 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Nonlinear Optimization: Many Problems One GPU
Jun 24, 2026Many robotics problems, including trajectory optimization, inverse kinematics, and contact-rich motion planning, reduce to nonlinear programs (NLPs). Mature NLP solvers such as IPOPT can solve these problems, offering hard constraint satisfaction, optimality guarantees, and favorable scaling with problem dimension. These solvers underpin gradient-based methods in robotics, yet remain CPU-bound and solve only one problem at a time, preventing their integration into GPU-batched learning pipelines. On the other hand, sampling-based approaches such as reinforcement learning, model predictive path integral, and imitation learning have become the core of modern robotics research due to their ability to leverage GPU-batched simulators. These simulators can generate orders of magnitude more dynamics rollouts per second than was previously possible. If a GPU-batched NLP solver existed, it would unlock similar speedups in the number of constrained, locally optimal solutions generated per second. This regime of solving many problems concurrently versus solving a single problem at a time is a key requirement for integrating NLP solvers in modern GPU-batched robotics frameworks. To this end, we introduce \texttt{jaxipm}, the first GPU-batched NLP solver, based on IPOPT, and implemented in JAX. We accomplish this by redesigning IPOPT's algorithm to eliminate control flow with \textit{heterogeneous iteration fusion}, and by minimizing GPU idle time with \textit{iteration level batching}. We evaluate \texttt{jaxipm} on a variety of quadrotor nonlinear model predictive control benchmarks, including reference tracking in the presence of obstacles, multi-quadrotor navigation without collision, and navigation in a cluttered environment. We demonstrate up to a $32.85\times$ increase in throughput over IPOPT. Our complete open-source codebase is available at https://github.com/johnviljoen/jaxipm.
Learning Control Policies to Provably Satisfy Hard Affine Constraints for Black-Box Hybrid Dynamical Systems
Apr 24, 2026Ensuring safety for black-box hybrid dynamical systems presents significant challenges due to their instantaneous state jumps and unknown explicit nonlinear dynamics. Existing solutions for strict safety constraint satisfaction, like control barrier functions (CBFs) and reachability analysis, rely on direct knowledge of the dynamics. Similarly, safe reinforcement learning (RL) approaches often rely on known system dynamics or merely discourage safety violations through reward shaping. In this work, we want to learn RL policies which provably satisfy affine state constraints in closed loop for black-box hybrid dynamical systems with affine reset maps. Our key insight is forcing the RL policy to be affine and repulsive near the constraint boundaries for the unknown nonlinear dynamics of the system, providing guarantees that the trajectories will not violate the constraint. We further account for constraint violation due to instantaneous state jumps that occur due to impacts or reset maps in the hybrid system by introducing a second repulsive affine region before the reset that prevents post-reset states from violating the constraint. We derive sufficient conditions under which these policies satisfy safety constraints in closed loop. We also compare our approach with state-of-the-art reward shaping and learned-CBF methods on hybrid dynamical systems like the constrained pendulum and paddle juggler environments. In both scenarios, we show that our methodology learns higher quality policies while always satisfying the safety constraints.
Matching Multiple Experts: On the Exploitability of Multi-Agent Imitation Learning
Feb 24, 2026Multi-agent imitation learning (MA-IL) aims to learn optimal policies from expert demonstrations of interactions in multi-agent interactive domains. Despite existing guarantees on the performance of the resulting learned policies, characterizations of how far the learned polices are from a Nash equilibrium are missing for offline MA-IL. In this paper, we demonstrate impossibility and hardness results of learning low-exploitable policies in general $n$-player Markov Games. We do so by providing examples where even exact measure matching fails, and demonstrating a new hardness result on characterizing the Nash gap given a fixed measure matching error. We then show how these challenges can be overcome using strategic dominance assumptions on the expert equilibrium. Specifically, for the case of dominant strategy expert equilibria, assuming Behavioral Cloning error $ε_{\text{BC}}$, this provides a Nash imitation gap of $\mathcal{O}\left(nε_{\text{BC}}/(1-γ)^2\right)$ for a discount factor $γ$. We generalize this result with a new notion of best-response continuity, and argue that this is implicitly encouraged by standard regularization techniques.
TACO: Temporal Consensus Optimization for Continual Neural Mapping
Feb 05, 2026Neural implicit mapping has emerged as a powerful paradigm for robotic navigation and scene understanding. However, real-world robotic deployment requires continual adaptation to changing environments under strict memory and computation constraints, which existing mapping systems fail to support. Most prior methods rely on replaying historical observations to preserve consistency and assume static scenes. As a result, they cannot adapt to continual learning in dynamic robotic settings. To address these challenges, we propose TACO (TemporAl Consensus Optimization), a replay-free framework for continual neural mapping. We reformulate mapping as a temporal consensus optimization problem, where we treat past model snapshots as temporal neighbors. Intuitively, our approach resembles a model consulting its own past knowledge. We update the current map by enforcing weighted consensus with historical representations. Our method allows reliable past geometry to constrain optimization while permitting unreliable or outdated regions to be revised in response to new observations. TACO achieves a balance between memory efficiency and adaptability without storing or replaying previous data. Through extensive simulated and real-world experiments, we show that TACO robustly adapts to scene changes, and consistently outperforms other continual learning baselines.
CRAFT: Coaching Reinforcement Learning Autonomously using Foundation Models for Multi-Robot Coordination Tasks
Sep 17, 2025



Multi-Agent Reinforcement Learning (MARL) provides a powerful framework for learning coordination in multi-agent systems. However, applying MARL to robotics still remains challenging due to high-dimensional continuous joint action spaces, complex reward design, and non-stationary transitions inherent to decentralized settings. On the other hand, humans learn complex coordination through staged curricula, where long-horizon behaviors are progressively built upon simpler skills. Motivated by this, we propose CRAFT: Coaching Reinforcement learning Autonomously using Foundation models for multi-robot coordination Tasks, a framework that leverages the reasoning capabilities of foundation models to act as a "coach" for multi-robot coordination. CRAFT automatically decomposes long-horizon coordination tasks into sequences of subtasks using the planning capability of Large Language Models (LLMs). In what follows, CRAFT trains each subtask using reward functions generated by LLM, and refines them through a Vision Language Model (VLM)-guided reward-refinement loop. We evaluate CRAFT on multi-quadruped navigation and bimanual manipulation tasks, demonstrating its capability to learn complex coordination behaviors. In addition, we validate the multi-quadruped navigation policy in real hardware experiments.
MIMIC-D: Multi-modal Imitation for MultI-agent Coordination with Decentralized Diffusion Policies
Sep 17, 2025As robots become more integrated in society, their ability to coordinate with other robots and humans on multi-modal tasks (those with multiple valid solutions) is crucial. We propose to learn such behaviors from expert demonstrations via imitation learning (IL). However, when expert demonstrations are multi-modal, standard IL approaches can struggle to capture the diverse strategies, hindering effective coordination. Diffusion models are known to be effective at handling complex multi-modal trajectory distributions in single-agent systems. Diffusion models have also excelled in multi-agent scenarios where multi-modality is more common and crucial to learning coordinated behaviors. Typically, diffusion-based approaches require a centralized planner or explicit communication among agents, but this assumption can fail in real-world scenarios where robots must operate independently or with agents like humans that they cannot directly communicate with. Therefore, we propose MIMIC-D, a Centralized Training, Decentralized Execution (CTDE) paradigm for multi-modal multi-agent imitation learning using diffusion policies. Agents are trained jointly with full information, but execute policies using only local information to achieve implicit coordination. We demonstrate in both simulation and hardware experiments that our method recovers multi-modal coordination behavior among agents in a variety of tasks and environments, while improving upon state-of-the-art baselines.
UDON: Uncertainty-weighted Distributed Optimization for Multi-Robot Neural Implicit Mapping under Extreme Communication Constraints
Sep 16, 2025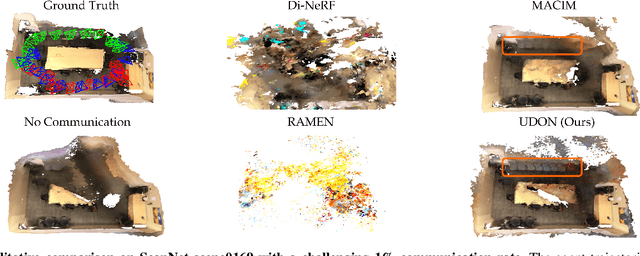
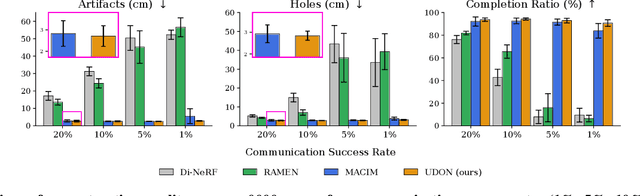
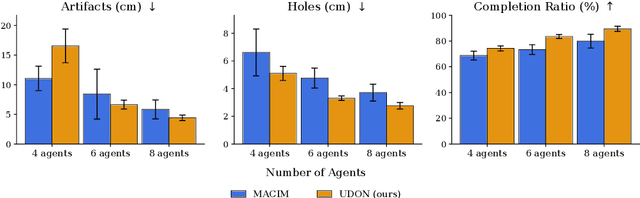
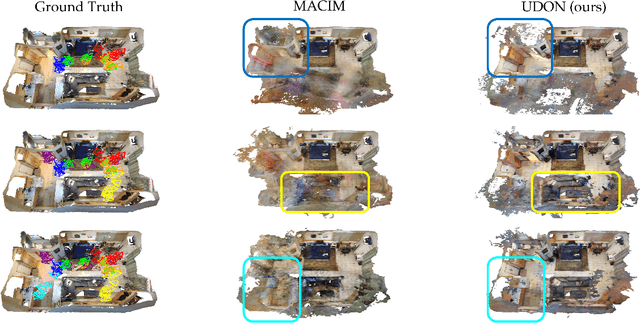
Multi-robot mapping with neural implicit representations enables the compact reconstruction of complex environments. However, it demands robustness against communication challenges like packet loss and limited bandwidth. While prior works have introduced various mechanisms to mitigate communication disruptions, performance degradation still occurs under extremely low communication success rates. This paper presents UDON, a real-time multi-agent neural implicit mapping framework that introduces a novel uncertainty-weighted distributed optimization to achieve high-quality mapping under severe communication deterioration. The uncertainty weighting prioritizes more reliable portions of the map, while the distributed optimization isolates and penalizes mapping disagreement between individual pairs of communicating agents. We conduct extensive experiments on standard benchmark datasets and real-world robot hardware. We demonstrate that UDON significantly outperforms existing baselines, maintaining high-fidelity reconstructions and consistent scene representations even under extreme communication degradation (as low as 1% success rate).
RAMEN: Real-time Asynchronous Multi-agent Neural Implicit Mapping
Feb 26, 2025Multi-agent neural implicit mapping allows robots to collaboratively capture and reconstruct complex environments with high fidelity. However, existing approaches often rely on synchronous communication, which is impractical in real-world scenarios with limited bandwidth and potential communication interruptions. This paper introduces RAMEN: Real-time Asynchronous Multi-agEnt Neural implicit mapping, a novel approach designed to address this challenge. RAMEN employs an uncertainty-weighted multi-agent consensus optimization algorithm that accounts for communication disruptions. When communication is lost between a pair of agents, each agent retains only an outdated copy of its neighbor's map, with the uncertainty of this copy increasing over time since the last communication. Using gradient update information, we quantify the uncertainty associated with each parameter of the neural network map. Neural network maps from different agents are brought to consensus on the basis of their levels of uncertainty, with consensus biased towards network parameters with lower uncertainty. To achieve this, we derive a weighted variant of the decentralized consensus alternating direction method of multipliers (C-ADMM) algorithm, facilitating robust collaboration among agents with varying communication and update frequencies. Through extensive evaluations on real-world datasets and robot hardware experiments, we demonstrate RAMEN's superior mapping performance under challenging communication conditions.
DDAT: Diffusion Policies Enforcing Dynamically Admissible Robot Trajectories
Feb 20, 2025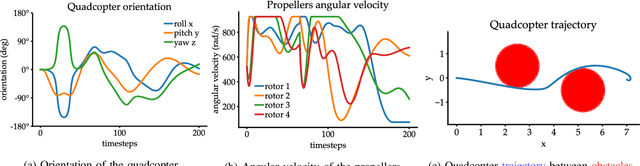
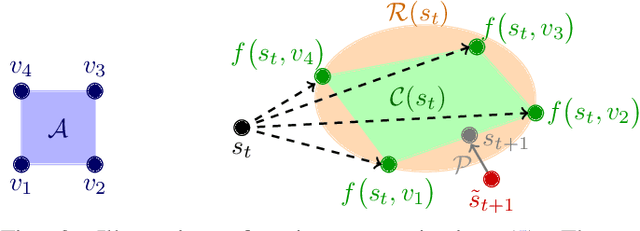
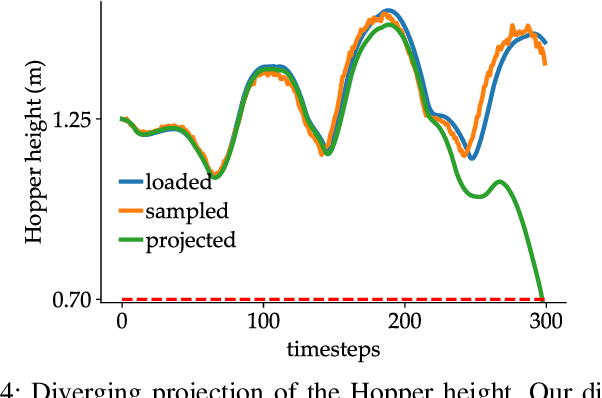
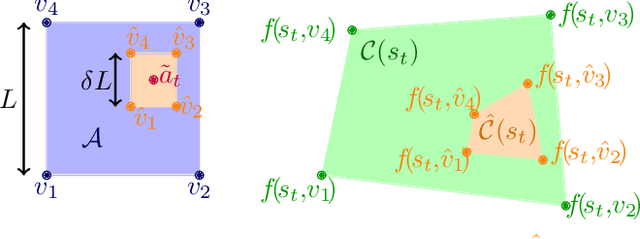
Diffusion models excel at creating images and videos thanks to their multimodal generative capabilities. These same capabilities have made diffusion models increasingly popular in robotics research, where they are used for generating robot motion. However, the stochastic nature of diffusion models is fundamentally at odds with the precise dynamical equations describing the feasible motion of robots. Hence, generating dynamically admissible robot trajectories is a challenge for diffusion models. To alleviate this issue, we introduce DDAT: Diffusion policies for Dynamically Admissible Trajectories to generate provably admissible trajectories of black-box robotic systems using diffusion models. A sequence of states is a dynamically admissible trajectory if each state of the sequence belongs to the reachable set of its predecessor by the robot's equations of motion. To generate such trajectories, our diffusion policies project their predictions onto a dynamically admissible manifold during both training and inference to align the objective of the denoiser neural network with the dynamical admissibility constraint. The auto-regressive nature of these projections along with the black-box nature of robot dynamics render these projections immensely challenging. We thus enforce admissibility by iteratively sampling a polytopic under-approximation of the reachable set of a state onto which we project its predicted successor, before iterating this process with the projected successor. By producing accurate trajectories, this projection eliminates the need for diffusion models to continually replan, enabling one-shot long-horizon trajectory planning. We demonstrate that our framework generates higher quality dynamically admissible robot trajectories through extensive simulations on a quadcopter and various MuJoCo environments, along with real-world experiments on a Unitree GO1 and GO2.
Risk-Sensitive Orbital Debris Collision Avoidance using Distributionally Robust Chance Constraints
Dec 23, 2024



The exponential increase in orbital debris and active satellites will lead to congested orbits, necessitating more frequent collision avoidance maneuvers by satellites. To minimize fuel consumption while ensuring the safety of satellites, enforcing a chance constraint, which poses an upper bound in collision probability with debris, can serve as an intuitive safety measure. However, accurately evaluating collision probability, which is critical for the effective implementation of chance constraints, remains a non-trivial task. This difficulty arises because uncertainty propagation in nonlinear orbit dynamics typically provides only limited information, such as finite samples or moment estimates about the underlying arbitrary non-Gaussian distributions. Furthermore, even if the full distribution were known, it remains unclear how to effectively compute chance constraints with such non-Gaussian distributions. To address these challenges, we propose a distributionally robust chance-constrained collision avoidance algorithm that provides a sufficient condition for collision probabilities under limited information about the underlying non-Gaussian distribution. Our distributionally robust approach satisfies the chance constraint for all debris position distributions sharing a given mean and covariance, thereby enabling the enforcement of chance constraints with limited distributional information. To achieve computational tractability, the chance constraint is approximated using a Conditional Value-at-Risk (CVaR) constraint, which gives a conservative and tractable approximation of the distributionally robust chance constraint. We validate our algorithm on a real-world inspired satellite-debris conjunction scenario with different uncertainty propagation methods and show that our controller can effectively avoid collisions.