 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVANDERER: Map-Free Exploration using Future-Aware and Visual-Curiosity-Guided Diffusion Policy
Jun 12, 2026Mobile agents require efficient exploration strategies to map unseen environments and autonomously plan tasks. Traditional methods rely on generating occupancy maps and optimizing the sequence in which unexplored regions are visited. However, in sensor-constrained settings, such as those limited to monocular cameras, generating accurate occupancy maps is challenging. To address this, we propose VANDERER, an exploration framework that leverages a Visual Curiosity Module (VCM) to guide pre-trained diffusion policies using only monocular image data. This curiosity module predicts the outcomes of proposed actions via a navigation world model and evaluates them through a curiosity cost. The cost then guides the diffusion process toward generating actions that maximize exploration. Evaluated across diverse simulated environments, VANDERER consistently outperforms established baselines, exploring an average of 13.4% more area than NoMaD. Our results reveal a direct correlation between visual and geometric curiosity in outdoor environments, demonstrating that VANDERER can effectively leverage this relationship for efficient exploration using sensor-constrained agents.
Unifying Object-Centric World Models and Diffusion Policy: A Hierarchical Framework for Multi-Stage Robotic Tasks
Jun 07, 2026Visual world models have shown great potential in learning complex system dynamics. Recent advancements leverage these models as transition functions within Model Predictive Control (MPC) frameworks to solve various control tasks. When applied to robotics, however, they are limited to single-stage tasks such as reaching or grasping, and struggle with multi-stage ones that demand complex sequential planning. In this work, we introduce WorldDP, a world model framework designed for multi-stage robotic manipulation. Our hierarchical approach utilizes a high-level world model as a transition function to optimize for feasible subgoals during runtime, which are subsequently reached by a low-level Diffusion Policy. To further aid in learning dynamics and planning, we incorporate object-centric representations that decouple environmental entities and enable us to plan sequentially with respect to each. Evaluated across several robotics benchmarks, WorldDP consistently outperforms existing baselines, validating that coupling the world model's physically grounded planning with diffusion policy's efficient execution yields superior multi-stage performance.
World Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
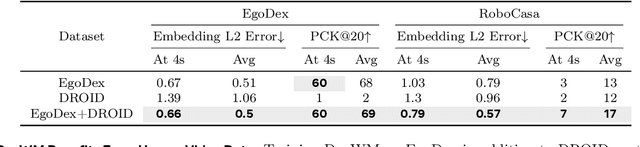
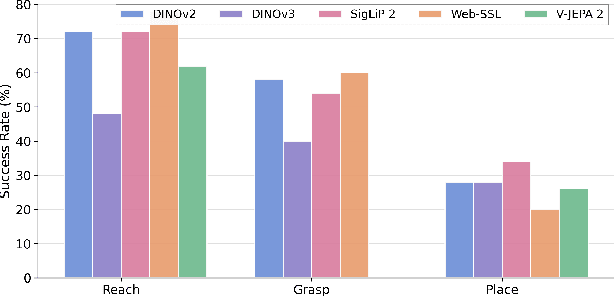
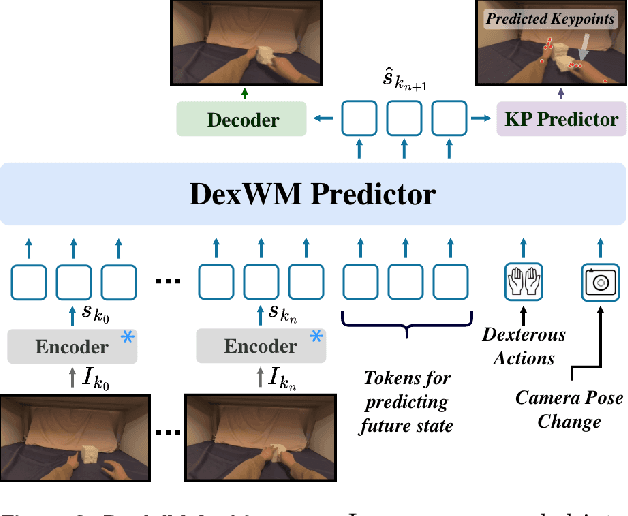
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
OSVI-WM: One-Shot Visual Imitation for Unseen Tasks using World-Model-Guided Trajectory Generation
May 26, 2025Visual imitation learning enables robotic agents to acquire skills by observing expert demonstration videos. In the one-shot setting, the agent generates a policy after observing a single expert demonstration without additional fine-tuning. Existing approaches typically train and evaluate on the same set of tasks, varying only object configurations, and struggle to generalize to unseen tasks with different semantic or structural requirements. While some recent methods attempt to address this, they exhibit low success rates on hard test tasks that, despite being visually similar to some training tasks, differ in context and require distinct responses. Additionally, most existing methods lack an explicit model of environment dynamics, limiting their ability to reason about future states. To address these limitations, we propose a novel framework for one-shot visual imitation learning via world-model-guided trajectory generation. Given an expert demonstration video and the agent's initial observation, our method leverages a learned world model to predict a sequence of latent states and actions. This latent trajectory is then decoded into physical waypoints that guide the agent's execution. Our method is evaluated on two simulated benchmarks and three real-world robotic platforms, where it consistently outperforms prior approaches, with over 30% improvement in some cases.
RoboPEPP: Vision-Based Robot Pose and Joint Angle Estimation through Embedding Predictive Pre-Training
Nov 26, 2024



Vision-based pose estimation of articulated robots with unknown joint angles has applications in collaborative robotics and human-robot interaction tasks. Current frameworks use neural network encoders to extract image features and downstream layers to predict joint angles and robot pose. While images of robots inherently contain rich information about the robot's physical structures, existing methods often fail to leverage it fully; therefore, limiting performance under occlusions and truncations. To address this, we introduce RoboPEPP, a method that fuses information about the robot's physical model into the encoder using a masking-based self-supervised embedding-predictive architecture. Specifically, we mask the robot's joints and pre-train an encoder-predictor model to infer the joints' embeddings from surrounding unmasked regions, enhancing the encoder's understanding of the robot's physical model. The pre-trained encoder-predictor pair, along with joint angle and keypoint prediction networks, is then fine-tuned for pose and joint angle estimation. Random masking of input during fine-tuning and keypoint filtering during evaluation further improves robustness. Our method, evaluated on several datasets, achieves the best results in robot pose and joint angle estimation while being the least sensitive to occlusions and requiring the lowest execution time.
OrionNav: Online Planning for Robot Autonomy with Context-Aware LLM and Open-Vocabulary Semantic Scene Graphs
Oct 08, 2024



Enabling robots to autonomously navigate unknown, complex, dynamic environments and perform diverse tasks remains a fundamental challenge in developing robust autonomous physical agents. They must effectively perceive their surroundings while leveraging world knowledge for decision-making. While recent approaches utilize vision-language and large language models for scene understanding and planning, they often rely on offline processing, external computing, or restrictive environmental assumptions. We present a novel framework for efficient and scalable real-time, onboard autonomous navigation that integrates multi-level abstraction in both perception and planning in unknown large-scale environments that change over time. Our system fuses data from multiple onboard sensors for localization and mapping and integrates it with open-vocabulary semantics to generate hierarchical scene graphs. An LLM-based planner leverages these graphs to generate high-level task execution strategies, which guide low-level controllers in safely accomplishing goals. Our framework's real-time operation enables continuous updates to scene graphs and plans, allowing swift responses to environmental changes and on-the-fly error correction. This is a key advantage over static or rule-based planning systems. We demonstrate our system's efficacy on a quadruped robot navigating large-scale, dynamic environments, showcasing its adaptability and robustness in diverse scenarios.
SALSA: Swift Adaptive Lightweight Self-Attention for Enhanced LiDAR Place Recognition
Jul 11, 2024Large-scale LiDAR mappings and localization leverage place recognition techniques to mitigate odometry drifts, ensuring accurate mapping. These techniques utilize scene representations from LiDAR point clouds to identify previously visited sites within a database. Local descriptors, assigned to each point within a point cloud, are aggregated to form a scene representation for the point cloud. These descriptors are also used to re-rank the retrieved point clouds based on geometric fitness scores. We propose SALSA, a novel, lightweight, and efficient framework for LiDAR place recognition. It consists of a Sphereformer backbone that uses radial window attention to enable information aggregation for sparse distant points, an adaptive self-attention layer to pool local descriptors into tokens, and a multi-layer-perceptron Mixer layer for aggregating the tokens to generate a scene descriptor. The proposed framework outperforms existing methods on various LiDAR place recognition datasets in terms of both retrieval and metric localization while operating in real-time.
Phase Aware Speech Enhancement using Realisation of Complex-valued LSTM
Oct 27, 2020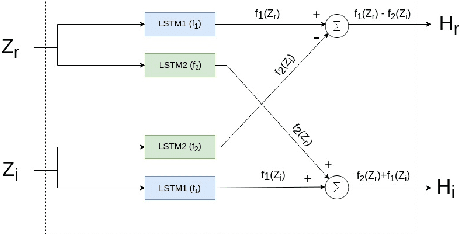

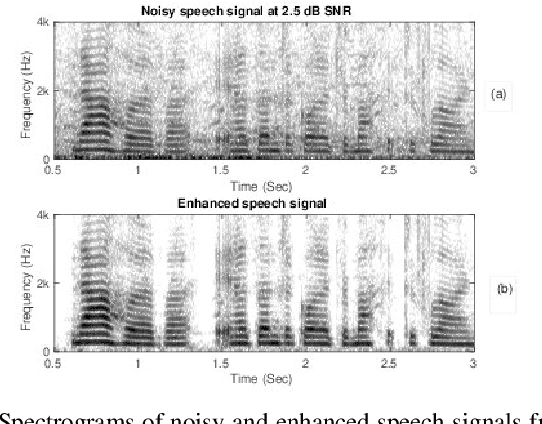
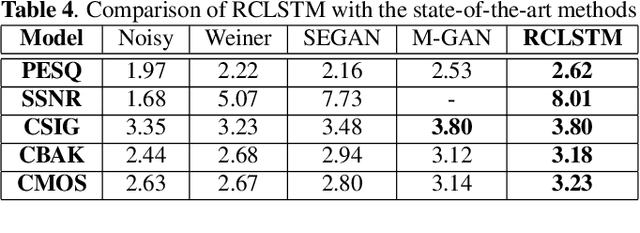
Most of the deep learning based speech enhancement (SE) methods rely on estimating the magnitude spectrum of the clean speech signal from the observed noisy speech signal, either by magnitude spectral masking or regression. These methods reuse the noisy phase while synthesizing the time-domain waveform from the estimated magnitude spectrum. However, there have been recent works highlighting the importance of phase in SE. There was an attempt to estimate the complex ratio mask taking phase into account using complex-valued feed-forward neural network (FFNN). But FFNNs cannot capture the sequential information essential for phase estimation. In this work, we propose a realisation of complex-valued long short-term memory (RCLSTM) network to estimate the complex ratio mask (CRM) using sequential information along time. The proposed RCLSTM is designed to process the complex-valued sequences using complex arithmetic, and hence it preserves the dependencies between the real and imaginary parts of CRM and thereby the phase. The proposed method is evaluated on the noisy speech mixtures formed from the Voice-Bank corpus and DEMAND database. When compared to real value based masking methods, the proposed RCLSTM improves over them in several objective measures including perceptual evaluation of speech quality (PESQ), in which it improves by over 4.3%