 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical-Empirical Approach to Estimating Sample Complexity of DNNs
May 05, 2021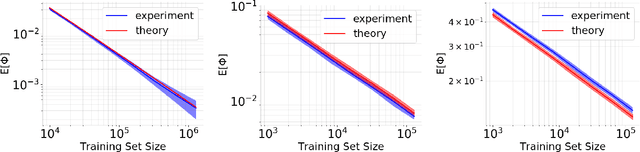
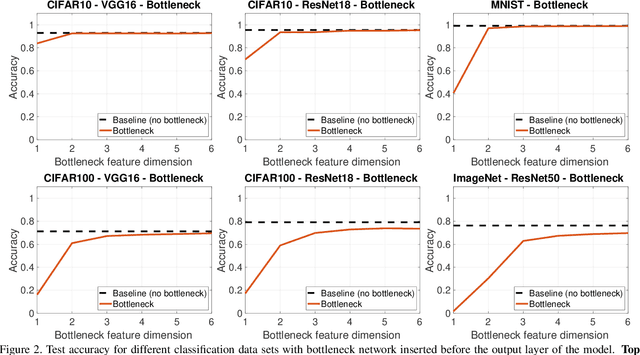

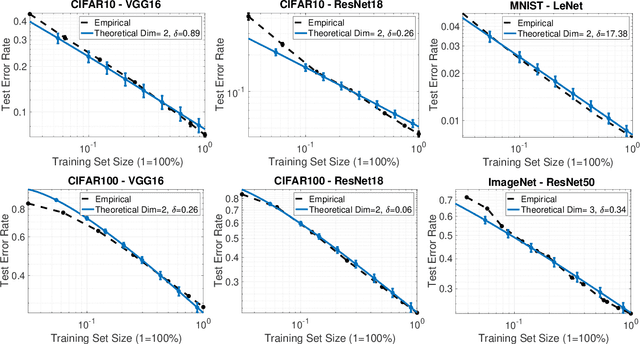
This paper focuses on understanding how the generalization error scales with the amount of the training data for deep neural networks (DNNs). Existing techniques in statistical learning require computation of capacity measures, such as VC dimension, to provably bound this error. It is however unclear how to extend these measures to DNNs and therefore the existing analyses are applicable to simple neural networks, which are not used in practice, e.g., linear or shallow ones or otherwise multi-layer perceptrons. Moreover, many theoretical error bounds are not empirically verifiable. We derive estimates of the generalization error that hold for deep networks and do not rely on unattainable capacity measures. The enabling technique in our approach hinges on two major assumptions: i) the network achieves zero training error, ii) the probability of making an error on a test point is proportional to the distance between this point and its nearest training point in the feature space and at a certain maximal distance (that we call radius) it saturates. Based on these assumptions we estimate the generalization error of DNNs. The obtained estimate scales as O(1/(\delta N^{1/d})), where N is the size of the training data and is parameterized by two quantities, the effective dimensionality of the data as perceived by the network (d) and the aforementioned radius (\delta), both of which we find empirically. We show that our estimates match with the experimentally obtained behavior of the error on multiple learning tasks using benchmark data-sets and realistic models. Estimating training data requirements is essential for deployment of safety critical applications such as autonomous driving etc. Furthermore, collecting and annotating training data requires a huge amount of financial, computational and human resources. Our empirical estimates will help to efficiently allocate resources.
Adversarial Learning-Based On-Line Anomaly Monitoring for Assured Autonomy
Nov 12, 2018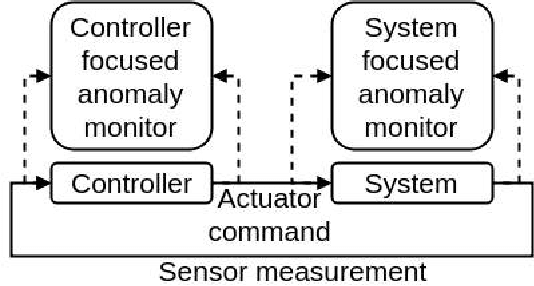
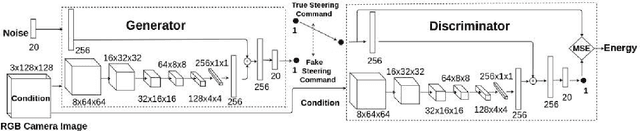
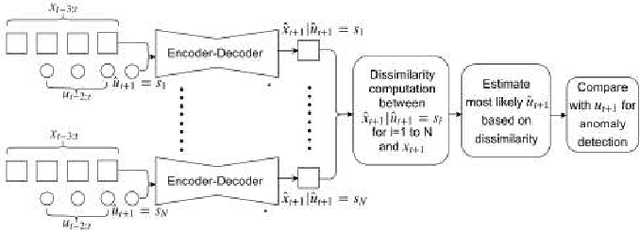
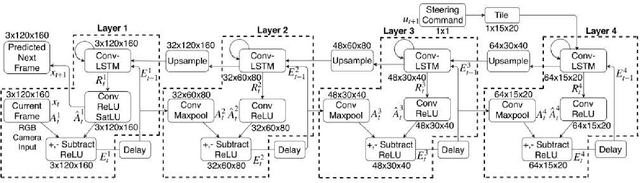
The paper proposes an on-line monitoring framework for continuous real-time safety/security in learning-based control systems (specifically application to a unmanned ground vehicle). We monitor validity of mappings from sensor inputs to actuator commands, controller-focused anomaly detection (CFAM), and from actuator commands to sensor inputs, system-focused anomaly detection (SFAM). CFAM is an image conditioned energy based generative adversarial network (EBGAN) in which the energy based discriminator distinguishes between proper and anomalous actuator commands. SFAM is based on an action condition video prediction framework to detect anomalies between predicted and observed temporal evolution of sensor data. We demonstrate the effectiveness of the approach on our autonomous ground vehicle for indoor environments and on Udacity dataset for outdoor environments.
LSALSA: efficient sparse coding in single and multiple dictionary settings
Feb 13, 2018
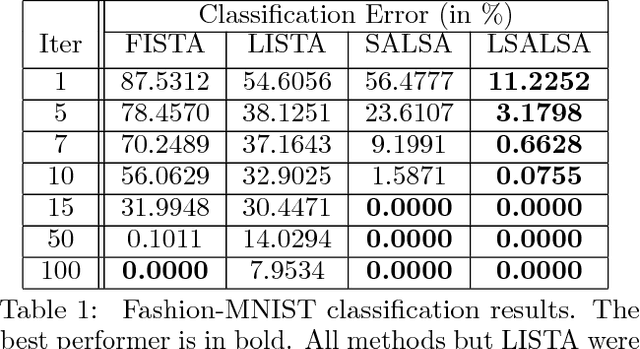
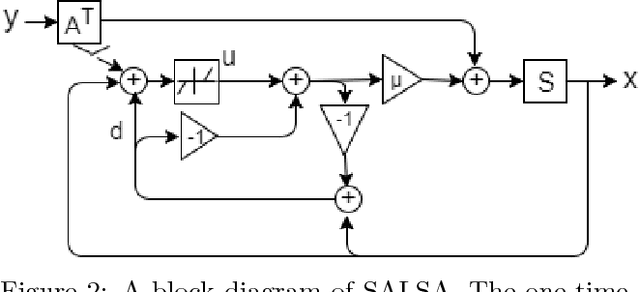
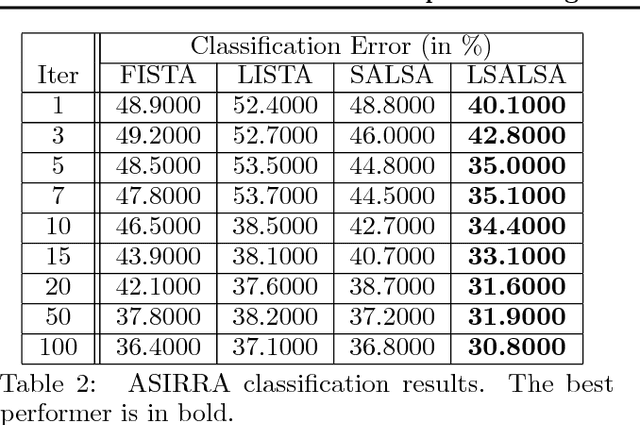
We propose an efficient sparse coding (SC) framework for obtaining sparse representation of data. The proposed framework is very general and applies to both the single dictionary setting, where each data point is represented as a sparse combination of the columns of one dictionary matrix, as well as the multiple dictionary setting as given in morphological component analysis (MCA), where the goal is to separate the data into additive parts such that each part has distinct sparse representation within an appropriately chosen corresponding dictionary. Both tasks have been cast as $\ell_1$-regularized optimization problems of minimizing quadratic reconstruction error. In an effort to accelerate traditional acquisition of sparse codes, we propose a deep learning architecture that constitutes a trainable time-unfolded version of the Split Augmented Lagrangian Shrinkage Algorithm (SALSA), a special case of the alternating direction method of multipliers (ADMM). We empirically validate both variants of the algorithm on image vision tasks and demonstrate that at inference our networks achieve improvements in terms of the running time and the quality of estimated sparse codes on both classic SC and MCA problems over more common baselines. We finally demonstrate the visual advantage of our technique on the task of source separation.