 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Levels of AGI: Operationalizing Progress on the Path to AGI
Nov 04, 2023

We propose a framework for classifying the capabilities and behavior of Artificial General Intelligence (AGI) models and their precursors. This framework introduces levels of AGI performance, generality, and autonomy. It is our hope that this framework will be useful in an analogous way to the levels of autonomous driving, by providing a common language to compare models, assess risks, and measure progress along the path to AGI. To develop our framework, we analyze existing definitions of AGI, and distill six principles that a useful ontology for AGI should satisfy. These principles include focusing on capabilities rather than mechanisms; separately evaluating generality and performance; and defining stages along the path toward AGI, rather than focusing on the endpoint. With these principles in mind, we propose 'Levels of AGI' based on depth (performance) and breadth (generality) of capabilities, and reflect on how current systems fit into this ontology. We discuss the challenging requirements for future benchmarks that quantify the behavior and capabilities of AGI models against these levels. Finally, we discuss how these levels of AGI interact with deployment considerations such as autonomy and risk, and emphasize the importance of carefully selecting Human-AI Interaction paradigms for responsible and safe deployment of highly capable AI systems.
Active Learning for Deep Object Detection via Probabilistic Modeling
Mar 30, 2021



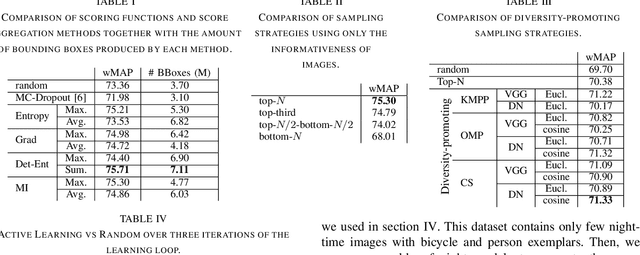
Active learning aims to reduce labeling costs by selecting only the most informative samples on a dataset. Few existing works have addressed active learning for object detection. Most of these methods are based on multiple models or are straightforward extensions of classification methods, hence estimate an image's informativeness using only the classification head. In this paper, we propose a novel deep active learning approach for object detection. Our approach relies on mixture density networks that estimate a probabilistic distribution for each localization and classification head's output. We explicitly estimate the aleatoric and epistemic uncertainty in a single forward pass of a single model. Our method uses a scoring function that aggregates these two types of uncertainties for both heads to obtain every image's informativeness score. We demonstrate the efficacy of our approach in PASCAL VOC and MS-COCO datasets. Our approach outperforms single-model based methods and performs on par with multi-model based methods at a fraction of the computing cost.
Scalable Active Learning for Object Detection
Apr 09, 2020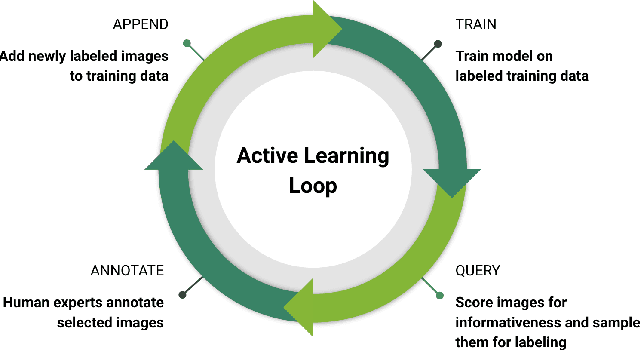
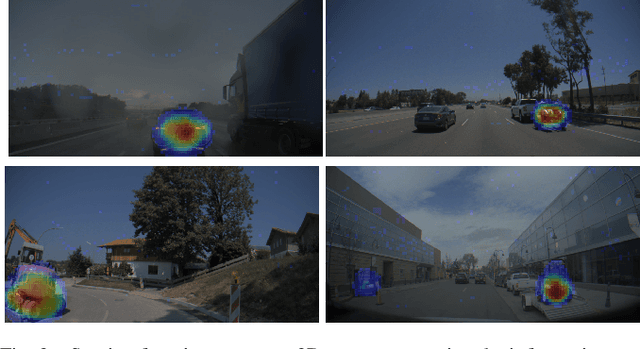

Deep Neural Networks trained in a fully supervised fashion are the dominant technology in perception-based autonomous driving systems. While collecting large amounts of unlabeled data is already a major undertaking, only a subset of it can be labeled by humans due to the effort needed for high-quality annotation. Therefore, finding the right data to label has become a key challenge. Active learning is a powerful technique to improve data efficiency for supervised learning methods, as it aims at selecting the smallest possible training set to reach a required performance. We have built a scalable production system for active learning in the domain of autonomous driving. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, present our current results at scale, and briefly describe the open problems and future directions.
Less is More: An Exploration of Data Redundancy with Active Dataset Subsampling
May 29, 2019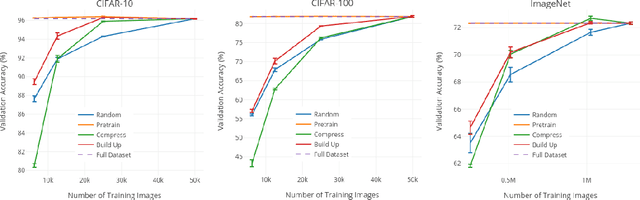

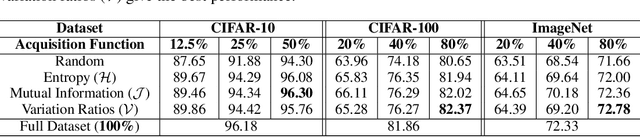

Deep Neural Networks (DNNs) often rely on very large datasets for training. Given the large size of such datasets, it is conceivable that they contain certain samples that either do not contribute or negatively impact the DNN's performance. If there is a large number of such samples, subsampling the training dataset in a way that removes them could provide an effective solution to both improve performance and reduce training time. In this paper, we propose an approach called Active Dataset Subsampling (ADS), to identify favorable subsets within a dataset for training using ensemble based uncertainty estimation. When applied to three image classification benchmarks (CIFAR-10, CIFAR-100 and ImageNet) we find that there are low uncertainty subsets, which can be as large as 50% of the full dataset, that negatively impact performance. These subsets are identified and removed with ADS. We demonstrate that datasets obtained using ADS with a lightweight ResNet-18 ensemble remain effective when used to train deeper models like ResNet-101. Our results provide strong empirical evidence that using all the available data for training can hurt performance on large scale vision tasks.
Clustering Learning for Robotic Vision
Mar 13, 2013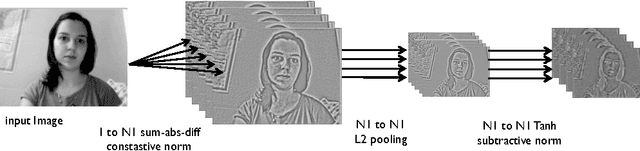
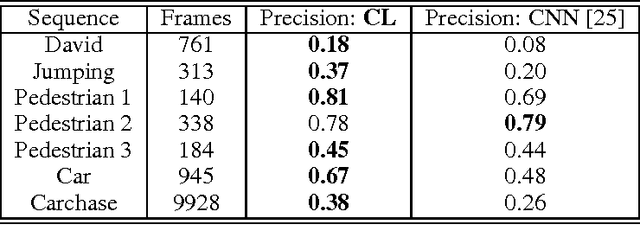

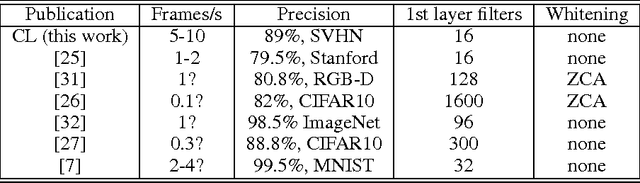
We present the clustering learning technique applied to multi-layer feedforward deep neural networks. We show that this unsupervised learning technique can compute network filters with only a few minutes and a much reduced set of parameters. The goal of this paper is to promote the technique for general-purpose robotic vision systems. We report its use in static image datasets and object tracking datasets. We show that networks trained with clustering learning can outperform large networks trained for many hours on complex datasets.