 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Transfer between Atari Games using Competitive Reinforcement Learning
Paper and Code
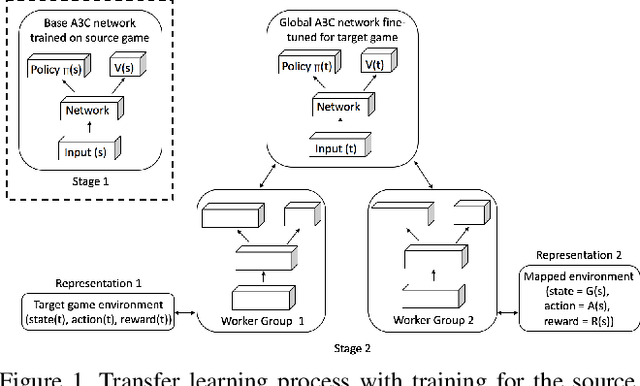
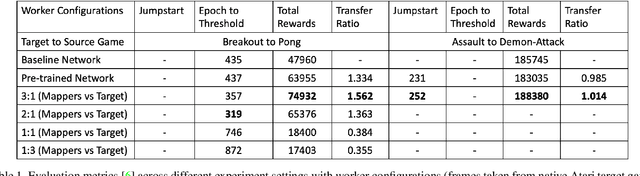
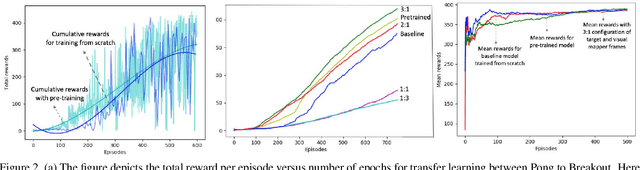
This paper explores the use of deep reinforcement learning agents to transfer knowledge from one environment to another. More specifically, the method takes advantage of asynchronous advantage actor critic (A3C) architecture to generalize a target game using an agent trained on a source game in Atari. Instead of fine-tuning a pre-trained model for the target game, we propose a learning approach to update the model using multiple agents trained in parallel with different representations of the target game. Visual mapping between video sequences of transfer pairs is used to derive new representations of the target game; training on these visual representations of the target game improves model updates in terms of performance, data efficiency and stability. In order to demonstrate the functionality of the architecture, Atari games Pong-v0 and Breakout-v0 are being used from the OpenAI gym environment; as the source and target environment.