 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Level Targeted Selection via Deep Template Matching
Jul 05, 2022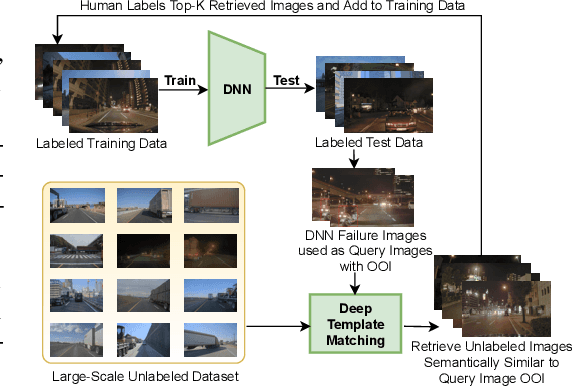
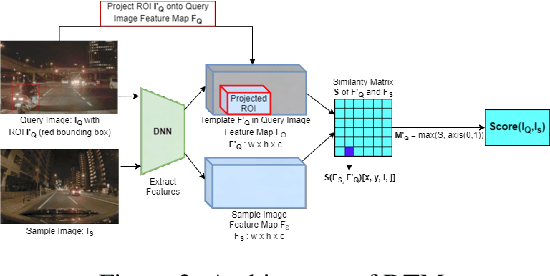
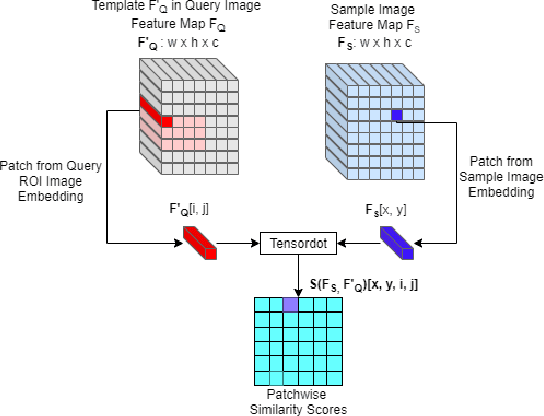
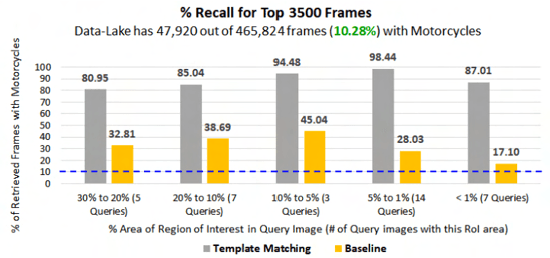
Retrieving images with objects that are semantically similar to objects of interest (OOI) in a query image has many practical use cases. A few examples include fixing failures like false negatives/positives of a learned model or mitigating class imbalance in a dataset. The targeted selection task requires finding the relevant data from a large-scale pool of unlabeled data. Manual mining at this scale is infeasible. Further, the OOI are often small and occupy less than 1% of image area, are occluded, and co-exist with many semantically different objects in cluttered scenes. Existing semantic image retrieval methods often focus on mining for larger sized geographical landmarks, and/or require extra labeled data, such as images/image-pairs with similar objects, for mining images with generic objects. We propose a fast and robust template matching algorithm in the DNN feature space, that retrieves semantically similar images at the object-level from a large unlabeled pool of data. We project the region(s) around the OOI in the query image to the DNN feature space for use as the template. This enables our method to focus on the semantics of the OOI without requiring extra labeled data. In the context of autonomous driving, we evaluate our system for targeted selection by using failure cases of object detectors as OOI. We demonstrate its efficacy on a large unlabeled dataset with 2.2M images and show high recall in mining for images with small-sized OOI. We compare our method against a well-known semantic image retrieval method, which also does not require extra labeled data. Lastly, we show that our method is flexible and retrieves images with one or more semantically different co-occurring OOI seamlessly.
Scalable Active Learning for Object Detection
Apr 09, 2020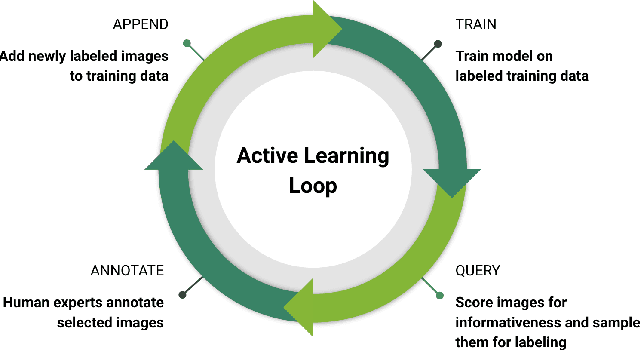
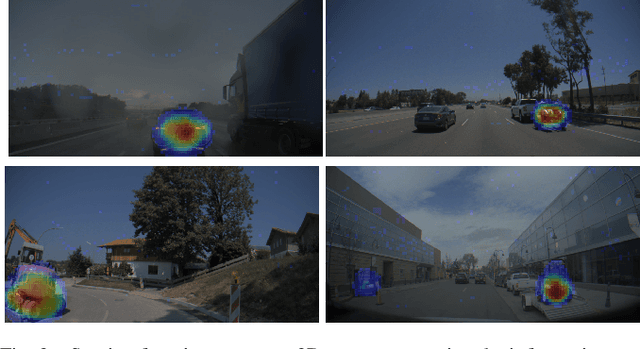

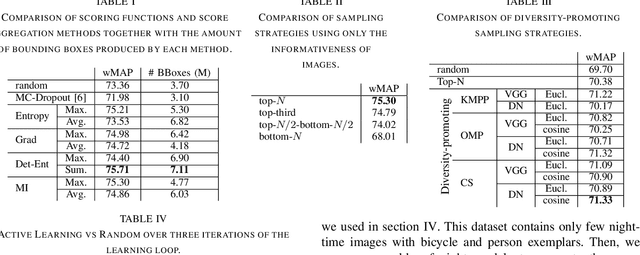
Deep Neural Networks trained in a fully supervised fashion are the dominant technology in perception-based autonomous driving systems. While collecting large amounts of unlabeled data is already a major undertaking, only a subset of it can be labeled by humans due to the effort needed for high-quality annotation. Therefore, finding the right data to label has become a key challenge. Active learning is a powerful technique to improve data efficiency for supervised learning methods, as it aims at selecting the smallest possible training set to reach a required performance. We have built a scalable production system for active learning in the domain of autonomous driving. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, present our current results at scale, and briefly describe the open problems and future directions.
Less is More: An Exploration of Data Redundancy with Active Dataset Subsampling
May 29, 2019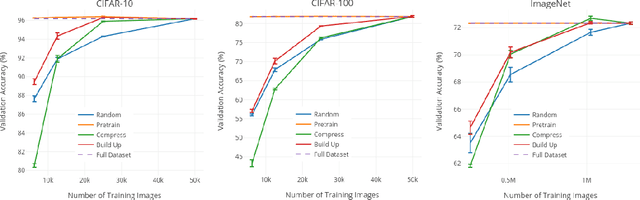

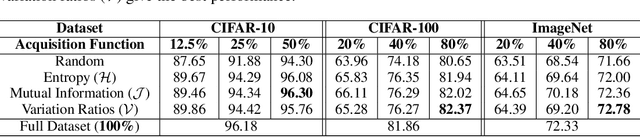

Deep Neural Networks (DNNs) often rely on very large datasets for training. Given the large size of such datasets, it is conceivable that they contain certain samples that either do not contribute or negatively impact the DNN's performance. If there is a large number of such samples, subsampling the training dataset in a way that removes them could provide an effective solution to both improve performance and reduce training time. In this paper, we propose an approach called Active Dataset Subsampling (ADS), to identify favorable subsets within a dataset for training using ensemble based uncertainty estimation. When applied to three image classification benchmarks (CIFAR-10, CIFAR-100 and ImageNet) we find that there are low uncertainty subsets, which can be as large as 50% of the full dataset, that negatively impact performance. These subsets are identified and removed with ADS. We demonstrate that datasets obtained using ADS with a lightweight ResNet-18 ensemble remain effective when used to train deeper models like ResNet-101. Our results provide strong empirical evidence that using all the available data for training can hurt performance on large scale vision tasks.