 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupled Local and Global World Models for Efficient First Order RL
Feb 05, 2026World models offer a promising avenue for more faithfully capturing complex dynamics, including contacts and non-rigidity, as well as complex sensory information, such as visual perception, in situations where standard simulators struggle. However, these models are computationally complex to evaluate, posing a challenge for popular RL approaches that have been successfully used with simulators to solve complex locomotion tasks but yet struggle with manipulation. This paper introduces a method that bypasses simulators entirely, training RL policies inside world models learned from robots' interactions with real environments. At its core, our approach enables policy training with large-scale diffusion models via a novel decoupled first-order gradient (FoG) method: a full-scale world model generates accurate forward trajectories, while a lightweight latent-space surrogate approximates its local dynamics for efficient gradient computation. This coupling of a local and global world model ensures high-fidelity unrolling alongside computationally tractable differentiation. We demonstrate the efficacy of our method on the Push-T manipulation task, where it significantly outperforms PPO in sample efficiency. We further evaluate our approach through an ego-centric object manipulation task with a quadruped. Together, these results demonstrate that learning inside data-driven world models is a promising pathway for solving hard-to-model RL tasks in image space without reliance on hand-crafted physics simulators.
OrionNav: Online Planning for Robot Autonomy with Context-Aware LLM and Open-Vocabulary Semantic Scene Graphs
Oct 08, 2024



Enabling robots to autonomously navigate unknown, complex, dynamic environments and perform diverse tasks remains a fundamental challenge in developing robust autonomous physical agents. They must effectively perceive their surroundings while leveraging world knowledge for decision-making. While recent approaches utilize vision-language and large language models for scene understanding and planning, they often rely on offline processing, external computing, or restrictive environmental assumptions. We present a novel framework for efficient and scalable real-time, onboard autonomous navigation that integrates multi-level abstraction in both perception and planning in unknown large-scale environments that change over time. Our system fuses data from multiple onboard sensors for localization and mapping and integrates it with open-vocabulary semantics to generate hierarchical scene graphs. An LLM-based planner leverages these graphs to generate high-level task execution strategies, which guide low-level controllers in safely accomplishing goals. Our framework's real-time operation enables continuous updates to scene graphs and plans, allowing swift responses to environmental changes and on-the-fly error correction. This is a key advantage over static or rule-based planning systems. We demonstrate our system's efficacy on a quadruped robot navigating large-scale, dynamic environments, showcasing its adaptability and robustness in diverse scenarios.
Sailing Through Point Clouds: Safe Navigation Using Point Cloud Based Control Barrier Functions
Mar 27, 2024



The capability to navigate safely in an unstructured environment is crucial when deploying robotic systems in real-world scenarios. Recently, control barrier function (CBF) based approaches have been highly effective in synthesizing safety-critical controllers. In this work, we propose a novel CBF-based local planner comprised of two components: Vessel and Mariner. The Vessel is a novel scaling factor based CBF formulation that synthesizes CBFs using only point cloud data. The Mariner is a CBF-based preview control framework that is used to mitigate getting stuck in spurious equilibria during navigation. To demonstrate the efficacy of our proposed approach, we first compare the proposed point cloud based CBF formulation with other point cloud based CBF formulations. Then, we demonstrate the performance of our proposed approach and its integration with global planners using experimental studies on the Unitree B1 and Unitree Go2 quadruped robots in various environments.
Differentiable Optimization Based Time-Varying Control Barrier Functions for Dynamic Obstacle Avoidance
Sep 29, 2023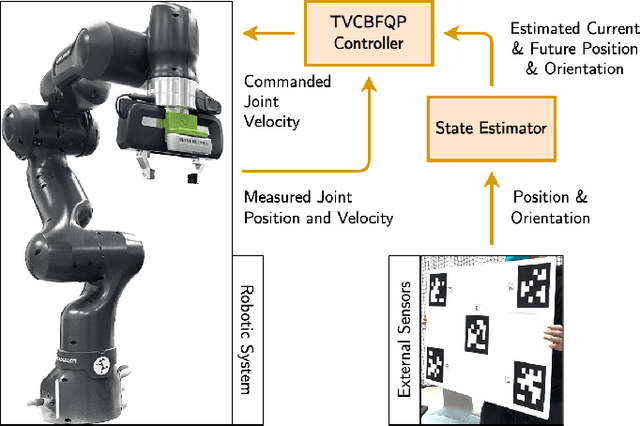

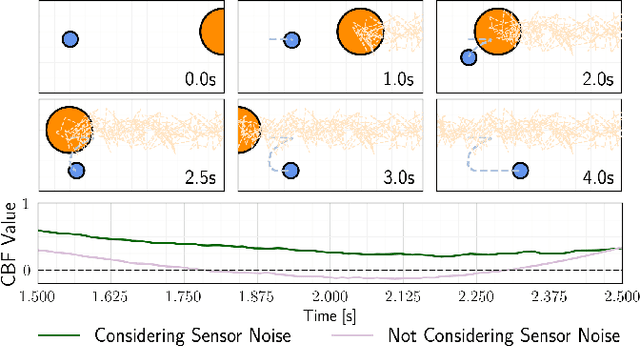
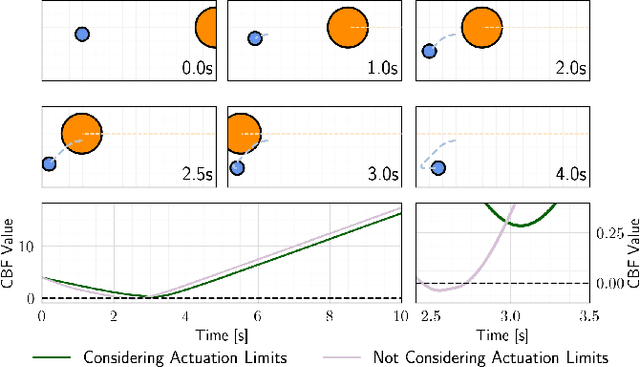
Control barrier functions (CBFs) provide a simple yet effective way for safe control synthesis. Recently, work has been done using differentiable optimization based methods to systematically construct CBFs for static obstacle avoidance tasks between geometric shapes. In this work, we extend the application of differentiable optimization based CBFs to perform dynamic obstacle avoidance tasks. We show that by using the time-varying CBF (TVCBF) formulation, we can perform obstacle avoidance for dynamic geometric obstacles. Additionally, we show how to alter the TVCBF constraint to consider measurement noise and actuation limits. To demonstrate the efficacy of our proposed approach, we first compare its performance with a model predictive control based method on a simulated dynamic obstacle avoidance task with non-ellipsoidal obstacles. Then, we demonstrate the performance of our proposed approach in experimental studies using a 7-degree-of-freedom Franka Research 3 robotic manipulator.
Safe Navigation and Obstacle Avoidance Using Differentiable Optimization Based Control Barrier Functions
Apr 17, 2023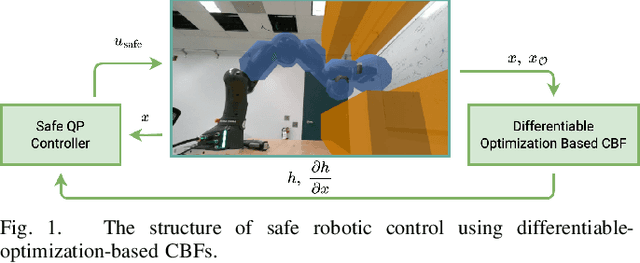

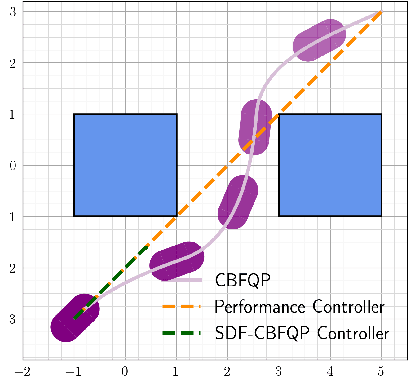

Control barrier functions (CBFs) have been widely applied to safety-critical robotic applications. However, the construction of control barrier functions for robotic systems remains a challenging task. Recently, collision detection using differentiable optimization has provided a way to compute the minimum uniform scaling factor that results in an intersection between two convex shapes and to also compute the Jacobian of the scaling factor. In this paper, we propose a framework that uses this scaling factor, with an offset, to systematically define a CBF for obstacle avoidance tasks. We provide a theoretical analysis that proves the continuity of the proposed CBF. Empirically, we show that the proposed CBF is continuously differentiable, and the resulting optimal control problem is computationally efficient, which makes it applicable for real-time robotic control. We validate our approach, first using a 2D mobile robot example, then on the Franka-Emika Research~3 (FR3) robot manipulator both in simulation and experiment.
A Consistency-Based Loss for Deep Odometry Through Uncertainty Propagation
Jul 01, 2021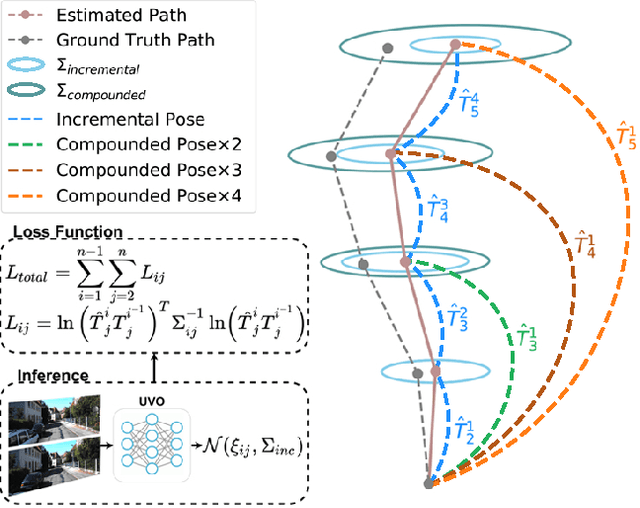
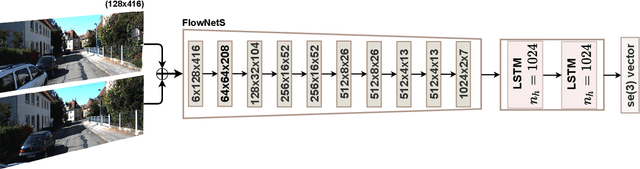
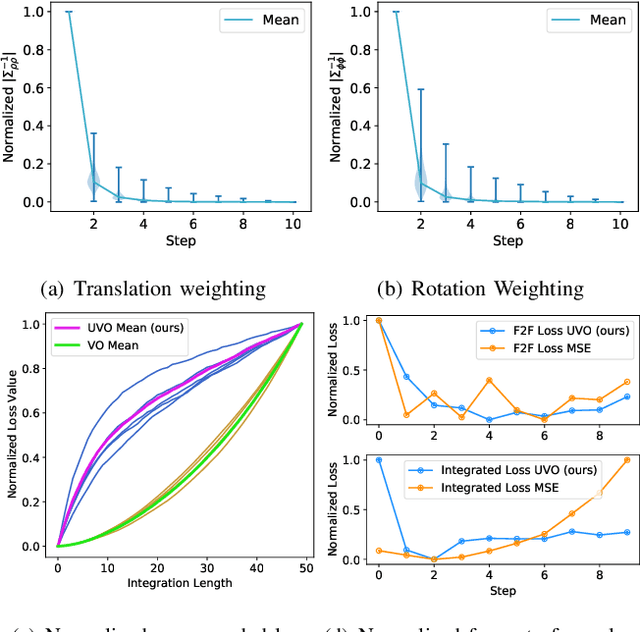
The incremental poses computed through odometry can be integrated over time to calculate the pose of a device with respect to an initial location. The resulting global pose may be used to formulate a second, consistency based, loss term in a deep odometry setting. In such cases where multiple losses are imposed on a network, the uncertainty over each output can be derived to weigh the different loss terms in a maximum likelihood setting. However, when imposing a constraint on the integrated transformation, due to how only odometry is estimated at each iteration of the algorithm, there is no information about the uncertainty associated with the global pose to weigh the global loss term. In this paper, we associate uncertainties with the output poses of a deep odometry network and propagate the uncertainties through each iteration. Our goal is to use the estimated covariance matrix at each incremental step to weigh the loss at the corresponding step while weighting the global loss term using the compounded uncertainty. This formulation provides an adaptive method to weigh the incremental and integrated loss terms against each other, noting the increase in uncertainty as new estimates arrive. We provide quantitative and qualitative analysis of pose estimates and show that our method surpasses the accuracy of the state-of-the-art Visual Odometry approaches. Then, uncertainty estimates are evaluated and comparisons against fixed baselines are provided. Finally, the uncertainty values are used in a realistic example to show the effectiveness of uncertainty quantification for localization.
Deep Inertial Odometry with Accurate IMU Preintegration
Jan 18, 2021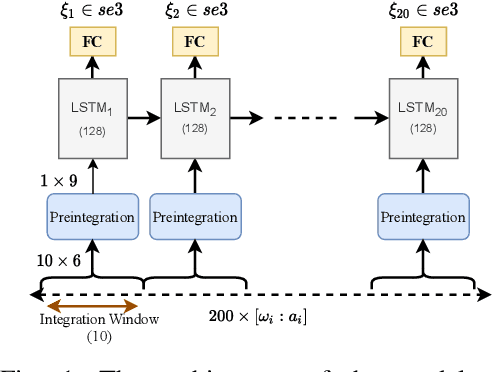
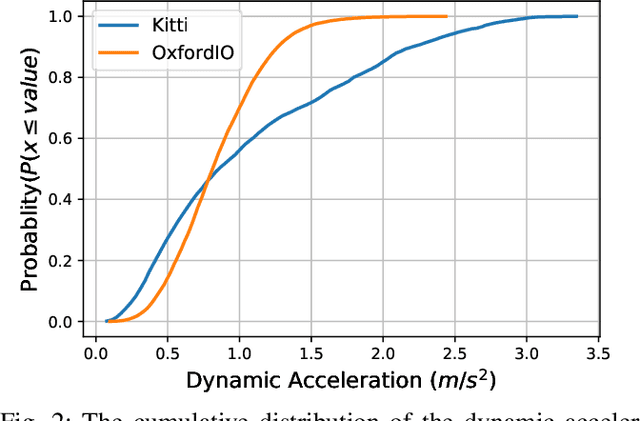
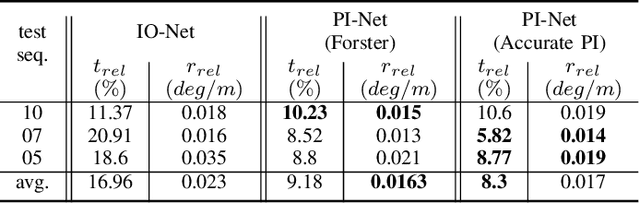
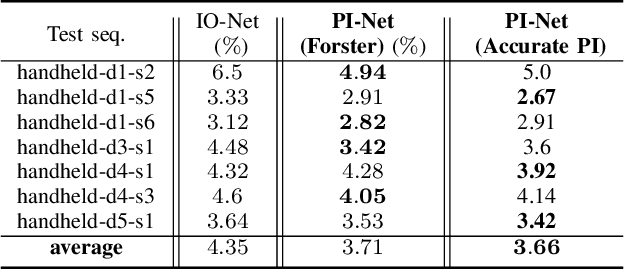
Inertial Measurement Units (IMUs) are interceptive modalities that provide ego-motion measurements independent of the environmental factors. They are widely adopted in various autonomous systems. Motivated by the limitations in processing the noisy measurements from these sensors using their mathematical models, researchers have recently proposed various deep learning architectures to estimate inertial odometry in an end-to-end manner. Nevertheless, the high-frequency and redundant measurements from IMUs lead to long raw sequences to be processed. In this study, we aim to investigate the efficacy of accurate preintegration as a more realistic solution to the IMU motion model for deep inertial odometry (DIO) and the resultant DIO is a fusion of model-driven and data-driven approaches. The accurate IMU preintegration has the potential to outperform numerical approximation of the continuous IMU model used in the existing DIOs. Experimental results validate the proposed DIO.
Exploring Self-Attention for Visual Odometry
Nov 17, 2020
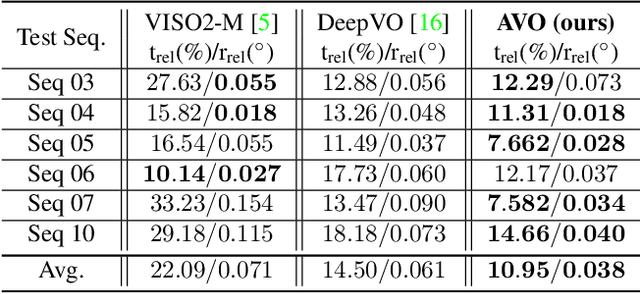
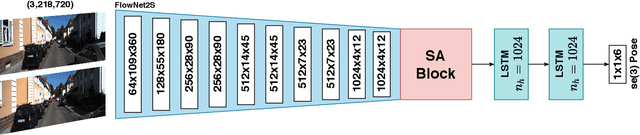
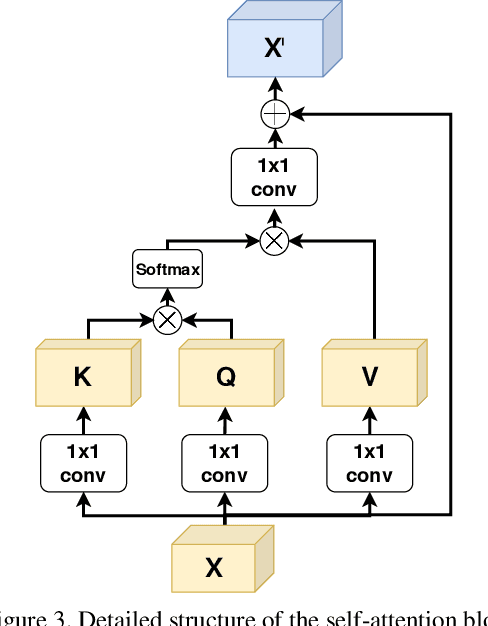
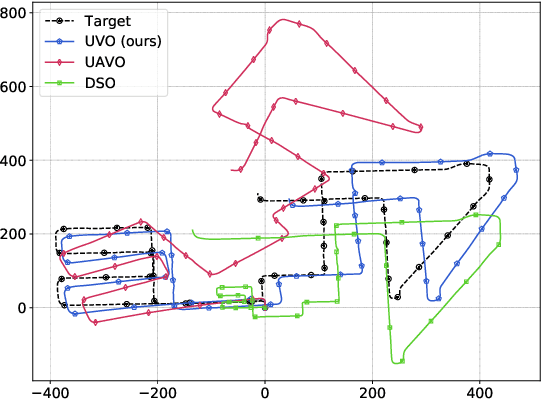
Visual odometry networks commonly use pretrained optical flow networks in order to derive the ego-motion between consecutive frames. The features extracted by these networks represent the motion of all the pixels between frames. However, due to the existence of dynamic objects and texture-less surfaces in the scene, the motion information for every image region might not be reliable for inferring odometry due to the ineffectiveness of dynamic objects in derivation of the incremental changes in position. Recent works in this area lack attention mechanisms in their structures to facilitate dynamic reweighing of the feature maps for extracting more refined egomotion information. In this paper, we explore the effectiveness of self-attention in visual odometry. We report qualitative and quantitative results against the SOTA methods. Furthermore, saliency-based studies alongside specially designed experiments are utilized to investigate the effect of self-attention on VO. Our experiments show that using self-attention allows for the extraction of better features while achieving a better odometry performance compared to networks that lack such structures.
ARC-Net: Activity Recognition Through Capsules
Jul 06, 2020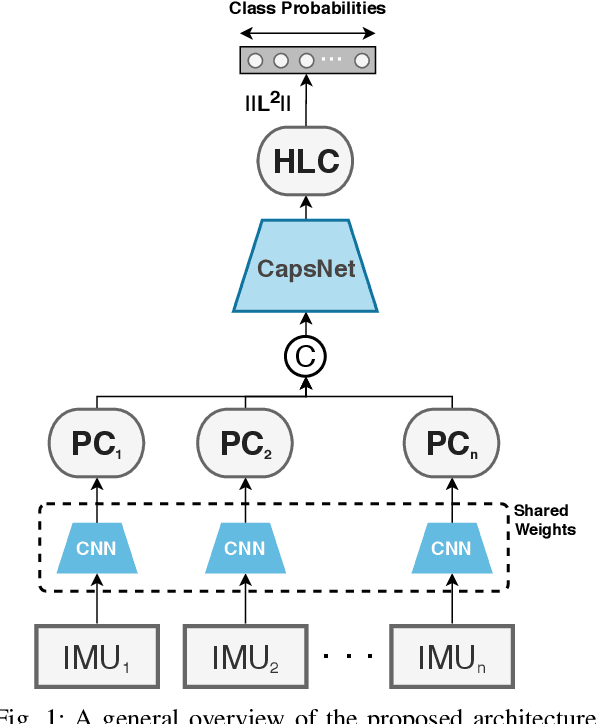

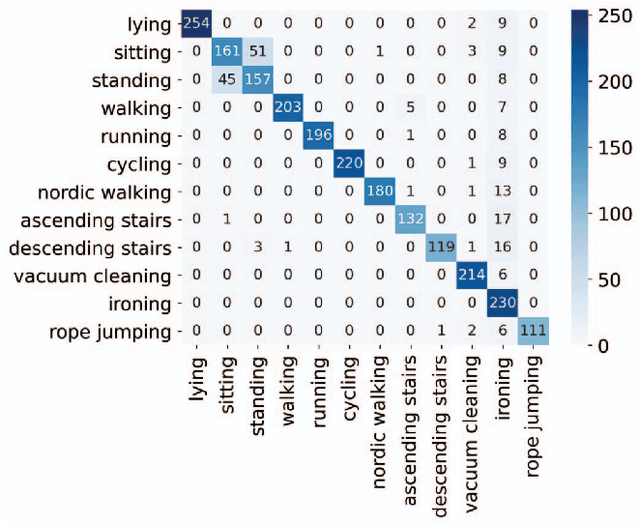
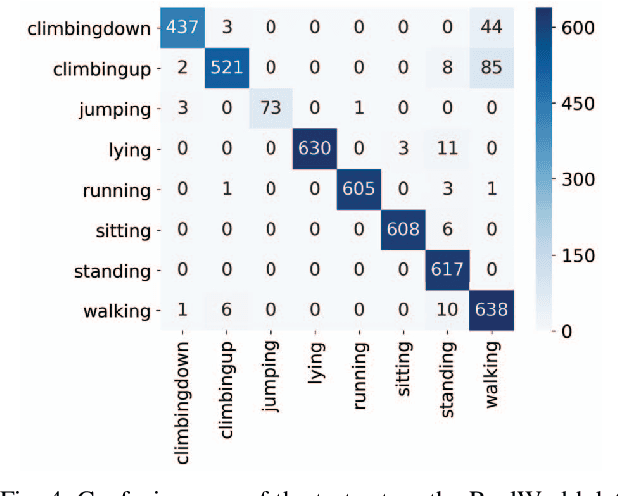
Human Activity Recognition (HAR) is a challenging problem that needs advanced solutions than using handcrafted features to achieve a desirable performance. Deep learning has been proposed as a solution to obtain more accurate HAR systems being robust against noise. In this paper, we introduce ARC-Net and propose the utilization of capsules to fuse the information from multiple inertial measurement units (IMUs) to predict the activity performed by the subject. We hypothesize that this network will be able to tune out the unnecessary information and will be able to make more accurate decisions through the iterative mechanism embedded in capsule networks. We provide heatmaps of the priors, learned by the network, to visualize the utilization of each of the data sources by the trained network. By using the proposed network, we were able to increase the accuracy of the state-of-the-art approaches by 2%. Furthermore, we investigate the directionality of the confusion matrices of our results and discuss the specificity of the activities based on the provided data.