 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Natural Language Scene Understanding for Autonomous Driving: An Extended Dataset and a New Model for Traffic Scene Description Generation
Jan 20, 2026Traffic scene understanding is essential for enabling autonomous vehicles to accurately perceive and interpret their environment, thereby ensuring safe navigation. This paper presents a novel framework that transforms a single frontal-view camera image into a concise natural language description, effectively capturing spatial layouts, semantic relationships, and driving-relevant cues. The proposed model leverages a hybrid attention mechanism to enhance spatial and semantic feature extraction and integrates these features to generate contextually rich and detailed scene descriptions. To address the limited availability of specialized datasets in this domain, a new dataset derived from the BDD100K dataset has been developed, with comprehensive guidelines provided for its construction. Furthermore, the study offers an in-depth discussion of relevant evaluation metrics, identifying the most appropriate measures for this task. Extensive quantitative evaluations using metrics such as CIDEr and SPICE, complemented by human judgment assessments, demonstrate that the proposed model achieves strong performance and effectively fulfills its intended objectives on the newly developed dataset.
MedFedPure: A Medical Federated Framework with MAE-based Detection and Diffusion Purification for Inference-Time Attacks
Nov 07, 2025Artificial intelligence (AI) has shown great potential in medical imaging, particularly for brain tumor detection using Magnetic Resonance Imaging (MRI). However, the models remain vulnerable at inference time when they are trained collaboratively through Federated Learning (FL), an approach adopted to protect patient privacy. Adversarial attacks can subtly alter medical scans in ways invisible to the human eye yet powerful enough to mislead AI models, potentially causing serious misdiagnoses. Existing defenses often assume centralized data and struggle to cope with the decentralized and diverse nature of federated medical settings. In this work, we present MedFedPure, a personalized federated learning defense framework designed to protect diagnostic AI models at inference time without compromising privacy or accuracy. MedFedPure combines three key elements: (1) a personalized FL model that adapts to the unique data distribution of each institution; (2) a Masked Autoencoder (MAE) that detects suspicious inputs by exposing hidden perturbations; and (3) an adaptive diffusion-based purification module that selectively cleans only the flagged scans before classification. Together, these steps offer robust protection while preserving the integrity of normal, benign images. We evaluated MedFedPure on the Br35H brain MRI dataset. The results show a significant gain in adversarial robustness, improving performance from 49.50% to 87.33% under strong attacks, while maintaining a high clean accuracy of 97.67%. By operating locally and in real time during diagnosis, our framework provides a practical path to deploying secure, trustworthy, and privacy-preserving AI tools in clinical workflows. Index Terms: cancer, tumor detection, federated learning, masked autoencoder, diffusion, privacy
Vision Transformer for Intracranial Hemorrhage Classification in CT Scans Using an Entropy-Aware Fuzzy Integral Strategy for Adaptive Scan-Level Decision Fusion
Mar 11, 2025Intracranial hemorrhage (ICH) is a critical medical emergency caused by the rupture of cerebral blood vessels, leading to internal bleeding within the skull. Accurate and timely classification of hemorrhage subtypes is essential for effective clinical decision-making. To address this challenge, we propose an advanced pyramid vision transformer (PVT)-based model, leveraging its hierarchical attention mechanisms to capture both local and global spatial dependencies in brain CT scans. Instead of processing all extracted features indiscriminately, A SHAP-based feature selection method is employed to identify the most discriminative components, which are then used as a latent feature space to train a boosting neural network, reducing computational complexity. We introduce an entropy-aware aggregation strategy along with a fuzzy integral operator to fuse information across multiple CT slices, ensuring a more comprehensive and reliable scan-level diagnosis by accounting for inter-slice dependencies. Experimental results show that our PVT-based framework significantly outperforms state-of-the-art deep learning architectures in terms of classification accuracy, precision, and robustness. By combining SHAP-driven feature selection, transformer-based modeling, and an entropy-aware fuzzy integral operator for decision fusion, our method offers a scalable and computationally efficient AI-driven solution for automated ICH subtype classification.
An Optimal Cascade Feature-Level Spatiotemporal Fusion Strategy for Anomaly Detection in CAN Bus
Jan 31, 2025



Autonomous vehicles represent a revolutionary advancement driven by the integration of artificial intelligence within intelligent transportation systems. However, they remain vulnerable due to the absence of robust security mechanisms in the Controller Area Network (CAN) bus. In order to mitigate the security issue, many machine learning models and strategies have been proposed, which primarily focus on a subset of dominant patterns of anomalies and lack rigorous evaluation in terms of reliability and robustness. Therefore, to address the limitations of previous works and mitigate the security vulnerability in CAN bus, the current study develops a model based on the intrinsic nature of the problem to cover all dominant patterns of anomalies. To achieve this, a cascade feature-level fusion strategy optimized by a two-parameter genetic algorithm is proposed to combine temporal and spatial information. Subsequently, the model is evaluated using a paired t-test to ensure reliability and robustness. Finally, a comprehensive comparative analysis conducted on two widely used datasets advocates that the proposed model outperforms other models and achieves superior accuracy and F1-score, demonstrating the best performance among all models presented to date.
Enhancing Precision of Automated Teller Machines Network Quality Assessment: Machine Learning and Multi Classifier Fusion Approaches
Jan 02, 2025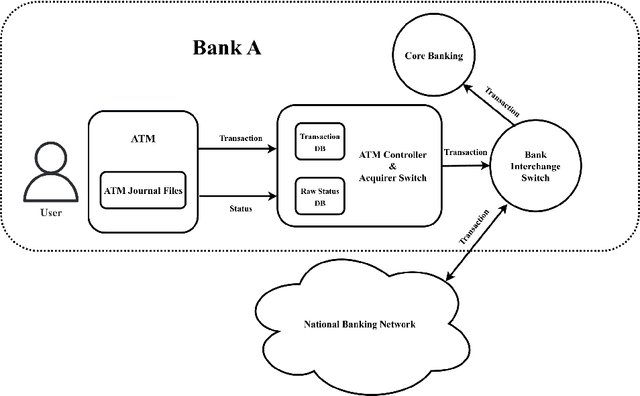



Ensuring reliable ATM services is essential for modern banking, directly impacting customer satisfaction and the operational efficiency of financial institutions. This study introduces a data fusion approach that utilizes multi-classifier fusion techniques, with a special focus on the Stacking Classifier, to enhance the reliability of ATM networks. To address class imbalance, the Synthetic Minority Over-sampling Technique (SMOTE) was applied, enabling balanced learning for both frequent and rare events. The proposed framework integrates diverse classification models - Random Forest, LightGBM, and CatBoost - within a Stacking Classifier, achieving a dramatic reduction in false alarms from 3.56 percent to just 0.71 percent, along with an outstanding overall accuracy of 99.29 percent. This multi-classifier fusion method synthesizes the strengths of individual models, leading to significant cost savings and improved operational decision-making. By demonstrating the power of machine learning and data fusion in optimizing ATM status detection, this research provides practical and scalable solutions for financial institutions aiming to enhance their ATM network performance and customer satisfaction.
AI-Powered Intracranial Hemorrhage Detection: A Co-Scale Convolutional Attention Model with Uncertainty-Based Fuzzy Integral Operator and Feature Screening
Dec 19, 2024



Intracranial hemorrhage (ICH) refers to the leakage or accumulation of blood within the skull, which occurs due to the rupture of blood vessels in or around the brain. If this condition is not diagnosed in a timely manner and appropriately treated, it can lead to serious complications such as decreased consciousness, permanent neurological disabilities, or even death.The primary aim of this study is to detect the occurrence or non-occurrence of ICH, followed by determining the type of subdural hemorrhage (SDH). These tasks are framed as two separate binary classification problems. By adding two layers to the co-scale convolutional attention (CCA) classifier architecture, we introduce a novel approach for ICH detection. In the first layer, after extracting features from different slices of computed tomography (CT) scan images, we combine these features and select the 50 components that capture the highest variance in the data, considering them as informative features. We then assess the discriminative power of these features using the bootstrap forest algorithm, discarding those that lack sufficient discriminative ability between different classes. This algorithm explicitly determines the contribution of each feature to the final prediction, assisting us in developing an explainable AI model. The features feed into a boosting neural network as a latent feature space. In the second layer, we introduce a novel uncertainty-based fuzzy integral operator to fuse information from different CT scan slices. This operator, by accounting for the dependencies between consecutive slices, significantly improves detection accuracy.
AI-Driven Non-Invasive Detection and Staging of Steatosis in Fatty Liver Disease Using a Novel Cascade Model and Information Fusion Techniques
Dec 06, 2024



Non-alcoholic fatty liver disease (NAFLD) is one of the most widespread liver disorders on a global scale, posing a significant threat of progressing to more severe conditions like nonalcoholic steatohepatitis (NASH), liver fibrosis, cirrhosis, and hepatocellular carcinoma. Diagnosing and staging NAFLD presents challenges due to its non-specific symptoms and the invasive nature of liver biopsies. Our research introduces a novel artificial intelligence cascade model employing ensemble learning and feature fusion techniques. We developed a non-invasive, robust, and reliable diagnostic artificial intelligence tool that utilizes anthropometric and laboratory parameters, facilitating early detection and intervention in NAFLD progression. Our novel artificial intelligence achieved an 86% accuracy rate for the NASH steatosis staging task (non-NASH, steatosis grade 1, steatosis grade 2, and steatosis grade 3) and an impressive 96% AUC-ROC for distinguishing between NASH (steatosis grade 1, grade 2, and grade3) and non-NASH cases, outperforming current state-of-the-art models. This notable improvement in diagnostic performance underscores the potential application of artificial intelligence in the early diagnosis and treatment of NAFLD, leading to better patient outcomes and a reduced healthcare burden associated with advanced liver disease.
Enhancing Osteoporosis Detection: An Explainable Multi-Modal Learning Framework with Feature Fusion and Variable Clustering
Nov 01, 2024



Osteoporosis is a common condition that increases fracture risk, especially in older adults. Early diagnosis is vital for preventing fractures, reducing treatment costs, and preserving mobility. However, healthcare providers face challenges like limited labeled data and difficulties in processing medical images. This study presents a novel multi-modal learning framework that integrates clinical and imaging data to improve diagnostic accuracy and model interpretability. The model utilizes three pre-trained networks-VGG19, InceptionV3, and ResNet50-to extract deep features from X-ray images. These features are transformed using PCA to reduce dimensionality and focus on the most relevant components. A clustering-based selection process identifies the most representative components, which are then combined with preprocessed clinical data and processed through a fully connected network (FCN) for final classification. A feature importance plot highlights key variables, showing that Medical History, BMI, and Height were the main contributors, emphasizing the significance of patient-specific data. While imaging features were valuable, they had lower importance, indicating that clinical data are crucial for accurate predictions. This framework promotes precise and interpretable predictions, enhancing transparency and building trust in AI-driven diagnoses for clinical integration.
Multi-Source Hard and Soft Information Fusion Approach for Accurate Cryptocurrency Price Movement Prediction
Sep 27, 2024



One of the most important challenges in the financial and cryptocurrency field is accurately predicting cryptocurrency price trends. Leveraging artificial intelligence (AI) is beneficial in addressing this challenge. Cryptocurrency markets, marked by substantial growth and volatility, attract investors and scholars keen on deciphering and forecasting cryptocurrency price movements. The vast and diverse array of data available for such predictions increases the complexity of the task. In our study, we introduce a novel approach termed hard and soft information fusion (HSIF) to enhance the accuracy of cryptocurrency price movement forecasts. The hard information component of our approach encompasses historical price records alongside technical indicators. Complementing this, the soft data component extracts from X (formerly Twitter), encompassing news headlines and tweets about the cryptocurrency. To use this data, we use the Bidirectional Encoder Representations from Transformers (BERT)-based sentiment analysis method, financial BERT (FinBERT), which performs best. Finally, our model feeds on the information set including processed hard and soft data. We employ the bidirectional long short-term memory (BiLSTM) model because processing information in both forward and backward directions can capture long-term dependencies in sequential information. Our empirical findings emphasize the superiority of the HSIF approach over models dependent on single-source data by testing on Bitcoin-related data. By fusing hard and soft information on Bitcoin dataset, our model has about 96.8\% accuracy in predicting price movement. Incorporating information enables our model to grasp the influence of social sentiment on price fluctuations, thereby supplementing the technical analysis-based predictions derived from hard information.
Deep Representation of Imbalanced Spatio-temporal Traffic Flow Data for Traffic Accident Detection
Aug 21, 2021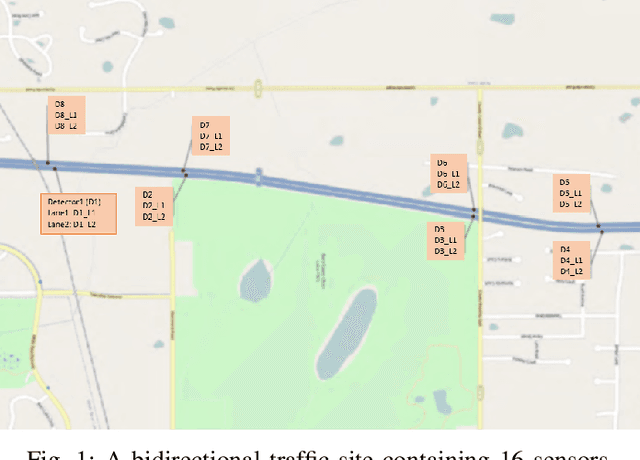
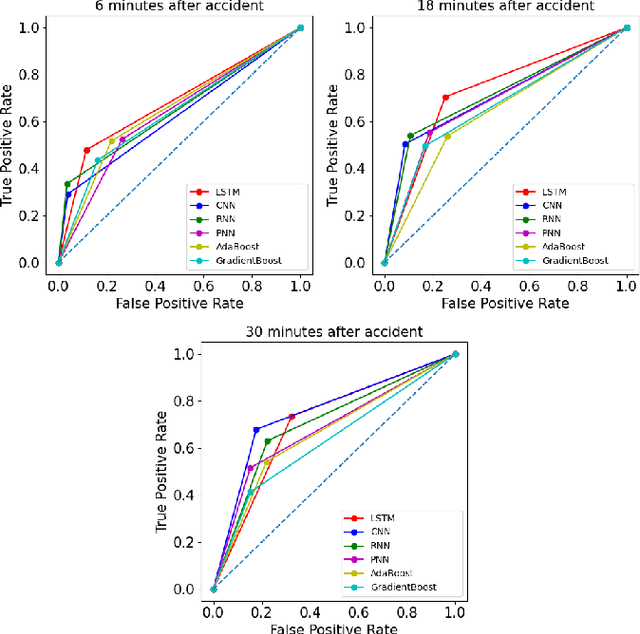

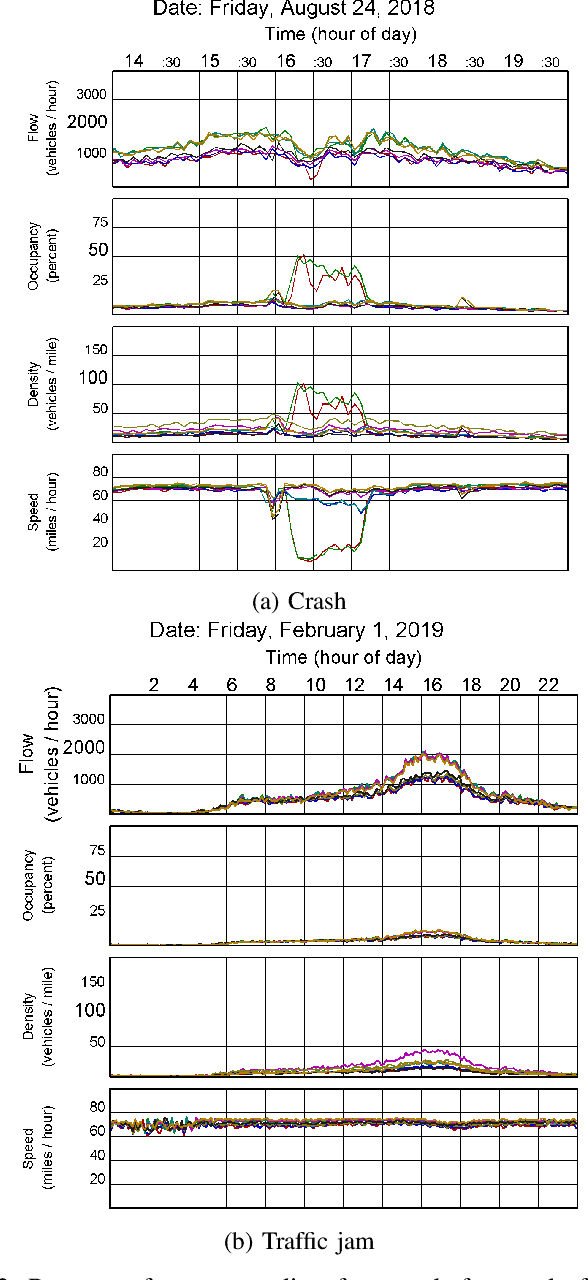
Automatic detection of traffic accidents has a crucial effect on improving transportation, public safety, and path planning. Many lives can be saved by the consequent decrease in the time between when the accidents occur and when rescue teams are dispatched, and much travelling time can be saved by notifying drivers to select alternative routes. This problem is challenging mainly because of the rareness of accidents and spatial heterogeneity of the environment. This paper studies deep representation of loop detector data using Long-Short Term Memory (LSTM) network for automatic detection of freeway accidents. The LSTM-based framework increases class separability in the encoded feature space while reducing the dimension of data. Our experiments on real accident and loop detector data collected from the Twin Cities Metro freeways of Minnesota demonstrate that deep representation of traffic flow data using LSTM network has the potential to detect freeway accidents in less than 18 minutes with a true positive rate of 0.71 and a false positive rate of 0.25 which outperforms other competing methods in the same arrangement.