 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025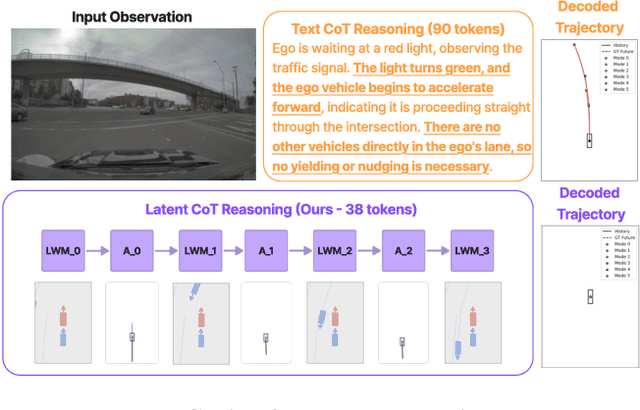
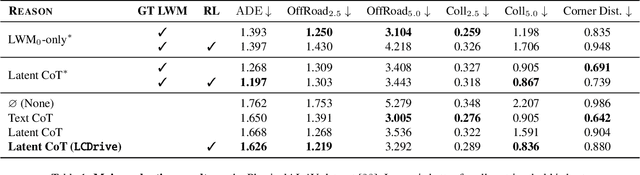
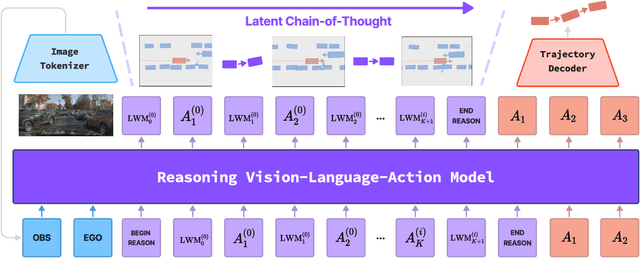
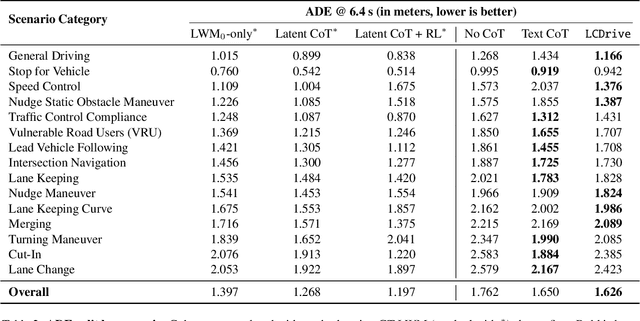
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
Interactive Post-Training for Vision-Language-Action Models
May 22, 2025We introduce RIPT-VLA, a simple and scalable reinforcement-learning-based interactive post-training paradigm that fine-tunes pretrained Vision-Language-Action (VLA) models using only sparse binary success rewards. Existing VLA training pipelines rely heavily on offline expert demonstration data and supervised imitation, limiting their ability to adapt to new tasks and environments under low-data regimes. RIPT-VLA addresses this by enabling interactive post-training with a stable policy optimization algorithm based on dynamic rollout sampling and leave-one-out advantage estimation. RIPT-VLA has the following characteristics. First, it applies to various VLA models, resulting in an improvement on the lightweight QueST model by 21.2%, and the 7B OpenVLA-OFT model to an unprecedented 97.5% success rate. Second, it is computationally efficient and data-efficient: with only one demonstration, RIPT-VLA enables an unworkable SFT model (4%) to succeed with a 97% success rate within 15 iterations. Furthermore, we demonstrate that the policy learned by RIPT-VLA generalizes across different tasks and scenarios and is robust to the initial state context. These results highlight RIPT-VLA as a practical and effective paradigm for post-training VLA models through minimal supervision.
Promptable Closed-loop Traffic Simulation
Sep 09, 2024


Simulation stands as a cornerstone for safe and efficient autonomous driving development. At its core a simulation system ought to produce realistic, reactive, and controllable traffic patterns. In this paper, we propose ProSim, a multimodal promptable closed-loop traffic simulation framework. ProSim allows the user to give a complex set of numerical, categorical or textual prompts to instruct each agent's behavior and intention. ProSim then rolls out a traffic scenario in a closed-loop manner, modeling each agent's interaction with other traffic participants. Our experiments show that ProSim achieves high prompt controllability given different user prompts, while reaching competitive performance on the Waymo Sim Agents Challenge when no prompt is given. To support research on promptable traffic simulation, we create ProSim-Instruct-520k, a multimodal prompt-scenario paired driving dataset with over 10M text prompts for over 520k real-world driving scenarios. We will release code of ProSim as well as data and labeling tools of ProSim-Instruct-520k at https://ariostgx.github.io/ProSim.
Wolf: Captioning Everything with a World Summarization Framework
Jul 26, 2024



We propose Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf is an automated captioning framework that adopts a mixture-of-experts approach, leveraging complementary strengths of Vision Language Models (VLMs). By utilizing both image and video models, our framework captures different levels of information and summarizes them efficiently. Our approach can be applied to enhance video understanding, auto-labeling, and captioning. To evaluate caption quality, we introduce CapScore, an LLM-based metric to assess the similarity and quality of generated captions compared to the ground truth captions. We further build four human-annotated datasets in three domains: autonomous driving, general scenes, and robotics, to facilitate comprehensive comparisons. We show that Wolf achieves superior captioning performance compared to state-of-the-art approaches from the research community (VILA1.5, CogAgent) and commercial solutions (Gemini-Pro-1.5, GPT-4V). For instance, in comparison with GPT-4V, Wolf improves CapScore both quality-wise by 55.6% and similarity-wise by 77.4% on challenging driving videos. Finally, we establish a benchmark for video captioning and introduce a leaderboard, aiming to accelerate advancements in video understanding, captioning, and data alignment. Leaderboard: https://wolfv0.github.io/leaderboard.html.
Language Conditioned Traffic Generation
Jul 16, 2023Simulation forms the backbone of modern self-driving development. Simulators help develop, test, and improve driving systems without putting humans, vehicles, or their environment at risk. However, simulators face a major challenge: They rely on realistic, scalable, yet interesting content. While recent advances in rendering and scene reconstruction make great strides in creating static scene assets, modeling their layout, dynamics, and behaviors remains challenging. In this work, we turn to language as a source of supervision for dynamic traffic scene generation. Our model, LCTGen, combines a large language model with a transformer-based decoder architecture that selects likely map locations from a dataset of maps, and produces an initial traffic distribution, as well as the dynamics of each vehicle. LCTGen outperforms prior work in both unconditional and conditional traffic scene generation in terms of realism and fidelity. Code and video will be available at https://ariostgx.github.io/lctgen.
EgoDistill: Egocentric Head Motion Distillation for Efficient Video Understanding
Jan 05, 2023Recent advances in egocentric video understanding models are promising, but their heavy computational expense is a barrier for many real-world applications. To address this challenge, we propose EgoDistill, a distillation-based approach that learns to reconstruct heavy egocentric video clip features by combining the semantics from a sparse set of video frames with the head motion from lightweight IMU readings. We further devise a novel self-supervised training strategy for IMU feature learning. Our method leads to significant improvements in efficiency, requiring 200x fewer GFLOPs than equivalent video models. We demonstrate its effectiveness on the Ego4D and EPICKitchens datasets, where our method outperforms state-of-the-art efficient video understanding methods.
TrafficGen: Learning to Generate Diverse and Realistic Traffic Scenarios
Oct 12, 2022
Diverse and realistic traffic scenarios are crucial for evaluating the AI safety of autonomous driving systems in simulation. This work introduces a data-driven method called TrafficGen for traffic scenario generation. It learns from the fragmented human driving data collected in the real world and then can generate realistic traffic scenarios. TrafficGen is an autoregressive generative model with an encoder-decoder architecture. In each autoregressive iteration, it first encodes the current traffic context with the attention mechanism and then decodes a vehicle's initial state followed by generating its long trajectory. We evaluate the trained model in terms of vehicle placement and trajectories and show substantial improvements over baselines. TrafficGen can be also used to augment existing traffic scenarios, by adding new vehicles and extending the fragmented trajectories. We further demonstrate that importing the generated scenarios into a simulator as interactive training environments improves the performance and the safety of driving policy learned from reinforcement learning. More project resource is available at https://metadriverse.github.io/trafficgen
SceneGen: Learning to Generate Realistic Traffic Scenes
Jan 16, 2021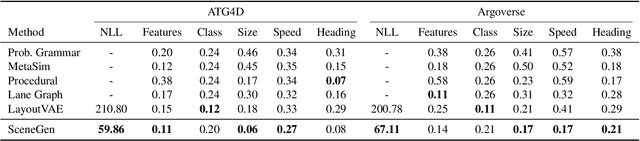
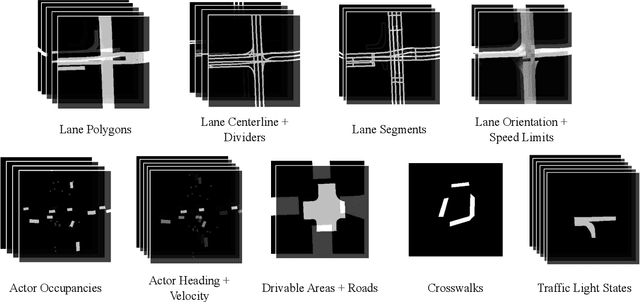
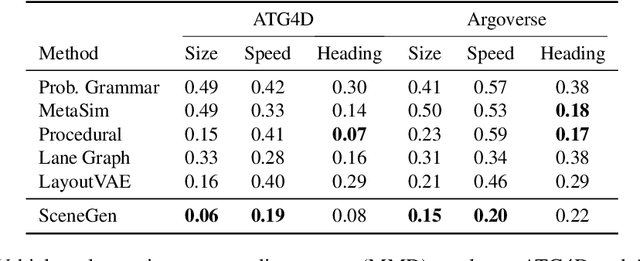

We consider the problem of generating realistic traffic scenes automatically. Existing methods typically insert actors into the scene according to a set of hand-crafted heuristics and are limited in their ability to model the true complexity and diversity of real traffic scenes, thus inducing a content gap between synthesized traffic scenes versus real ones. As a result, existing simulators lack the fidelity necessary to train and test self-driving vehicles. To address this limitation, we present SceneGen, a neural autoregressive model of traffic scenes that eschews the need for rules and heuristics. In particular, given the ego-vehicle state and a high definition map of surrounding area, SceneGen inserts actors of various classes into the scene and synthesizes their sizes, orientations, and velocities. We demonstrate on two large-scale datasets SceneGen's ability to faithfully model distributions of real traffic scenes. Moreover, we show that SceneGen coupled with sensor simulation can be used to train perception models that generalize to the real world.
Improving the Fairness of Deep Generative Models without Retraining
Dec 09, 2020
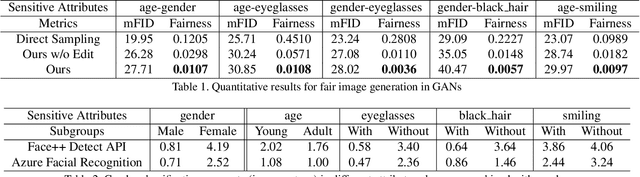
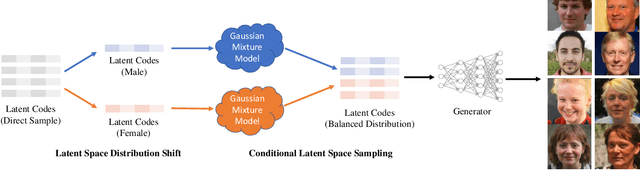

Generative Adversarial Networks (GANs) have recently advanced face synthesis by learning the underlying distribution of observed data. However, it will lead to a biased image generation due to the imbalanced training data or the mode collapse issue. Prior work typically addresses the fairness of data generation by balancing the training data that correspond to the concerned attributes. In this work, we propose a simple yet effective method to improve the fairness of image generation for a pre-trained GAN model without retraining. We utilize the recent work of GAN interpretation to identify the directions in the latent space corresponding to the target attributes, and then manipulate a set of latent codes with balanced attribute distributions over output images. We learn a Gaussian Mixture Model (GMM) to fit a distribution of the latent code set, which supports the sampling of latent codes for producing images with a more fair attribute distribution. Experiments show that our method can substantially improve the fairness of image generation, outperforming potential baselines both quantitatively and qualitatively. The images generated from our method are further applied to reveal and quantify the biases in commercial face classifiers and face super-resolution model.
LiDARsim: Realistic LiDAR Simulation by Leveraging the Real World
Jun 16, 2020
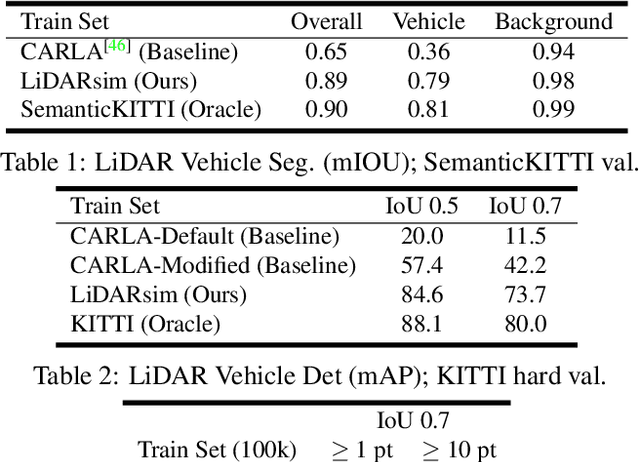
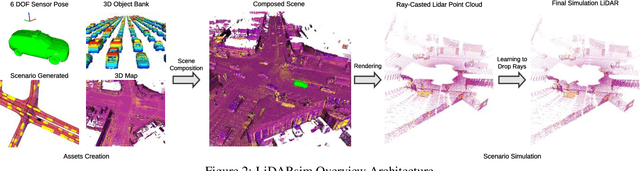

We tackle the problem of producing realistic simulations of LiDAR point clouds, the sensor of preference for most self-driving vehicles. We argue that, by leveraging real data, we can simulate the complex world more realistically compared to employing virtual worlds built from CAD/procedural models. Towards this goal, we first build a large catalog of 3D static maps and 3D dynamic objects by driving around several cities with our self-driving fleet. We can then generate scenarios by selecting a scene from our catalog and "virtually" placing the self-driving vehicle (SDV) and a set of dynamic objects from the catalog in plausible locations in the scene. To produce realistic simulations, we develop a novel simulator that captures both the power of physics-based and learning-based simulation. We first utilize ray casting over the 3D scene and then use a deep neural network to produce deviations from the physics-based simulation, producing realistic LiDAR point clouds. We showcase LiDARsim's usefulness for perception algorithms-testing on long-tail events and end-to-end closed-loop evaluation on safety-critical scenarios.