 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Fast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving
May 25, 2026End-to-end autonomous driving via Vision-Language-Action (VLA) models demands a precarious balance between high-fidelity trajectory planning and efficient inference. Existing paradigms typically fall short: autoregressive (AR) VLAs are memory-bandwidth-bound on edge hardware and prone to exposure-bias drift, while full-sequence diffusion models preclude KV-cache reuse and suffer from "logical leakage" that violates the fundamental perceive-then-plan causality. We present Fast-dDrive, a block-diffusion VLA that performs bidirectional refinement within semantic units while enforcing strict causal ordering across them. Leveraging the observation that driving VLAs often emit structured JSON-like outputs, Fast-dDrive freezes structural tokens into a section scaffold and employs a section-aware training recipe that prioritizes safety-critical planning. We further introduce Scaffold Speculative Decoding to achieve AR-equivalent quality at significantly higher throughput. Finally, we propose a low-overhead test-time scaling scheme: by forking $N$ stochastic trajectory rollouts from a single shared-prefix KV cache and averaging them, we effectively suppress prediction variance at a fractional computational cost. Empirical results demonstrate that Fast-dDrive redefines the speed-accuracy frontier for driving agents. On the WOD-E2E test set, Fast-dDrive achieves SOTA ADE@3s and ADE@5s, alongside the highest RFS among diffusion-based VLAs; on nuScenes, it reduces average L2 error to $0.32$m (a $22\%$ improvement). When integrated with SGLang, our framework delivers $12\times$ throughput speedup over the AR baseline, narrowing the gap between high-capacity VLAs and the efficiency demands of real-time on-vehicle deployment.
Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Latent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025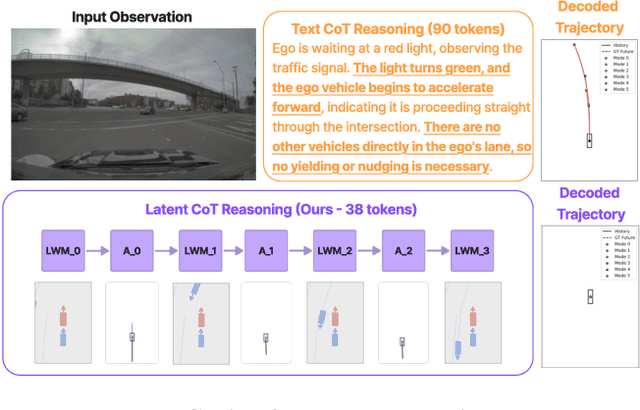
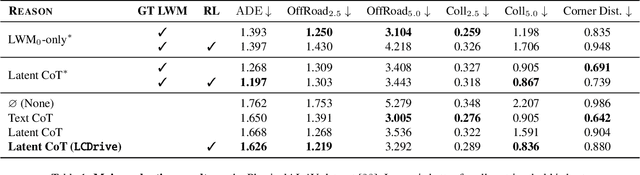
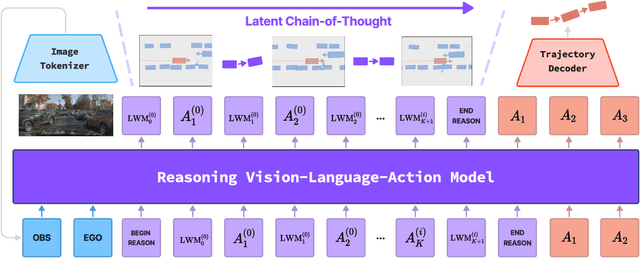
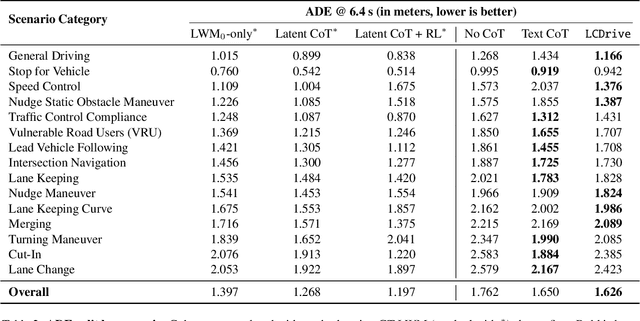
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
RealDrive: Retrieval-Augmented Driving with Diffusion Models
May 30, 2025



Learning-based planners generate natural human-like driving behaviors by learning to reason about nuanced interactions from data, overcoming the rigid behaviors that arise from rule-based planners. Nonetheless, data-driven approaches often struggle with rare, safety-critical scenarios and offer limited controllability over the generated trajectories. To address these challenges, we propose RealDrive, a Retrieval-Augmented Generation (RAG) framework that initializes a diffusion-based planning policy by retrieving the most relevant expert demonstrations from the training dataset. By interpolating between current observations and retrieved examples through a denoising process, our approach enables fine-grained control and safe behavior across diverse scenarios, leveraging the strong prior provided by the retrieved scenario. Another key insight we produce is that a task-relevant retrieval model trained with planning-based objectives results in superior planning performance in our framework compared to a task-agnostic retriever. Experimental results demonstrate improved generalization to long-tail events and enhanced trajectory diversity compared to standard learning-based planners -- we observe a 40% reduction in collision rate on the Waymo Open Motion dataset with RAG.
Surprise Potential as a Measure of Interactivity in Driving Scenarios
Feb 08, 2025Validating the safety and performance of an autonomous vehicle (AV) requires benchmarking on real-world driving logs. However, typical driving logs contain mostly uneventful scenarios with minimal interactions between road users. Identifying interactive scenarios in real-world driving logs enables the curation of datasets that amplify critical signals and provide a more accurate assessment of an AV's performance. In this paper, we present a novel metric that identifies interactive scenarios by measuring an AV's surprise potential on others. First, we identify three dimensions of the design space to describe a family of surprise potential measures. Second, we exhaustively evaluate and compare different instantiations of the surprise potential measure within this design space on the nuScenes dataset. To determine how well a surprise potential measure correctly identifies an interactive scenario, we use a reward model learned from human preferences to assess alignment with human intuition. Our proposed surprise potential, arising from this exhaustive comparative study, achieves a correlation of more than 0.82 with the human-aligned reward function, outperforming existing approaches. Lastly, we validate motion planners on curated interactive scenarios to demonstrate downstream applications.
Cocoon: Robust Multi-Modal Perception with Uncertainty-Aware Sensor Fusion
Oct 16, 2024
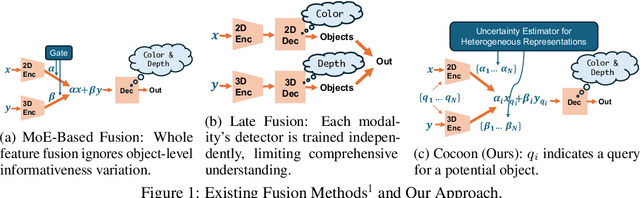
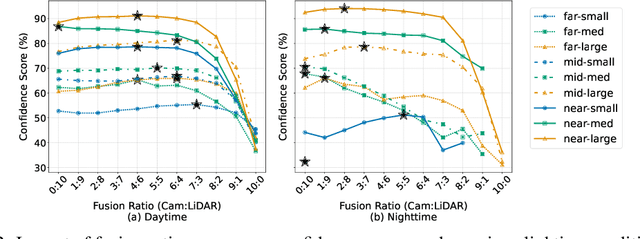
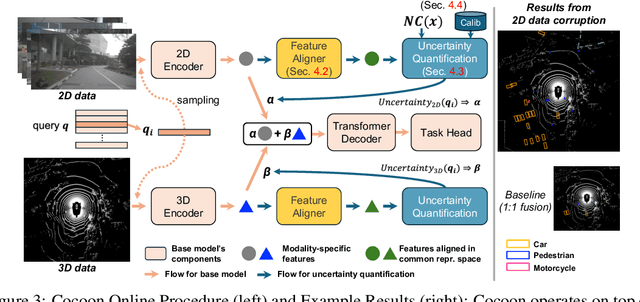
An important paradigm in 3D object detection is the use of multiple modalities to enhance accuracy in both normal and challenging conditions, particularly for long-tail scenarios. To address this, recent studies have explored two directions of adaptive approaches: MoE-based adaptive fusion, which struggles with uncertainties arising from distinct object configurations, and late fusion for output-level adaptive fusion, which relies on separate detection pipelines and limits comprehensive understanding. In this work, we introduce Cocoon, an object- and feature-level uncertainty-aware fusion framework. The key innovation lies in uncertainty quantification for heterogeneous representations, enabling fair comparison across modalities through the introduction of a feature aligner and a learnable surrogate ground truth, termed feature impression. We also define a training objective to ensure that their relationship provides a valid metric for uncertainty quantification. Cocoon consistently outperforms existing static and adaptive methods in both normal and challenging conditions, including those with natural and artificial corruptions. Furthermore, we show the validity and efficacy of our uncertainty metric across diverse datasets.
Gen-Drive: Enhancing Diffusion Generative Driving Policies with Reward Modeling and Reinforcement Learning Fine-tuning
Oct 08, 2024Autonomous driving necessitates the ability to reason about future interactions between traffic agents and to make informed evaluations for planning. This paper introduces the \textit{Gen-Drive} framework, which shifts from the traditional prediction and deterministic planning framework to a generation-then-evaluation planning paradigm. The framework employs a behavior diffusion model as a scene generator to produce diverse possible future scenarios, thereby enhancing the capability for joint interaction reasoning. To facilitate decision-making, we propose a scene evaluator (reward) model, trained with pairwise preference data collected through VLM assistance, thereby reducing human workload and enhancing scalability. Furthermore, we utilize an RL fine-tuning framework to improve the generation quality of the diffusion model, rendering it more effective for planning tasks. We conduct training and closed-loop planning tests on the nuPlan dataset, and the results demonstrate that employing such a generation-then-evaluation strategy outperforms other learning-based approaches. Additionally, the fine-tuned generative driving policy shows significant enhancements in planning performance. We further demonstrate that utilizing our learned reward model for evaluation or RL fine-tuning leads to better planning performance compared to relying on human-designed rewards. Project website: https://mczhi.github.io/GenDrive.
Promptable Closed-loop Traffic Simulation
Sep 09, 2024


Simulation stands as a cornerstone for safe and efficient autonomous driving development. At its core a simulation system ought to produce realistic, reactive, and controllable traffic patterns. In this paper, we propose ProSim, a multimodal promptable closed-loop traffic simulation framework. ProSim allows the user to give a complex set of numerical, categorical or textual prompts to instruct each agent's behavior and intention. ProSim then rolls out a traffic scenario in a closed-loop manner, modeling each agent's interaction with other traffic participants. Our experiments show that ProSim achieves high prompt controllability given different user prompts, while reaching competitive performance on the Waymo Sim Agents Challenge when no prompt is given. To support research on promptable traffic simulation, we create ProSim-Instruct-520k, a multimodal prompt-scenario paired driving dataset with over 10M text prompts for over 520k real-world driving scenarios. We will release code of ProSim as well as data and labeling tools of ProSim-Instruct-520k at https://ariostgx.github.io/ProSim.
Language-Image Models with 3D Understanding
May 06, 2024Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.