 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: An Exploration of Data Redundancy with Active Dataset Subsampling
Paper and Code
May 29, 2019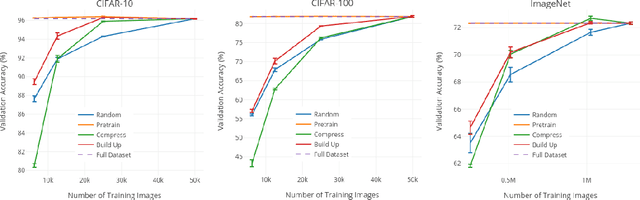

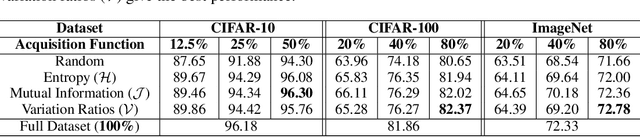

Deep Neural Networks (DNNs) often rely on very large datasets for training. Given the large size of such datasets, it is conceivable that they contain certain samples that either do not contribute or negatively impact the DNN's performance. If there is a large number of such samples, subsampling the training dataset in a way that removes them could provide an effective solution to both improve performance and reduce training time. In this paper, we propose an approach called Active Dataset Subsampling (ADS), to identify favorable subsets within a dataset for training using ensemble based uncertainty estimation. When applied to three image classification benchmarks (CIFAR-10, CIFAR-100 and ImageNet) we find that there are low uncertainty subsets, which can be as large as 50% of the full dataset, that negatively impact performance. These subsets are identified and removed with ADS. We demonstrate that datasets obtained using ADS with a lightweight ResNet-18 ensemble remain effective when used to train deeper models like ResNet-101. Our results provide strong empirical evidence that using all the available data for training can hurt performance on large scale vision tasks.