 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Robust Deep Reconstruction for Free-Breathing Cardiac Cine MRI
May 20, 2026Conventional cardiac cine MRI relies on breath-hold Cartesian acquisitions, which are vulnerable to motion artifacts and can be uncomfortable or infeasible, particularly for pediatric and other noncompliant patients who cannot reliably hold their breath. Free-breathing radial acquisitions can alleviate these limitations, but robust reconstruction at high acceleration remains challenging due to prominent streak artifacts. To address these limitations, we propose Cine-DL, a clinically oriented framework that couples targeted k-space preprocessing with fast, model-based deep reconstruction. In this pipeline, raw free-breathing radial data undergo retrospective cardiac binning and respiratory gating to resolve cardiac phases and discard motion-corrupted spokes. We then introduce Streak Optimized Coil Compression (SOC), which explicitly preserves cardiac signals while suppressing peripheral interference that typically drives the streak artifacts. The resulting 2D+t cine series is reconstructed with an unrolled network that alternates a ResNet proximal operator with physics-based data consistency updates solved via conjugate gradient. We further employ a memory-efficient training strategy that reduces peak memory usage. We evaluate Cine-DL on free-breathing volunteer data against established baselines (k-t SENSE and iGRASP) and demonstrate clinical translation via hospital deployment on newly acquired patient data. Our experiments show that Cine-DL consistently improves quantitative metrics and visual fidelity, supporting a practical route toward routine, time-sensitive clinical adoption of free-breathing cine MRI.
CRAFT: Coaching Reinforcement Learning Autonomously using Foundation Models for Multi-Robot Coordination Tasks
Sep 17, 2025



Multi-Agent Reinforcement Learning (MARL) provides a powerful framework for learning coordination in multi-agent systems. However, applying MARL to robotics still remains challenging due to high-dimensional continuous joint action spaces, complex reward design, and non-stationary transitions inherent to decentralized settings. On the other hand, humans learn complex coordination through staged curricula, where long-horizon behaviors are progressively built upon simpler skills. Motivated by this, we propose CRAFT: Coaching Reinforcement learning Autonomously using Foundation models for multi-robot coordination Tasks, a framework that leverages the reasoning capabilities of foundation models to act as a "coach" for multi-robot coordination. CRAFT automatically decomposes long-horizon coordination tasks into sequences of subtasks using the planning capability of Large Language Models (LLMs). In what follows, CRAFT trains each subtask using reward functions generated by LLM, and refines them through a Vision Language Model (VLM)-guided reward-refinement loop. We evaluate CRAFT on multi-quadruped navigation and bimanual manipulation tasks, demonstrating its capability to learn complex coordination behaviors. In addition, we validate the multi-quadruped navigation policy in real hardware experiments.
IANN-MPPI: Interaction-Aware Neural Network-Enhanced Model Predictive Path Integral Approach for Autonomous Driving
Jul 16, 2025Motion planning for autonomous vehicles (AVs) in dense traffic is challenging, often leading to overly conservative behavior and unmet planning objectives. This challenge stems from the AVs' limited ability to anticipate and respond to the interactive behavior of surrounding agents. Traditional decoupled prediction and planning pipelines rely on non-interactive predictions that overlook the fact that agents often adapt their behavior in response to the AV's actions. To address this, we propose Interaction-Aware Neural Network-Enhanced Model Predictive Path Integral (IANN-MPPI) control, which enables interactive trajectory planning by predicting how surrounding agents may react to each control sequence sampled by MPPI. To improve performance in structured lane environments, we introduce a spline-based prior for the MPPI sampling distribution, enabling efficient lane-changing behavior. We evaluate IANN-MPPI in a dense traffic merging scenario, demonstrating its ability to perform efficient merging maneuvers. Our project website is available at https://sites.google.com/berkeley.edu/iann-mppi
DDAT: Diffusion Policies Enforcing Dynamically Admissible Robot Trajectories
Feb 20, 2025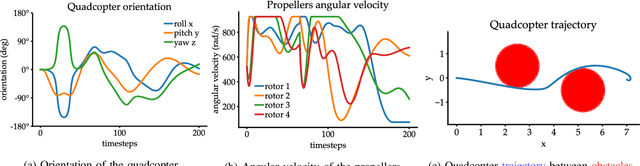
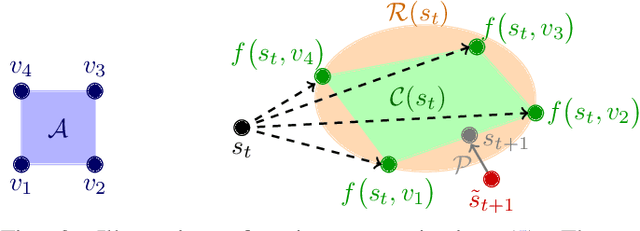
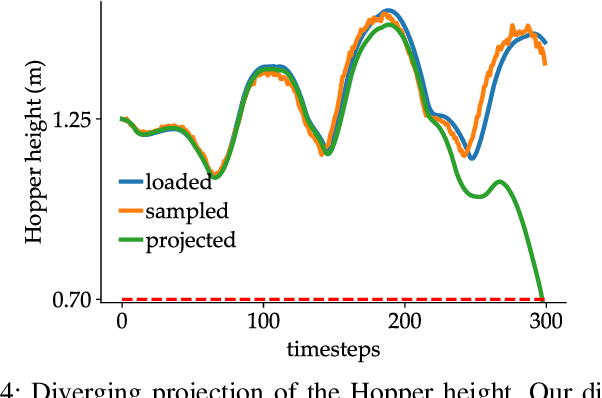
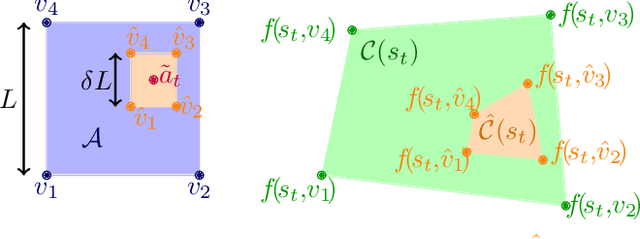
Diffusion models excel at creating images and videos thanks to their multimodal generative capabilities. These same capabilities have made diffusion models increasingly popular in robotics research, where they are used for generating robot motion. However, the stochastic nature of diffusion models is fundamentally at odds with the precise dynamical equations describing the feasible motion of robots. Hence, generating dynamically admissible robot trajectories is a challenge for diffusion models. To alleviate this issue, we introduce DDAT: Diffusion policies for Dynamically Admissible Trajectories to generate provably admissible trajectories of black-box robotic systems using diffusion models. A sequence of states is a dynamically admissible trajectory if each state of the sequence belongs to the reachable set of its predecessor by the robot's equations of motion. To generate such trajectories, our diffusion policies project their predictions onto a dynamically admissible manifold during both training and inference to align the objective of the denoiser neural network with the dynamical admissibility constraint. The auto-regressive nature of these projections along with the black-box nature of robot dynamics render these projections immensely challenging. We thus enforce admissibility by iteratively sampling a polytopic under-approximation of the reachable set of a state onto which we project its predicted successor, before iterating this process with the projected successor. By producing accurate trajectories, this projection eliminates the need for diffusion models to continually replan, enabling one-shot long-horizon trajectory planning. We demonstrate that our framework generates higher quality dynamically admissible robot trajectories through extensive simulations on a quadcopter and various MuJoCo environments, along with real-world experiments on a Unitree GO1 and GO2.
Risk-Sensitive Orbital Debris Collision Avoidance using Distributionally Robust Chance Constraints
Dec 23, 2024



The exponential increase in orbital debris and active satellites will lead to congested orbits, necessitating more frequent collision avoidance maneuvers by satellites. To minimize fuel consumption while ensuring the safety of satellites, enforcing a chance constraint, which poses an upper bound in collision probability with debris, can serve as an intuitive safety measure. However, accurately evaluating collision probability, which is critical for the effective implementation of chance constraints, remains a non-trivial task. This difficulty arises because uncertainty propagation in nonlinear orbit dynamics typically provides only limited information, such as finite samples or moment estimates about the underlying arbitrary non-Gaussian distributions. Furthermore, even if the full distribution were known, it remains unclear how to effectively compute chance constraints with such non-Gaussian distributions. To address these challenges, we propose a distributionally robust chance-constrained collision avoidance algorithm that provides a sufficient condition for collision probabilities under limited information about the underlying non-Gaussian distribution. Our distributionally robust approach satisfies the chance constraint for all debris position distributions sharing a given mean and covariance, thereby enabling the enforcement of chance constraints with limited distributional information. To achieve computational tractability, the chance constraint is approximated using a Conditional Value-at-Risk (CVaR) constraint, which gives a conservative and tractable approximation of the distributionally robust chance constraint. We validate our algorithm on a real-world inspired satellite-debris conjunction scenario with different uncertainty propagation methods and show that our controller can effectively avoid collisions.
CurricuLLM: Automatic Task Curricula Design for Learning Complex Robot Skills using Large Language Models
Sep 27, 2024Curriculum learning is a training mechanism in reinforcement learning (RL) that facilitates the achievement of complex policies by progressively increasing the task difficulty during training. However, designing effective curricula for a specific task often requires extensive domain knowledge and human intervention, which limits its applicability across various domains. Our core idea is that large language models (LLMs), with their extensive training on diverse language data and ability to encapsulate world knowledge, present significant potential for efficiently breaking down tasks and decomposing skills across various robotics environments. Additionally, the demonstrated success of LLMs in translating natural language into executable code for RL agents strengthens their role in generating task curricula. In this work, we propose CurricuLLM, which leverages the high-level planning and programming capabilities of LLMs for curriculum design, thereby enhancing the efficient learning of complex target tasks. CurricuLLM consists of: (Step 1) Generating sequence of subtasks that aid target task learning in natural language form, (Step 2) Translating natural language description of subtasks in executable task code, including the reward code and goal distribution code, and (Step 3) Evaluating trained policies based on trajectory rollout and subtask description. We evaluate CurricuLLM in various robotics simulation environments, ranging from manipulation, navigation, and locomotion, to show that CurricuLLM can aid learning complex robot control tasks. In addition, we validate humanoid locomotion policy learned through CurricuLLM in real-world. The code is provided in https://github.com/labicon/CurricuLLM
Adaptive Teaching in Heterogeneous Agents: Balancing Surprise in Sparse Reward Scenarios
May 23, 2024Learning from Demonstration (LfD) can be an efficient way to train systems with analogous agents by enabling ``Student'' agents to learn from the demonstrations of the most experienced ``Teacher'' agent, instead of training their policy in parallel. However, when there are discrepancies in agent capabilities, such as divergent actuator power or joint angle constraints, naively replicating demonstrations that are out of bounds for the Student's capability can limit efficient learning. We present a Teacher-Student learning framework specifically tailored to address the challenge of heterogeneity between the Teacher and Student agents. Our framework is based on the concept of ``surprise'', inspired by its application in exploration incentivization in sparse-reward environments. Surprise is repurposed to enable the Teacher to detect and adapt to differences between itself and the Student. By focusing on maximizing its surprise in response to the environment while concurrently minimizing the Student's surprise in response to the demonstrations, the Teacher agent can effectively tailor its demonstrations to the Student's specific capabilities and constraints. We validate our method by demonstrating improvements in the Student's learning in control tasks within sparse-reward environments.
Integrating Predictive Motion Uncertainties with Distributionally Robust Risk-Aware Control for Safe Robot Navigation in Crowds
Mar 08, 2024



Ensuring safe navigation in human-populated environments is crucial for autonomous mobile robots. Although recent advances in machine learning offer promising methods to predict human trajectories in crowded areas, it remains unclear how one can safely incorporate these learned models into a control loop due to the uncertain nature of human motion, which can make predictions of these models imprecise. In this work, we address this challenge and introduce a distributionally robust chance-constrained model predictive control (DRCC-MPC) which: (i) adopts a probability of collision as a pre-specified, interpretable risk metric, and (ii) offers robustness against discrepancies between actual human trajectories and their predictions. We consider the risk of collision in the form of a chance constraint, providing an interpretable measure of robot safety. To enable real-time evaluation of chance constraints, we consider conservative approximations of chance constraints in the form of distributionally robust Conditional Value at Risk constraints. The resulting formulation offers computational efficiency as well as robustness with respect to out-of-distribution human motion. With the parallelization of a sampling-based optimization technique, our method operates in real-time, demonstrating successful and safe navigation in a number of case studies with real-world pedestrian data.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.