 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapleGrasp: Mask-guided Feature Pooling for Language-driven Efficient Robotic Grasping
Jun 06, 2025Robotic manipulation of unseen objects via natural language commands remains challenging. Language driven robotic grasping (LDRG) predicts stable grasp poses from natural language queries and RGB-D images. Here we introduce Mask-guided feature pooling, a lightweight enhancement to existing LDRG methods. Our approach employs a two-stage training strategy: first, a vision-language model generates feature maps from CLIP-fused embeddings, which are upsampled and weighted by text embeddings to produce segmentation masks. Next, the decoder generates separate feature maps for grasp prediction, pooling only token features within these masked regions to efficiently predict grasp poses. This targeted pooling approach reduces computational complexity, accelerating both training and inference. Incorporating mask pooling results in a 12% improvement over prior approaches on the OCID-VLG benchmark. Furthermore, we introduce RefGraspNet, an open-source dataset eight times larger than existing alternatives, significantly enhancing model generalization for open-vocabulary grasping. By extending 2D grasp predictions to 3D via depth mapping and inverse kinematics, our modular method achieves performance comparable to recent Vision-Language-Action (VLA) models on the LIBERO simulation benchmark, with improved generalization across different task suites. Real-world experiments on a 7 DoF Franka robotic arm demonstrate a 57% success rate with unseen objects, surpassing competitive baselines by 7%. Code will be released post publication.
RAZER: Robust Accelerated Zero-Shot 3D Open-Vocabulary Panoptic Reconstruction with Spatio-Temporal Aggregation
May 21, 2025Mapping and understanding complex 3D environments is fundamental to how autonomous systems perceive and interact with the physical world, requiring both precise geometric reconstruction and rich semantic comprehension. While existing 3D semantic mapping systems excel at reconstructing and identifying predefined object instances, they lack the flexibility to efficiently build semantic maps with open-vocabulary during online operation. Although recent vision-language models have enabled open-vocabulary object recognition in 2D images, they haven't yet bridged the gap to 3D spatial understanding. The critical challenge lies in developing a training-free unified system that can simultaneously construct accurate 3D maps while maintaining semantic consistency and supporting natural language interactions in real time. In this paper, we develop a zero-shot framework that seamlessly integrates GPU-accelerated geometric reconstruction with open-vocabulary vision-language models through online instance-level semantic embedding fusion, guided by hierarchical object association with spatial indexing. Our training-free system achieves superior performance through incremental processing and unified geometric-semantic updates, while robustly handling 2D segmentation inconsistencies. The proposed general-purpose 3D scene understanding framework can be used for various tasks including zero-shot 3D instance retrieval, segmentation, and object detection to reason about previously unseen objects and interpret natural language queries. The project page is available at https://razer-3d.github.io.
OrionNav: Online Planning for Robot Autonomy with Context-Aware LLM and Open-Vocabulary Semantic Scene Graphs
Oct 08, 2024



Enabling robots to autonomously navigate unknown, complex, dynamic environments and perform diverse tasks remains a fundamental challenge in developing robust autonomous physical agents. They must effectively perceive their surroundings while leveraging world knowledge for decision-making. While recent approaches utilize vision-language and large language models for scene understanding and planning, they often rely on offline processing, external computing, or restrictive environmental assumptions. We present a novel framework for efficient and scalable real-time, onboard autonomous navigation that integrates multi-level abstraction in both perception and planning in unknown large-scale environments that change over time. Our system fuses data from multiple onboard sensors for localization and mapping and integrates it with open-vocabulary semantics to generate hierarchical scene graphs. An LLM-based planner leverages these graphs to generate high-level task execution strategies, which guide low-level controllers in safely accomplishing goals. Our framework's real-time operation enables continuous updates to scene graphs and plans, allowing swift responses to environmental changes and on-the-fly error correction. This is a key advantage over static or rule-based planning systems. We demonstrate our system's efficacy on a quadruped robot navigating large-scale, dynamic environments, showcasing its adaptability and robustness in diverse scenarios.
SALSA: Swift Adaptive Lightweight Self-Attention for Enhanced LiDAR Place Recognition
Jul 11, 2024Large-scale LiDAR mappings and localization leverage place recognition techniques to mitigate odometry drifts, ensuring accurate mapping. These techniques utilize scene representations from LiDAR point clouds to identify previously visited sites within a database. Local descriptors, assigned to each point within a point cloud, are aggregated to form a scene representation for the point cloud. These descriptors are also used to re-rank the retrieved point clouds based on geometric fitness scores. We propose SALSA, a novel, lightweight, and efficient framework for LiDAR place recognition. It consists of a Sphereformer backbone that uses radial window attention to enable information aggregation for sparse distant points, an adaptive self-attention layer to pool local descriptors into tokens, and a multi-layer-perceptron Mixer layer for aggregating the tokens to generate a scene descriptor. The proposed framework outperforms existing methods on various LiDAR place recognition datasets in terms of both retrieval and metric localization while operating in real-time.
CLIPScope: Enhancing Zero-Shot OOD Detection with Bayesian Scoring
May 23, 2024
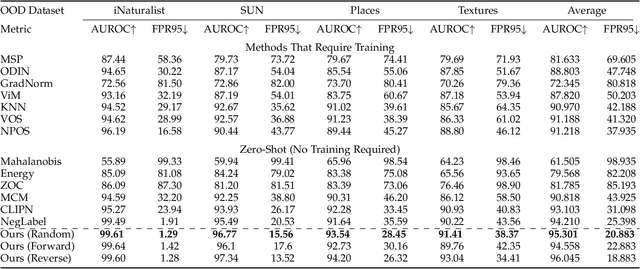


Detection of out-of-distribution (OOD) samples is crucial for safe real-world deployment of machine learning models. Recent advances in vision language foundation models have made them capable of detecting OOD samples without requiring in-distribution (ID) images. However, these zero-shot methods often underperform as they do not adequately consider ID class likelihoods in their detection confidence scoring. Hence, we introduce CLIPScope, a zero-shot OOD detection approach that normalizes the confidence score of a sample by class likelihoods, akin to a Bayesian posterior update. Furthermore, CLIPScope incorporates a novel strategy to mine OOD classes from a large lexical database. It selects class labels that are farthest and nearest to ID classes in terms of CLIP embedding distance to maximize coverage of OOD samples. We conduct extensive ablation studies and empirical evaluations, demonstrating state of the art performance of CLIPScope across various OOD detection benchmarks.
AdaMAE: Adaptive Masking for Efficient Spatiotemporal Learning with Masked Autoencoders
Nov 16, 2022



Masked Autoencoders (MAEs) learn generalizable representations for image, text, audio, video, etc., by reconstructing masked input data from tokens of the visible data. Current MAE approaches for videos rely on random patch, tube, or frame-based masking strategies to select these tokens. This paper proposes AdaMAE, an adaptive masking strategy for MAEs that is end-to-end trainable. Our adaptive masking strategy samples visible tokens based on the semantic context using an auxiliary sampling network. This network estimates a categorical distribution over spacetime-patch tokens. The tokens that increase the expected reconstruction error are rewarded and selected as visible tokens, motivated by the policy gradient algorithm in reinforcement learning. We show that AdaMAE samples more tokens from the high spatiotemporal information regions, thereby allowing us to mask 95% of tokens, resulting in lower memory requirements and faster pre-training. We conduct ablation studies on the Something-Something v2 (SSv2) dataset to demonstrate the efficacy of our adaptive sampling approach and report state-of-the-art results of 70.0% and 81.7% in top-1 accuracy on SSv2 and Kinetics-400 action classification datasets with a ViT-Base backbone and 800 pre-training epochs.
Bait and Switch: Online Training Data Poisoning of Autonomous Driving Systems
Nov 08, 2020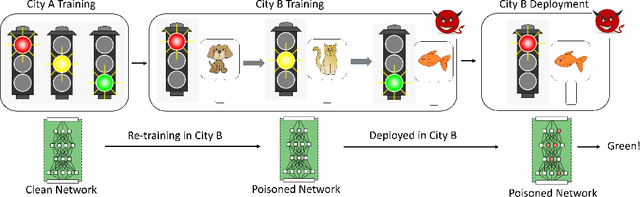
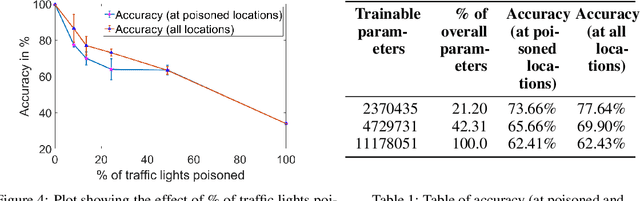


We show that by controlling parts of a physical environment in which a pre-trained deep neural network (DNN) is being fine-tuned online, an adversary can launch subtle data poisoning attacks that degrade the performance of the system. While the attack can be applied in general to any perception task, we consider a DNN based traffic light classifier for an autonomous car that has been trained in one city and is being fine-tuned online in another city. We show that by injecting environmental perturbations that do not modify the traffic lights themselves or ground-truth labels, the adversary can cause the deep network to learn spurious concepts during the online learning phase. The attacker can leverage the introduced spurious concepts in the environment to cause the model's accuracy to degrade during operation; therefore, causing the system to malfunction.
Adversarial Learning-Based On-Line Anomaly Monitoring for Assured Autonomy
Nov 12, 2018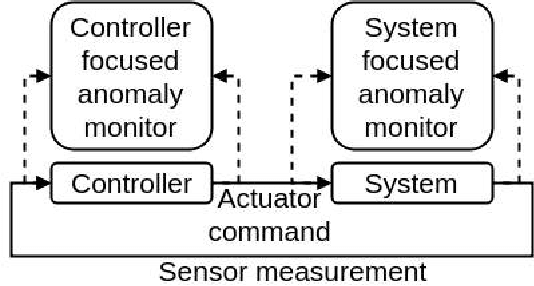
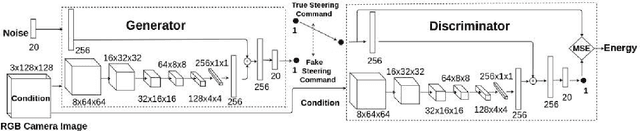
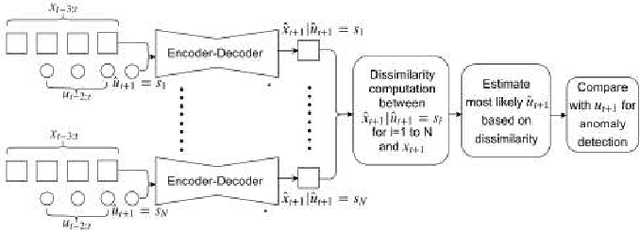
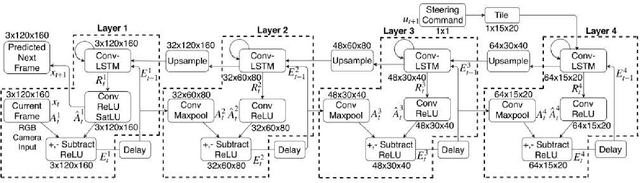
The paper proposes an on-line monitoring framework for continuous real-time safety/security in learning-based control systems (specifically application to a unmanned ground vehicle). We monitor validity of mappings from sensor inputs to actuator commands, controller-focused anomaly detection (CFAM), and from actuator commands to sensor inputs, system-focused anomaly detection (SFAM). CFAM is an image conditioned energy based generative adversarial network (EBGAN) in which the energy based discriminator distinguishes between proper and anomalous actuator commands. SFAM is based on an action condition video prediction framework to detect anomalies between predicted and observed temporal evolution of sensor data. We demonstrate the effectiveness of the approach on our autonomous ground vehicle for indoor environments and on Udacity dataset for outdoor environments.