 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERI: Part Aware Emotion Recognition In The Wild
Oct 18, 2022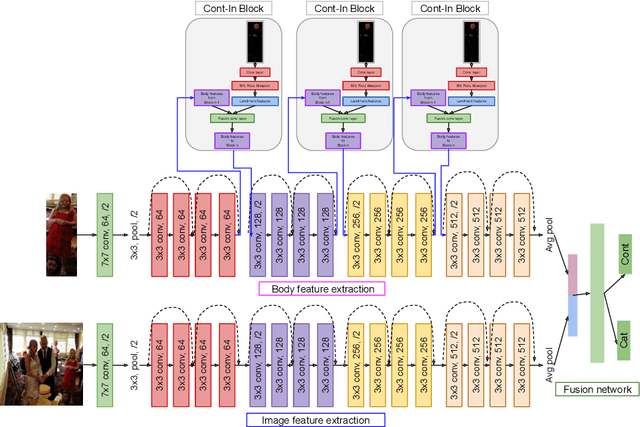
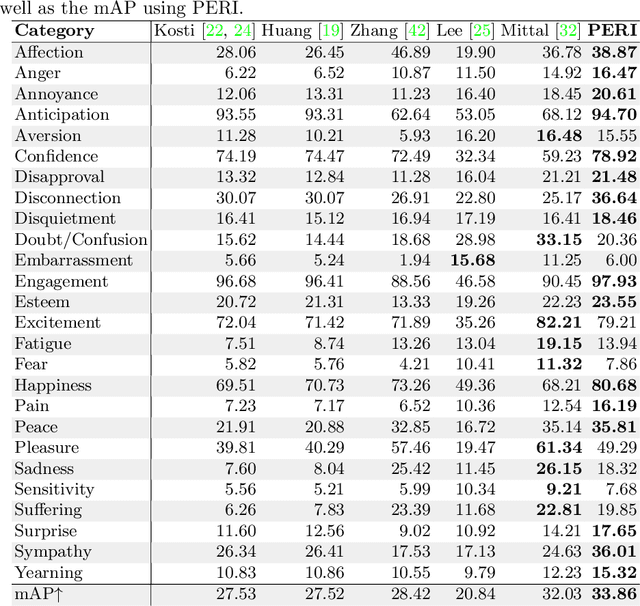
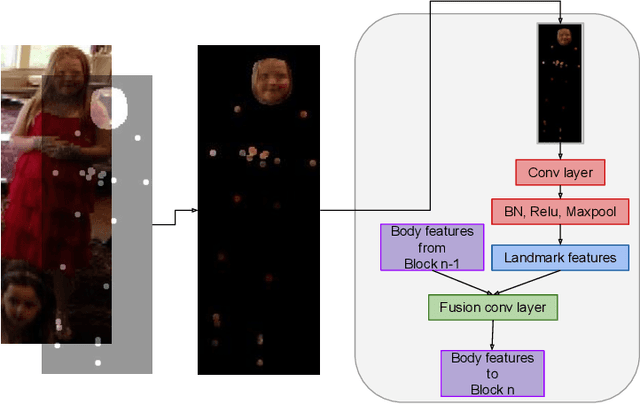
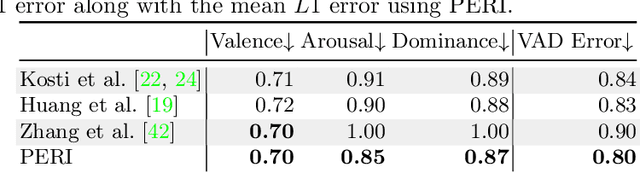
Emotion recognition aims to interpret the emotional states of a person based on various inputs including audio, visual, and textual cues. This paper focuses on emotion recognition using visual features. To leverage the correlation between facial expression and the emotional state of a person, pioneering methods rely primarily on facial features. However, facial features are often unreliable in natural unconstrained scenarios, such as in crowded scenes, as the face lacks pixel resolution and contains artifacts due to occlusion and blur. To address this, in the wild emotion recognition exploits full-body person crops as well as the surrounding scene context. In a bid to use body pose for emotion recognition, such methods fail to realize the potential that facial expressions, when available, offer. Thus, the aim of this paper is two-fold. First, we demonstrate our method, PERI, to leverage both body pose and facial landmarks. We create part aware spatial (PAS) images by extracting key regions from the input image using a mask generated from both body pose and facial landmarks. This allows us to exploit body pose in addition to facial context whenever available. Second, to reason from the PAS images, we introduce context infusion (Cont-In) blocks. These blocks attend to part-specific information, and pass them onto the intermediate features of an emotion recognition network. Our approach is conceptually simple and can be applied to any existing emotion recognition method. We provide our results on the publicly available in the wild EMOTIC dataset. Compared to existing methods, PERI achieves superior performance and leads to significant improvements in the mAP of emotion categories, while decreasing Valence, Arousal and Dominance errors. Importantly, we observe that our method improves performance in both images with fully visible faces as well as in images with occluded or blurred faces.
Scalable Active Learning for Object Detection
Apr 09, 2020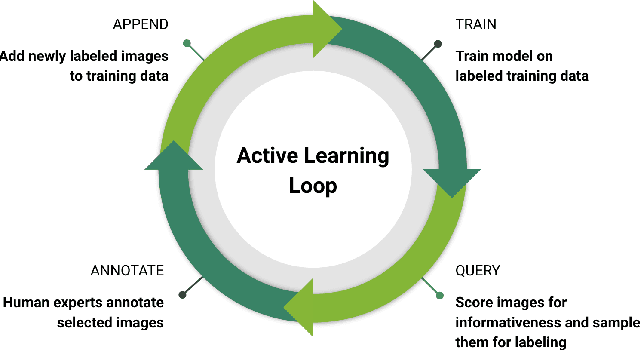
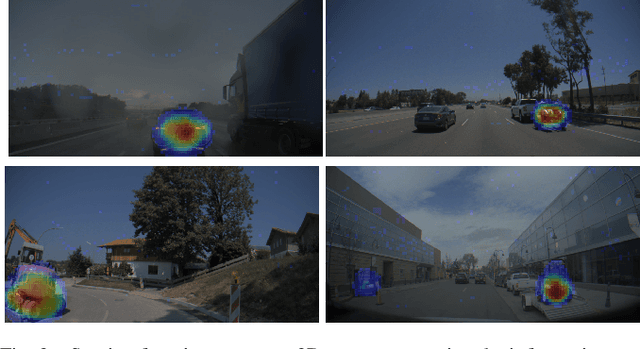

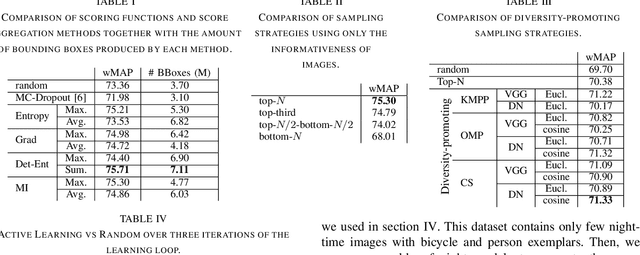
Deep Neural Networks trained in a fully supervised fashion are the dominant technology in perception-based autonomous driving systems. While collecting large amounts of unlabeled data is already a major undertaking, only a subset of it can be labeled by humans due to the effort needed for high-quality annotation. Therefore, finding the right data to label has become a key challenge. Active learning is a powerful technique to improve data efficiency for supervised learning methods, as it aims at selecting the smallest possible training set to reach a required performance. We have built a scalable production system for active learning in the domain of autonomous driving. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, present our current results at scale, and briefly describe the open problems and future directions.
Visual Transfer between Atari Games using Competitive Reinforcement Learning
Sep 02, 2018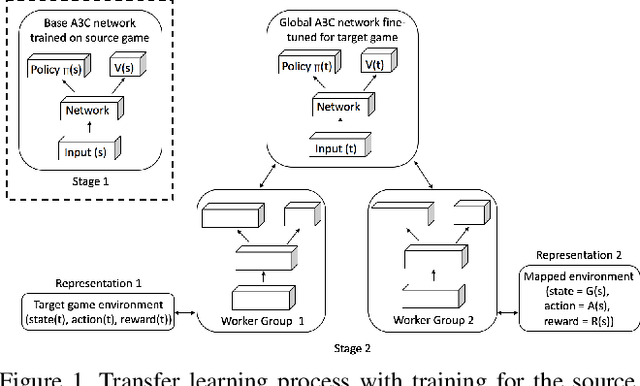
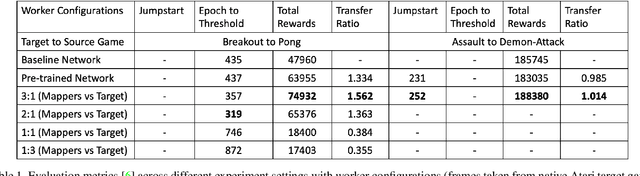
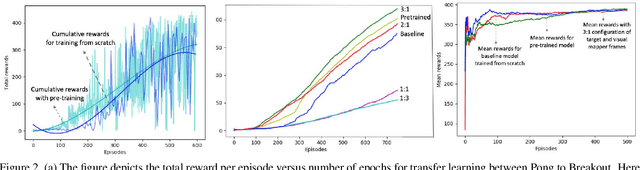
This paper explores the use of deep reinforcement learning agents to transfer knowledge from one environment to another. More specifically, the method takes advantage of asynchronous advantage actor critic (A3C) architecture to generalize a target game using an agent trained on a source game in Atari. Instead of fine-tuning a pre-trained model for the target game, we propose a learning approach to update the model using multiple agents trained in parallel with different representations of the target game. Visual mapping between video sequences of transfer pairs is used to derive new representations of the target game; training on these visual representations of the target game improves model updates in terms of performance, data efficiency and stability. In order to demonstrate the functionality of the architecture, Atari games Pong-v0 and Breakout-v0 are being used from the OpenAI gym environment; as the source and target environment.