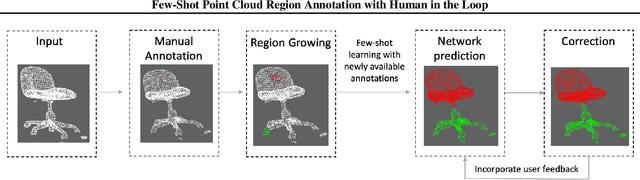
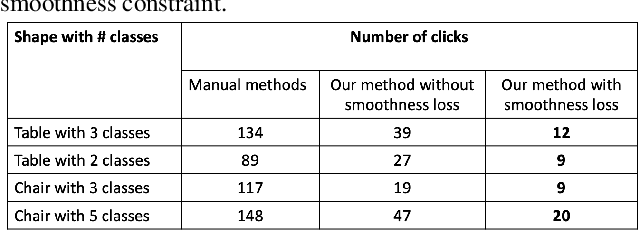

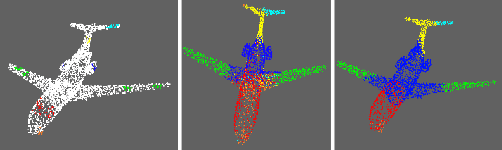
We propose a point cloud annotation framework that employs human-in-loop learning to enable the creation of large point cloud datasets with per-point annotations. Sparse labels from a human annotator are iteratively propagated to generate a full segmentation of the network by fine-tuning a pre-trained model of an allied task via a few-shot learning paradigm. We show that the proposed framework significantly reduces the amount of human interaction needed in annotating point clouds, without sacrificing on the quality of the annotations. Our experiments also suggest the suitability of the framework in annotating large datasets by noting a reduction in human interaction as the number of full annotations completed by the system increases. Finally, we demonstrate the flexibility of the framework to support multiple different annotations of the same point cloud enabling the creation of datasets with different granularities of annotation.
Visual Transfer between Atari Games using Competitive Reinforcement Learning
Sep 02, 2018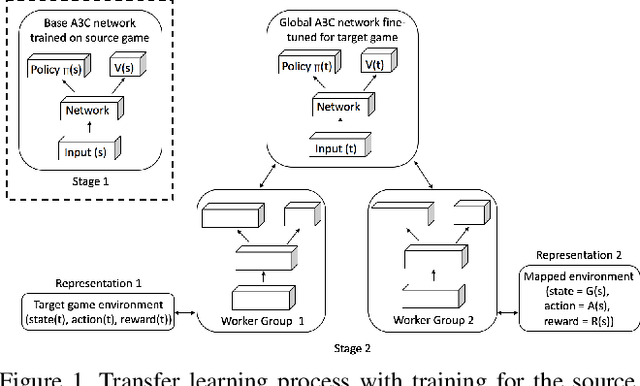
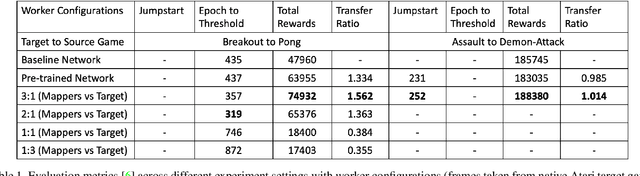
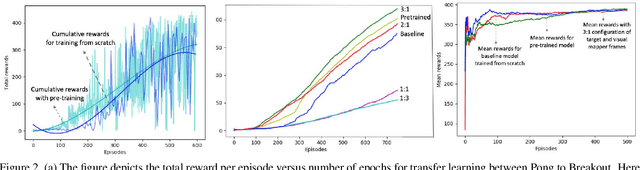
This paper explores the use of deep reinforcement learning agents to transfer knowledge from one environment to another. More specifically, the method takes advantage of asynchronous advantage actor critic (A3C) architecture to generalize a target game using an agent trained on a source game in Atari. Instead of fine-tuning a pre-trained model for the target game, we propose a learning approach to update the model using multiple agents trained in parallel with different representations of the target game. Visual mapping between video sequences of transfer pairs is used to derive new representations of the target game; training on these visual representations of the target game improves model updates in terms of performance, data efficiency and stability. In order to demonstrate the functionality of the architecture, Atari games Pong-v0 and Breakout-v0 are being used from the OpenAI gym environment; as the source and target environment.