 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Scaling Laws for End-to-End Autonomous Driving
Apr 06, 2025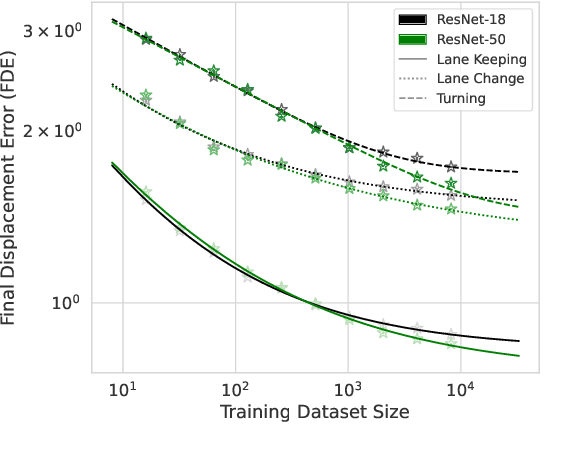
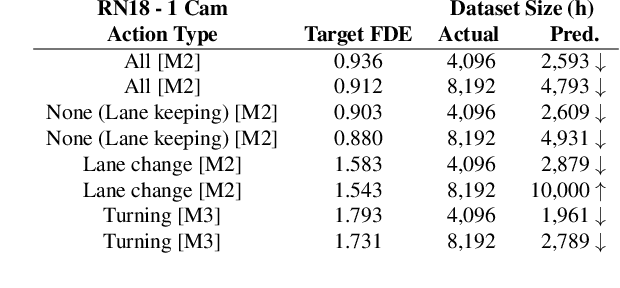

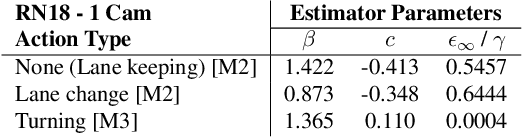
Autonomous vehicle (AV) stacks have traditionally relied on decomposed approaches, with separate modules handling perception, prediction, and planning. However, this design introduces information loss during inter-module communication, increases computational overhead, and can lead to compounding errors. To address these challenges, recent works have proposed architectures that integrate all components into an end-to-end differentiable model, enabling holistic system optimization. This shift emphasizes data engineering over software integration, offering the potential to enhance system performance by simply scaling up training resources. In this work, we evaluate the performance of a simple end-to-end driving architecture on internal driving datasets ranging in size from 16 to 8192 hours with both open-loop metrics and closed-loop simulations. Specifically, we investigate how much additional training data is needed to achieve a target performance gain, e.g., a 5% improvement in motion prediction accuracy. By understanding the relationship between model performance and training dataset size, we aim to provide insights for data-driven decision-making in autonomous driving development.
ERASE-Net: Efficient Segmentation Networks for Automotive Radar Signals
Sep 26, 2022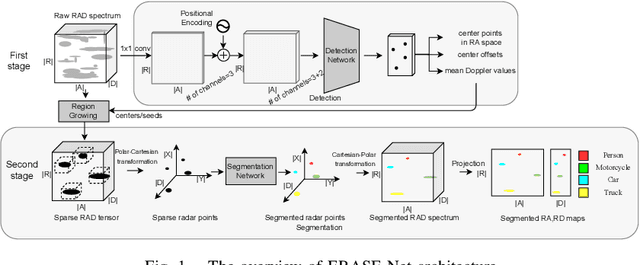


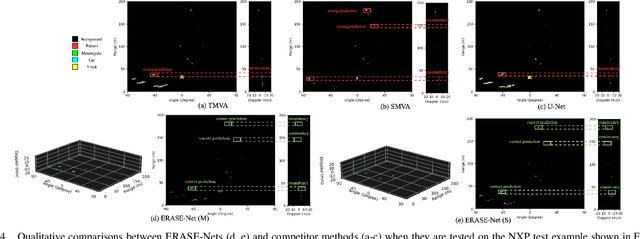
Among various sensors for assisted and autonomous driving systems, automotive radar has been considered as a robust and low-cost solution even in adverse weather or lighting conditions. With the recent development of radar technologies and open-sourced annotated data sets, semantic segmentation with radar signals has become very promising. However, existing methods are either computationally expensive or discard significant amounts of valuable information from raw 3D radar signals by reducing them to 2D planes via averaging. In this work, we introduce ERASE-Net, an Efficient RAdar SEgmentation Network to segment the raw radar signals semantically. The core of our approach is the novel detect-then-segment method for raw radar signals. It first detects the center point of each object, then extracts a compact radar signal representation, and finally performs semantic segmentation. We show that our method can achieve superior performance on radar semantic segmentation task compared to the state-of-the-art (SOTA) technique. Furthermore, our approach requires up to 20x less computational resources. Finally, we show that the proposed ERASE-Net can be compressed by 40% without significant loss in performance, significantly more than the SOTA network, which makes it a more promising candidate for practical automotive applications.
Low-Pass Filtering SGD for Recovering Flat Optima in the Deep Learning Optimization Landscape
Feb 04, 2022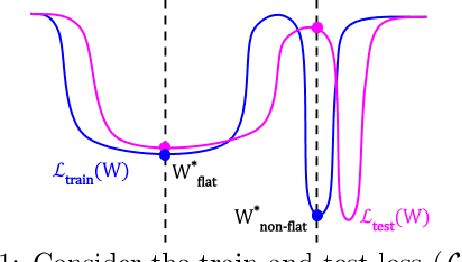
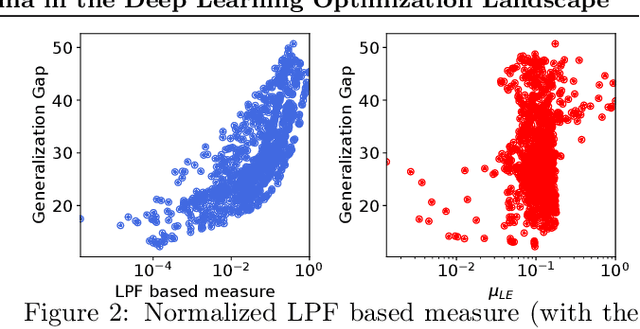
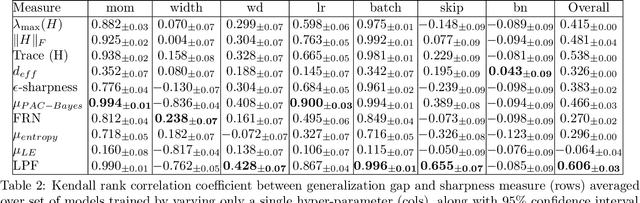
In this paper, we study the sharpness of a deep learning (DL) loss landscape around local minima in order to reveal systematic mechanisms underlying the generalization abilities of DL models. Our analysis is performed across varying network and optimizer hyper-parameters, and involves a rich family of different sharpness measures. We compare these measures and show that the low-pass filter-based measure exhibits the highest correlation with the generalization abilities of DL models, has high robustness to both data and label noise, and furthermore can track the double descent behavior for neural networks. We next derive the optimization algorithm, relying on the low-pass filter (LPF), that actively searches the flat regions in the DL optimization landscape using SGD-like procedure. The update of the proposed algorithm, that we call LPF-SGD, is determined by the gradient of the convolution of the filter kernel with the loss function and can be efficiently computed using MC sampling. We empirically show that our algorithm achieves superior generalization performance compared to the common DL training strategies. On the theoretical front, we prove that LPF-SGD converges to a better optimal point with smaller generalization error than SGD.
A Theoretical-Empirical Approach to Estimating Sample Complexity of DNNs
May 05, 2021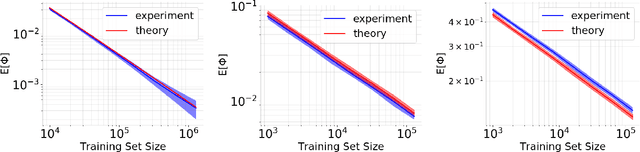
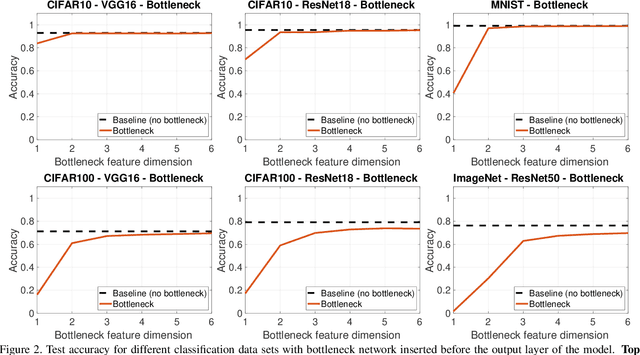

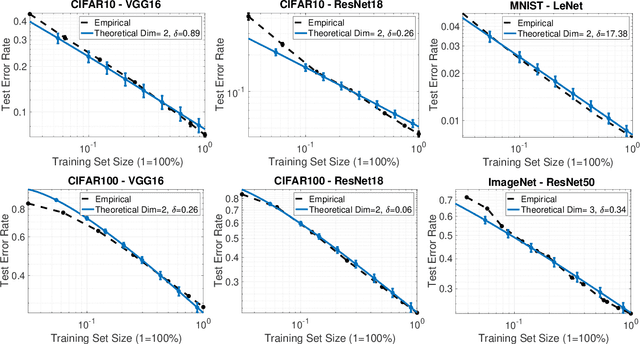
This paper focuses on understanding how the generalization error scales with the amount of the training data for deep neural networks (DNNs). Existing techniques in statistical learning require computation of capacity measures, such as VC dimension, to provably bound this error. It is however unclear how to extend these measures to DNNs and therefore the existing analyses are applicable to simple neural networks, which are not used in practice, e.g., linear or shallow ones or otherwise multi-layer perceptrons. Moreover, many theoretical error bounds are not empirically verifiable. We derive estimates of the generalization error that hold for deep networks and do not rely on unattainable capacity measures. The enabling technique in our approach hinges on two major assumptions: i) the network achieves zero training error, ii) the probability of making an error on a test point is proportional to the distance between this point and its nearest training point in the feature space and at a certain maximal distance (that we call radius) it saturates. Based on these assumptions we estimate the generalization error of DNNs. The obtained estimate scales as O(1/(\delta N^{1/d})), where N is the size of the training data and is parameterized by two quantities, the effective dimensionality of the data as perceived by the network (d) and the aforementioned radius (\delta), both of which we find empirically. We show that our estimates match with the experimentally obtained behavior of the error on multiple learning tasks using benchmark data-sets and realistic models. Estimating training data requirements is essential for deployment of safety critical applications such as autonomous driving etc. Furthermore, collecting and annotating training data requires a huge amount of financial, computational and human resources. Our empirical estimates will help to efficiently allocate resources.
Skin Lesion Segmentation and Classification with Deep Learning System
Feb 16, 2019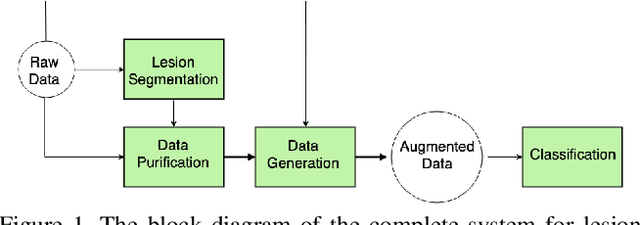

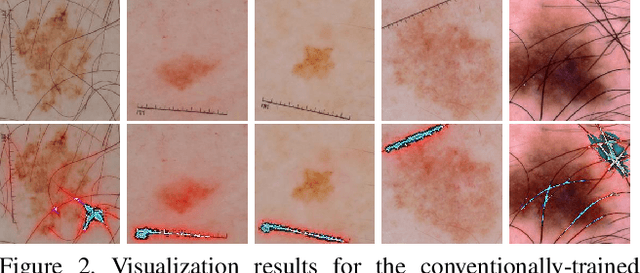
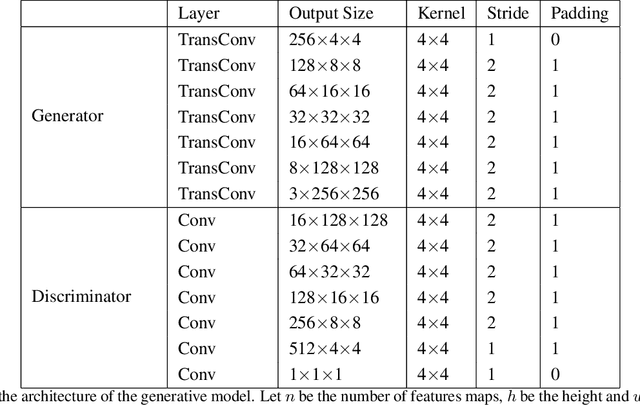
Melanoma is one of the ten most common cancers in the US. Early detection is crucial for survival, but often the cancer is diagnosed in the fatal stage. Deep learning has the potential to improve cancer detection rates, but its applicability to melanoma detection is compromised by the limitations of the available skin lesion databases, which are small, heavily imbalanced, and contain images with occlusions. We propose a complete deep learning system for lesion segmentation and classification that utilizes networks specialized in data purification and augmentation. It contains the processing unit for removing image occlusions and the data generation unit for populating scarce lesion classes, or equivalently creating virtual patients with pre-defined types of lesions. We empirically verify our approach and show superior performance over common baselines.
VisualBackProp for learning using privileged information with CNNs
May 24, 2018
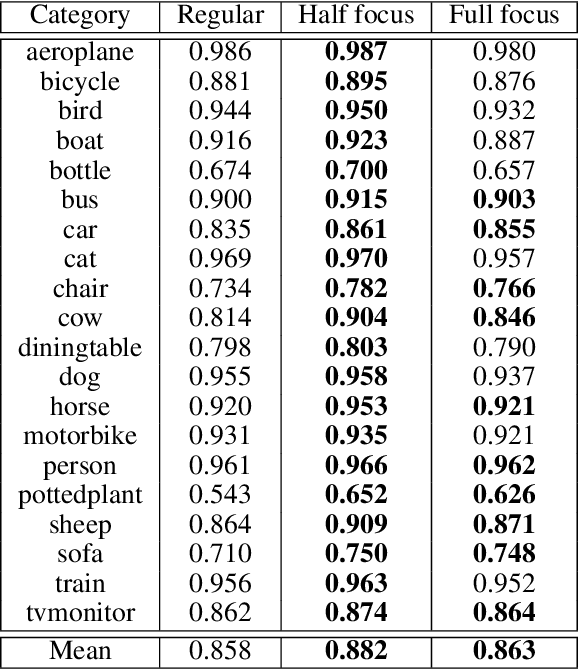


In many machine learning applications, from medical diagnostics to autonomous driving, the availability of prior knowledge can be used to improve the predictive performance of learning algorithms and incorporate `physical,' `domain knowledge,' or `common sense' concepts into training of machine learning systems as well as verify constraints/properties of the systems. We explore the learning using privileged information paradigm and show how to incorporate the privileged information, such as segmentation mask available along with the classification label of each example, into the training stage of convolutional neural networks. This is done by augmenting the CNN model with an architectural component that effectively focuses model's attention on the desired region of the input image during the training process and that is transparent to the network's label prediction mechanism at testing. This component effectively corresponds to the visualization strategy for identifying the parts of the input, often referred to as visualization mask, that most contribute to the prediction, yet uses this strategy in reverse to the classical setting in order to enforce the desired visualization mask instead. We verify our proposed algorithms through exhaustive experiments on benchmark ImageNet and PASCAL VOC data sets and achieve improvements in the performance of $2.4\%$ and $2.7\%$ over standard single-supervision model training. Finally, we confirm the effectiveness of our approach on skin lesion classification problem.