 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: Minimizing Learner-Expert Asymmetry in End-to-End Driving
Dec 23, 2025Simulators can generate virtually unlimited driving data, yet imitation learning policies in simulation still struggle to achieve robust closed-loop performance. Motivated by this gap, we empirically study how misalignment between privileged expert demonstrations and sensor-based student observations can limit the effectiveness of imitation learning. More precisely, experts have significantly higher visibility (e.g., ignoring occlusions) and far lower uncertainty (e.g., knowing other vehicles' actions), making them difficult to imitate reliably. Furthermore, navigational intent (i.e., the route to follow) is under-specified in student models at test time via only a single target point. We demonstrate that these asymmetries can measurably limit driving performance in CARLA and offer practical interventions to address them. After careful modifications to narrow the gaps between expert and student, our TransFuser v6 (TFv6) student policy achieves a new state of the art on all major publicly available CARLA closed-loop benchmarks, reaching 95 DS on Bench2Drive and more than doubling prior performances on Longest6~v2 and Town13. Additionally, by integrating perception supervision from our dataset into a shared sim-to-real pipeline, we show consistent gains on the NAVSIM and Waymo Vision-Based End-to-End driving benchmarks. Our code, data, and models are publicly available at https://github.com/autonomousvision/lead.
Optimization-Guided Diffusion for Interactive Scene Generation
Dec 11, 2025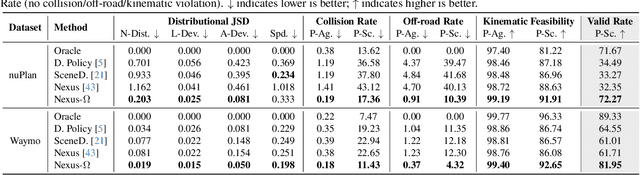
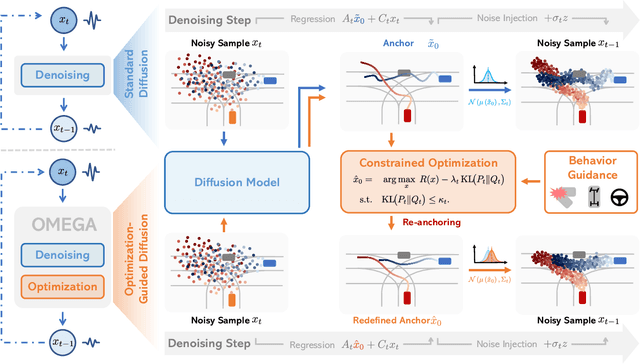
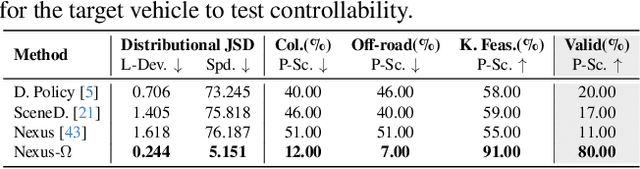
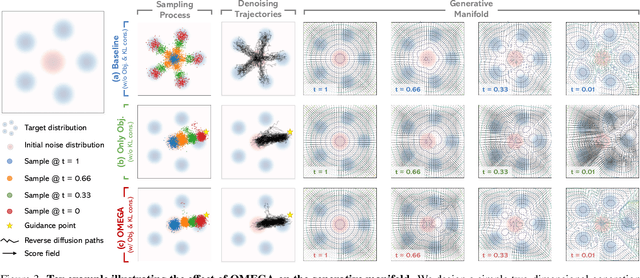
Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate $5\times$ more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
Latent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025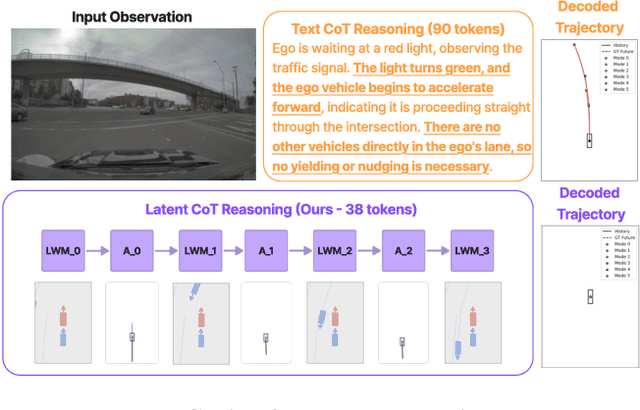
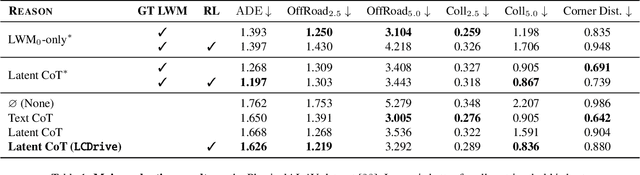
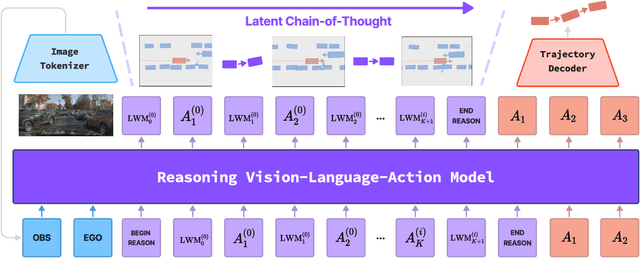
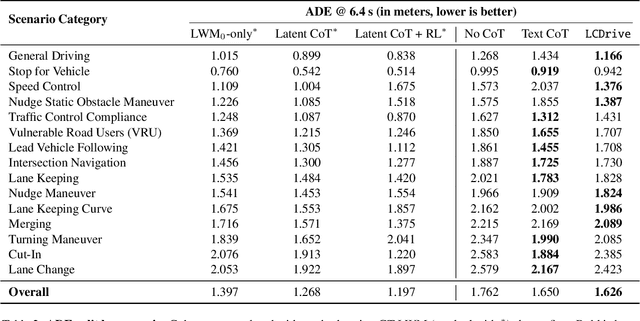
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
ReSim: Reliable World Simulation for Autonomous Driving
Jun 11, 2025How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.
Pseudo-Simulation for Autonomous Driving
Jun 04, 2025Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
CaRL: Learning Scalable Planning Policies with Simple Rewards
Apr 24, 2025We investigate reinforcement learning (RL) for privileged planning in autonomous driving. State-of-the-art approaches for this task are rule-based, but these methods do not scale to the long tail. RL, on the other hand, is scalable and does not suffer from compounding errors like imitation learning. Contemporary RL approaches for driving use complex shaped rewards that sum multiple individual rewards, \eg~progress, position, or orientation rewards. We show that PPO fails to optimize a popular version of these rewards when the mini-batch size is increased, which limits the scalability of these approaches. Instead, we propose a new reward design based primarily on optimizing a single intuitive reward term: route completion. Infractions are penalized by terminating the episode or multiplicatively reducing route completion. We find that PPO scales well with higher mini-batch sizes when trained with our simple reward, even improving performance. Training with large mini-batch sizes enables efficient scaling via distributed data parallelism. We scale PPO to 300M samples in CARLA and 500M samples in nuPlan with a single 8-GPU node. The resulting model achieves 64 DS on the CARLA longest6 v2 benchmark, outperforming other RL methods with more complex rewards by a large margin. Requiring only minimal adaptations from its use in CARLA, the same method is the best learning-based approach on nuPlan. It scores 91.3 in non-reactive and 90.6 in reactive traffic on the Val14 benchmark while being an order of magnitude faster than prior work.
Centaur: Robust End-to-End Autonomous Driving with Test-Time Training
Mar 14, 2025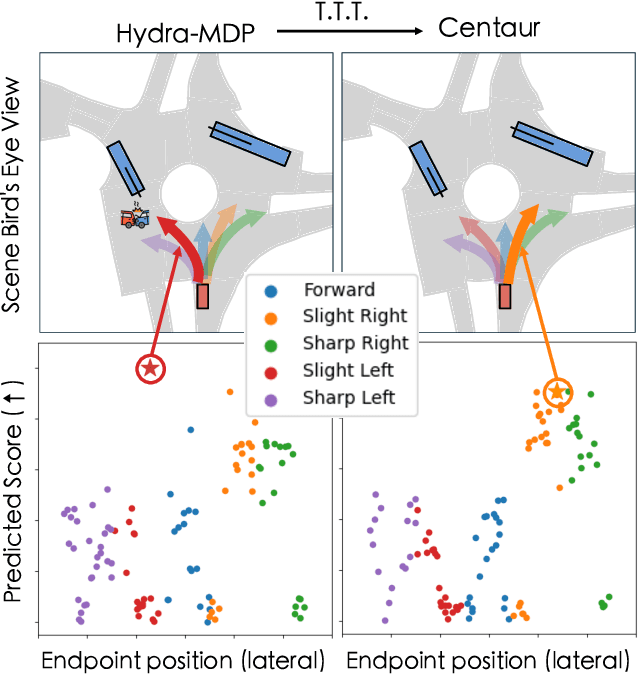



How can we rely on an end-to-end autonomous vehicle's complex decision-making system during deployment? One common solution is to have a ``fallback layer'' that checks the planned trajectory for rule violations and replaces it with a pre-defined safe action if necessary. Another approach involves adjusting the planner's decisions to minimize a pre-defined ``cost function'' using additional system predictions such as road layouts and detected obstacles. However, these pre-programmed rules or cost functions cannot learn and improve with new training data, often resulting in overly conservative behaviors. In this work, we propose Centaur (Cluster Entropy for Test-time trAining using Uncertainty) which updates a planner's behavior via test-time training, without relying on hand-engineered rules or cost functions. Instead, we measure and minimize the uncertainty in the planner's decisions. For this, we develop a novel uncertainty measure, called Cluster Entropy, which is simple, interpretable, and compatible with state-of-the-art planning algorithms. Using data collected at prior test-time time-steps, we perform an update to the model's parameters using a gradient that minimizes the Cluster Entropy. With only this sole gradient update prior to inference, Centaur exhibits significant improvements, ranking first on the navtest leaderboard with notable gains in safety-critical metrics such as time to collision. To provide detailed insights on a per-scenario basis, we also introduce navsafe, a challenging new benchmark, which highlights previously undiscovered failure modes of driving models.
Hidden Biases of End-to-End Driving Datasets
Dec 12, 2024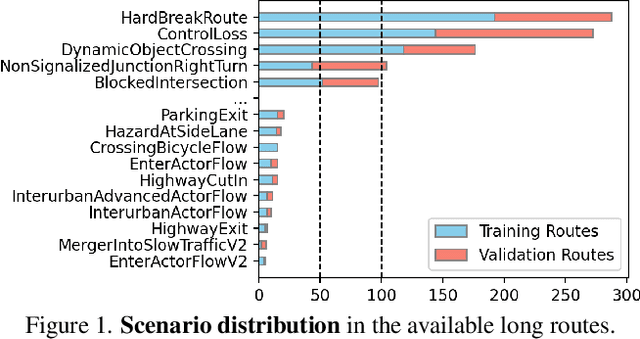

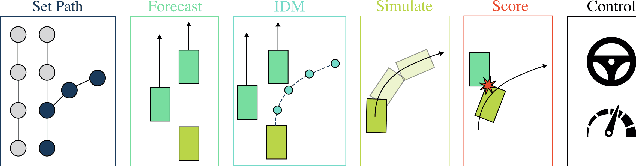
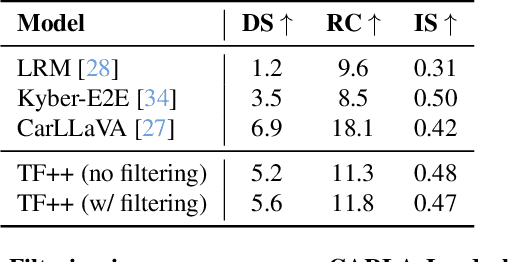
End-to-end driving systems have made rapid progress, but have so far not been applied to the challenging new CARLA Leaderboard 2.0. Further, while there is a large body of literature on end-to-end architectures and training strategies, the impact of the training dataset is often overlooked. In this work, we make a first attempt at end-to-end driving for Leaderboard 2.0. Instead of investigating architectures, we systematically analyze the training dataset, leading to new insights: (1) Expert style significantly affects downstream policy performance. (2) In complex data sets, the frames should not be weighted on the basis of simplistic criteria such as class frequencies. (3) Instead, estimating whether a frame changes the target labels compared to previous frames can reduce the size of the dataset without removing important information. By incorporating these findings, our model ranks first and second respectively on the map and sensors tracks of the 2024 CARLA Challenge, and sets a new state-of-the-art on the Bench2Drive test routes. Finally, we uncover a design flaw in the current evaluation metrics and propose a modification for future challenges. Our dataset, code, and pre-trained models are publicly available at https://github.com/autonomousvision/carla_garage.
NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking
Jun 21, 2024



Benchmarking vision-based driving policies is challenging. On one hand, open-loop evaluation with real data is easy, but these results do not reflect closed-loop performance. On the other, closed-loop evaluation is possible in simulation, but is hard to scale due to its significant computational demands. Further, the simulators available today exhibit a large domain gap to real data. This has resulted in an inability to draw clear conclusions from the rapidly growing body of research on end-to-end autonomous driving. In this paper, we present NAVSIM, a middle ground between these evaluation paradigms, where we use large datasets in combination with a non-reactive simulator to enable large-scale real-world benchmarking. Specifically, we gather simulation-based metrics, such as progress and time to collision, by unrolling bird's eye view abstractions of the test scenes for a short simulation horizon. Our simulation is non-reactive, i.e., the evaluated policy and environment do not influence each other. As we demonstrate empirically, this decoupling allows open-loop metric computation while being better aligned with closed-loop evaluations than traditional displacement errors. NAVSIM enabled a new competition held at CVPR 2024, where 143 teams submitted 463 entries, resulting in several new insights. On a large set of challenging scenarios, we observe that simple methods with moderate compute requirements such as TransFuser can match recent large-scale end-to-end driving architectures such as UniAD. Our modular framework can potentially be extended with new datasets, data curation strategies, and metrics, and will be continually maintained to host future challenges. Our code is available at https://github.com/autonomousvision/navsim.
Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
May 27, 2024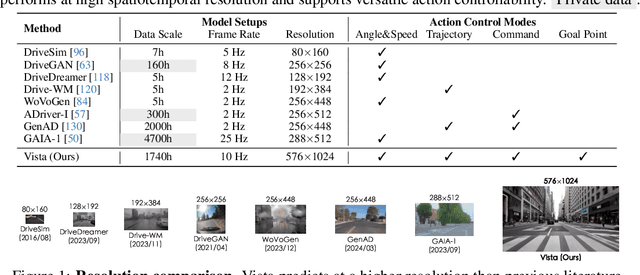


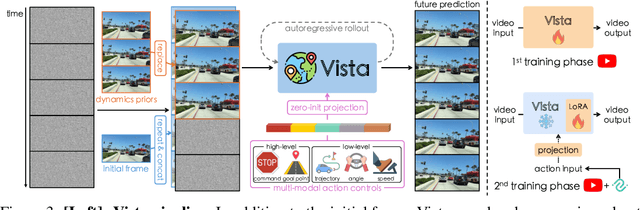
World models can foresee the outcomes of different actions, which is of paramount importance for autonomous driving. Nevertheless, existing driving world models still have limitations in generalization to unseen environments, prediction fidelity of critical details, and action controllability for flexible application. In this paper, we present Vista, a generalizable driving world model with high fidelity and versatile controllability. Based on a systematic diagnosis of existing methods, we introduce several key ingredients to address these limitations. To accurately predict real-world dynamics at high resolution, we propose two novel losses to promote the learning of moving instances and structural information. We also devise an effective latent replacement approach to inject historical frames as priors for coherent long-horizon rollouts. For action controllability, we incorporate a versatile set of controls from high-level intentions (command, goal point) to low-level maneuvers (trajectory, angle, and speed) through an efficient learning strategy. After large-scale training, the capabilities of Vista can seamlessly generalize to different scenarios. Extensive experiments on multiple datasets show that Vista outperforms the most advanced general-purpose video generator in over 70% of comparisons and surpasses the best-performing driving world model by 55% in FID and 27% in FVD. Moreover, for the first time, we utilize the capacity of Vista itself to establish a generalizable reward for real-world action evaluation without accessing the ground truth actions.