 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning-aligned Token Compression for Long-Context Autonomous Driving
Jun 05, 2026Monolithic vision-action models represent an emerging paradigm in autonomous driving. However, this architecture produces token sequences that quickly exceed real-time computational budgets when encoding extended temporal context for complex interactions. While approaches like linear transformers and external memory try to make the context lightweight, token compression is most compatible with the architecture as it requires no backbone modifications. Yet existing compression adopts rule-based heuristics like temporal decay, decoupled from planning, risking loss of decision-critical information. We propose COMPACT-VA, a planning-aligned working memory framework built on conditional VQ-VAE, compressing extended context into bounded representations. Compression is conditioned on both historical trajectory and a learned planning intent that the posterior encoder distills from future trajectories during training, while the prior encoder learns to predict it from compressed observations. The compressed memory, concatenated with the predicted latent, feeds the policy for end-to-end optimization, planning with retained decision-critical information. We evaluate on high-signal dynamic scenarios where historical context is most critical for behavior correctness (e.g., stop, yield, or proceed), and accordingly design behavioral metrics. Under comparable token budgets, we achieve $>$6% improvement (68.3%) on success rates with consistent gains across metrics. Ablations validate planning-aligned coupling effectiveness. Closed-loop evaluation confirms that COMPACT-VA maintained general driving performance with 3.3* speedup and 2.7* memory reduction over uncompressed processing.
X4Val: Learning Neural Surrogates for Variance-Reduced Policy Evaluation
Jun 03, 2026Rigorous evaluation of learning-based robotic systems is an essential prerequisite for deployment. However, real-world test data is expensive to gather; moreover, in a typical iterative development context, data gathered from the latest policy is necessarily limited in scale. This motivates evaluation methodologies that make use of heterogeneous data sources, including simulation, historical policy logs, and data collected from related platforms or environments. While such auxiliary data are abundant and inexpensive, they are generally not directly representative of real-world outcomes -- for example, performance in simulation may differ substantially from performance in the real world -- making their principled use for high-confidence performance estimation challenging. In this paper, we introduce X4Val, a general framework for variance-reduced real-world metric estimation in the presence of non-paired, multi-domain data. X4Val embeds samples from real and auxiliary domains into a shared representation space and learns a transferable predictor of real-world metrics; this learned predictor is then incorporated into a control-variates estimator, enabling variance reduction even when paired samples are unavailable. We provide theoretical analysis and empirical evaluations on autonomous driving and real-world robot manipulation tasks, domains across which X4Val achieves up to 38.4% variance reduction and demonstrates consistent improvements over strong baselines. These results show that non-paired, heterogeneous data can be leveraged to substantially improve the sample efficiency of rigorous robotic system validation.
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Fast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving
May 25, 2026End-to-end autonomous driving via Vision-Language-Action (VLA) models demands a precarious balance between high-fidelity trajectory planning and efficient inference. Existing paradigms typically fall short: autoregressive (AR) VLAs are memory-bandwidth-bound on edge hardware and prone to exposure-bias drift, while full-sequence diffusion models preclude KV-cache reuse and suffer from "logical leakage" that violates the fundamental perceive-then-plan causality. We present Fast-dDrive, a block-diffusion VLA that performs bidirectional refinement within semantic units while enforcing strict causal ordering across them. Leveraging the observation that driving VLAs often emit structured JSON-like outputs, Fast-dDrive freezes structural tokens into a section scaffold and employs a section-aware training recipe that prioritizes safety-critical planning. We further introduce Scaffold Speculative Decoding to achieve AR-equivalent quality at significantly higher throughput. Finally, we propose a low-overhead test-time scaling scheme: by forking $N$ stochastic trajectory rollouts from a single shared-prefix KV cache and averaging them, we effectively suppress prediction variance at a fractional computational cost. Empirical results demonstrate that Fast-dDrive redefines the speed-accuracy frontier for driving agents. On the WOD-E2E test set, Fast-dDrive achieves SOTA ADE@3s and ADE@5s, alongside the highest RFS among diffusion-based VLAs; on nuScenes, it reduces average L2 error to $0.32$m (a $22\%$ improvement). When integrated with SGLang, our framework delivers $12\times$ throughput speedup over the AR baseline, narrowing the gap between high-capacity VLAs and the efficiency demands of real-time on-vehicle deployment.
Accelerating Structured Chain-of-Thought in Autonomous Vehicles
Feb 02, 2026Chain-of-Thought (CoT) reasoning enhances the decision-making capabilities of vision-language-action models in autonomous driving, but its autoregressive nature introduces significant inference latency, making it impractical for real-time applications. To address this, we introduce FastDriveCoT, a novel parallel decoding method that accelerates template-structured CoT. Our approach decomposes the reasoning process into a dependency graph of distinct sub-tasks, such as identifying critical objects and summarizing traffic rules, some of which can be generated in parallel. By generating multiple independent reasoning steps concurrently within a single forward pass, we significantly reduce the number of sequential computations. Experiments demonstrate a 3-4$\times$ speedup in CoT generation and a substantial reduction in end-to-end latency across various model architectures, all while preserving the original downstream task improvements brought by incorporating CoT reasoning.
Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Towards Efficient and Effective Multi-Camera Encoding for End-to-End Driving
Dec 12, 2025We present Flex, an efficient and effective scene encoder that addresses the computational bottleneck of processing high-volume multi-camera data in end-to-end autonomous driving. Flex employs a small set of learnable scene tokens to jointly encode information from all image tokens across different cameras and timesteps. By design, our approach is geometry-agnostic, learning a compact scene representation directly from data without relying on the explicit 3D inductive biases, such as Bird-Eye-View (BEV), occupancy or tri-plane representations, which are common in prior work. This holistic encoding strategy aggressively compresses the visual input for the downstream Large Language Model (LLM) based policy model. Evaluated on a large-scale proprietary dataset of 20,000 driving hours, our Flex achieves 2.2x greater inference throughput while improving driving performance by a large margin compared to state-of-the-art methods. Furthermore, we show that these compact scene tokens develop an emergent capability for scene decomposition without any explicit supervision. Our findings challenge the prevailing assumption that 3D priors are necessary, demonstrating that a data-driven, joint encoding strategy offers a more scalable, efficient and effective path for future autonomous driving systems.
FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
Dec 11, 2025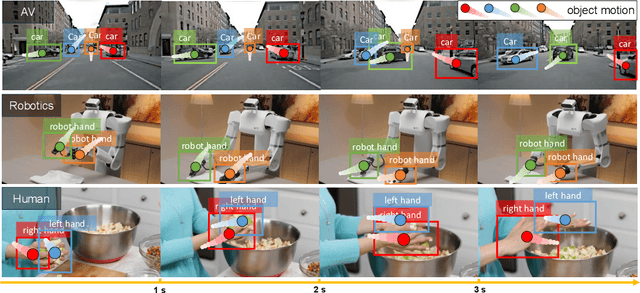
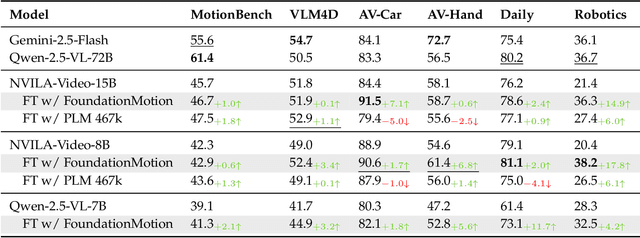
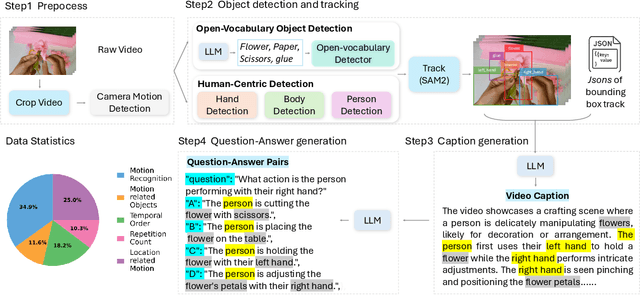

Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.
Latent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025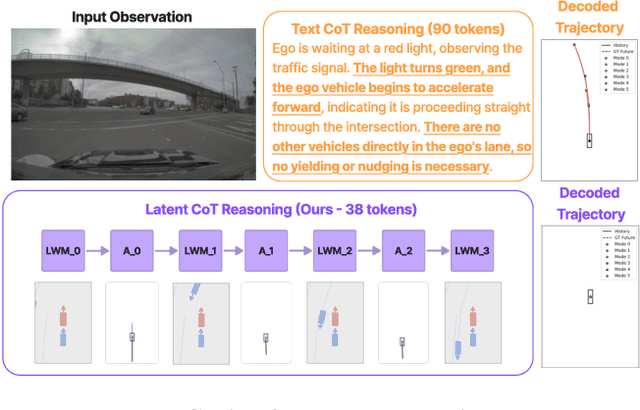
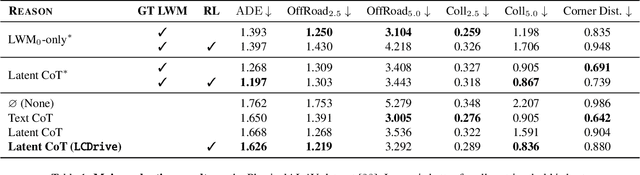
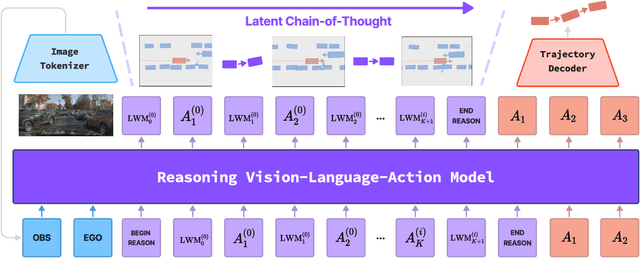
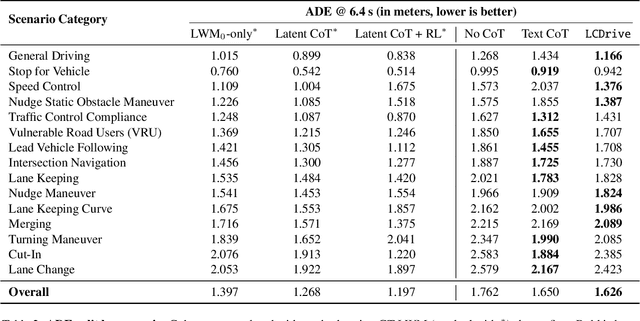
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
UDON: Uncertainty-weighted Distributed Optimization for Multi-Robot Neural Implicit Mapping under Extreme Communication Constraints
Sep 16, 2025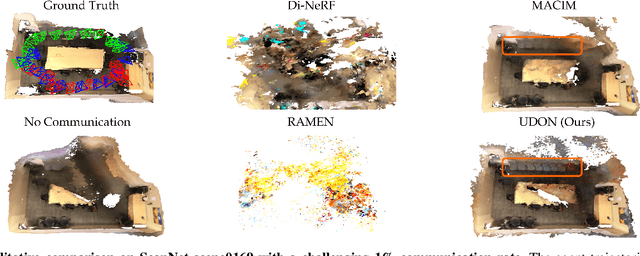
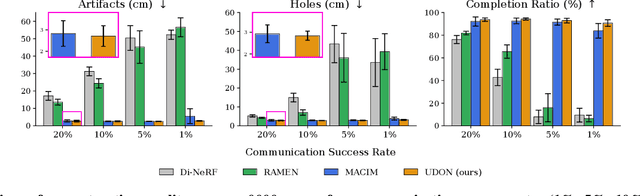
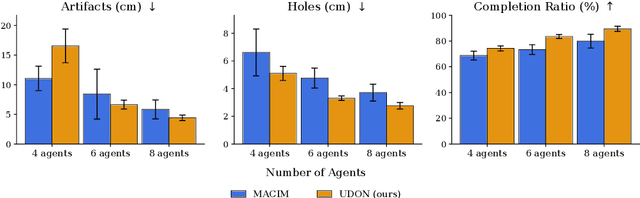
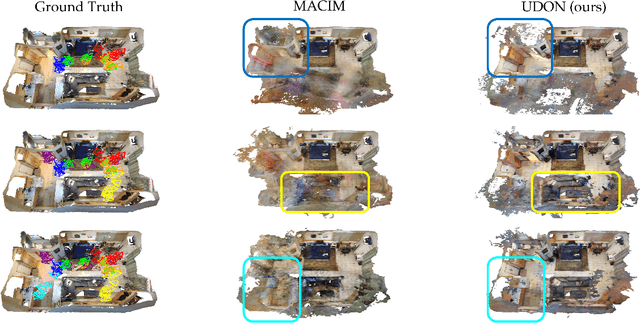
Multi-robot mapping with neural implicit representations enables the compact reconstruction of complex environments. However, it demands robustness against communication challenges like packet loss and limited bandwidth. While prior works have introduced various mechanisms to mitigate communication disruptions, performance degradation still occurs under extremely low communication success rates. This paper presents UDON, a real-time multi-agent neural implicit mapping framework that introduces a novel uncertainty-weighted distributed optimization to achieve high-quality mapping under severe communication deterioration. The uncertainty weighting prioritizes more reliable portions of the map, while the distributed optimization isolates and penalizes mapping disagreement between individual pairs of communicating agents. We conduct extensive experiments on standard benchmark datasets and real-world robot hardware. We demonstrate that UDON significantly outperforms existing baselines, maintaining high-fidelity reconstructions and consistent scene representations even under extreme communication degradation (as low as 1% success rate).