 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealth Signals: Multi-Discriminator GANs for Covert Communications Against Diverse Wardens
May 01, 2025Covert wireless communications are critical for concealing the existence of any transmission from adversarial wardens, particularly in complex environments with multiple heterogeneous detectors. This paper proposes a novel adversarial AI framework leveraging a multi-discriminator Generative Adversarial Network (GAN) to design signals that evade detection by diverse wardens, while ensuring reliable decoding by the intended receiver. The transmitter is modeled as a generator that produces noise-like signals, while every warden is modeled as an individual discriminator, suggesting varied channel conditions and detection techniques. Unlike traditional methods like spread spectrum or single-discriminator GANs, our approach addresses multi-warden scenarios with moving receiver and wardens, which enhances robustness in urban surveillance, military operations, and 6G networks. Performance evaluation shows encouraging results with improved detection probabilities and bit error rates (BERs), in up to five warden cases, compared to noise injection and single-discriminator baselines. The scalability and flexibility of the system make it a potential candidate for future wireless secure systems, and potential future directions include real-time optimization and synergy with 6G technologies such as intelligent reflecting surfaces.
Vision Transformer for Intracranial Hemorrhage Classification in CT Scans Using an Entropy-Aware Fuzzy Integral Strategy for Adaptive Scan-Level Decision Fusion
Mar 11, 2025Intracranial hemorrhage (ICH) is a critical medical emergency caused by the rupture of cerebral blood vessels, leading to internal bleeding within the skull. Accurate and timely classification of hemorrhage subtypes is essential for effective clinical decision-making. To address this challenge, we propose an advanced pyramid vision transformer (PVT)-based model, leveraging its hierarchical attention mechanisms to capture both local and global spatial dependencies in brain CT scans. Instead of processing all extracted features indiscriminately, A SHAP-based feature selection method is employed to identify the most discriminative components, which are then used as a latent feature space to train a boosting neural network, reducing computational complexity. We introduce an entropy-aware aggregation strategy along with a fuzzy integral operator to fuse information across multiple CT slices, ensuring a more comprehensive and reliable scan-level diagnosis by accounting for inter-slice dependencies. Experimental results show that our PVT-based framework significantly outperforms state-of-the-art deep learning architectures in terms of classification accuracy, precision, and robustness. By combining SHAP-driven feature selection, transformer-based modeling, and an entropy-aware fuzzy integral operator for decision fusion, our method offers a scalable and computationally efficient AI-driven solution for automated ICH subtype classification.
AI-Powered Intracranial Hemorrhage Detection: A Co-Scale Convolutional Attention Model with Uncertainty-Based Fuzzy Integral Operator and Feature Screening
Dec 19, 2024



Intracranial hemorrhage (ICH) refers to the leakage or accumulation of blood within the skull, which occurs due to the rupture of blood vessels in or around the brain. If this condition is not diagnosed in a timely manner and appropriately treated, it can lead to serious complications such as decreased consciousness, permanent neurological disabilities, or even death.The primary aim of this study is to detect the occurrence or non-occurrence of ICH, followed by determining the type of subdural hemorrhage (SDH). These tasks are framed as two separate binary classification problems. By adding two layers to the co-scale convolutional attention (CCA) classifier architecture, we introduce a novel approach for ICH detection. In the first layer, after extracting features from different slices of computed tomography (CT) scan images, we combine these features and select the 50 components that capture the highest variance in the data, considering them as informative features. We then assess the discriminative power of these features using the bootstrap forest algorithm, discarding those that lack sufficient discriminative ability between different classes. This algorithm explicitly determines the contribution of each feature to the final prediction, assisting us in developing an explainable AI model. The features feed into a boosting neural network as a latent feature space. In the second layer, we introduce a novel uncertainty-based fuzzy integral operator to fuse information from different CT scan slices. This operator, by accounting for the dependencies between consecutive slices, significantly improves detection accuracy.
Enhancing Osteoporosis Detection: An Explainable Multi-Modal Learning Framework with Feature Fusion and Variable Clustering
Nov 01, 2024



Osteoporosis is a common condition that increases fracture risk, especially in older adults. Early diagnosis is vital for preventing fractures, reducing treatment costs, and preserving mobility. However, healthcare providers face challenges like limited labeled data and difficulties in processing medical images. This study presents a novel multi-modal learning framework that integrates clinical and imaging data to improve diagnostic accuracy and model interpretability. The model utilizes three pre-trained networks-VGG19, InceptionV3, and ResNet50-to extract deep features from X-ray images. These features are transformed using PCA to reduce dimensionality and focus on the most relevant components. A clustering-based selection process identifies the most representative components, which are then combined with preprocessed clinical data and processed through a fully connected network (FCN) for final classification. A feature importance plot highlights key variables, showing that Medical History, BMI, and Height were the main contributors, emphasizing the significance of patient-specific data. While imaging features were valuable, they had lower importance, indicating that clinical data are crucial for accurate predictions. This framework promotes precise and interpretable predictions, enhancing transparency and building trust in AI-driven diagnoses for clinical integration.
Multi-Source Hard and Soft Information Fusion Approach for Accurate Cryptocurrency Price Movement Prediction
Sep 27, 2024



One of the most important challenges in the financial and cryptocurrency field is accurately predicting cryptocurrency price trends. Leveraging artificial intelligence (AI) is beneficial in addressing this challenge. Cryptocurrency markets, marked by substantial growth and volatility, attract investors and scholars keen on deciphering and forecasting cryptocurrency price movements. The vast and diverse array of data available for such predictions increases the complexity of the task. In our study, we introduce a novel approach termed hard and soft information fusion (HSIF) to enhance the accuracy of cryptocurrency price movement forecasts. The hard information component of our approach encompasses historical price records alongside technical indicators. Complementing this, the soft data component extracts from X (formerly Twitter), encompassing news headlines and tweets about the cryptocurrency. To use this data, we use the Bidirectional Encoder Representations from Transformers (BERT)-based sentiment analysis method, financial BERT (FinBERT), which performs best. Finally, our model feeds on the information set including processed hard and soft data. We employ the bidirectional long short-term memory (BiLSTM) model because processing information in both forward and backward directions can capture long-term dependencies in sequential information. Our empirical findings emphasize the superiority of the HSIF approach over models dependent on single-source data by testing on Bitcoin-related data. By fusing hard and soft information on Bitcoin dataset, our model has about 96.8\% accuracy in predicting price movement. Incorporating information enables our model to grasp the influence of social sentiment on price fluctuations, thereby supplementing the technical analysis-based predictions derived from hard information.
A Comprehensive Analysis of Blockchain Applications for Securing Computer Vision Systems
Jul 13, 2023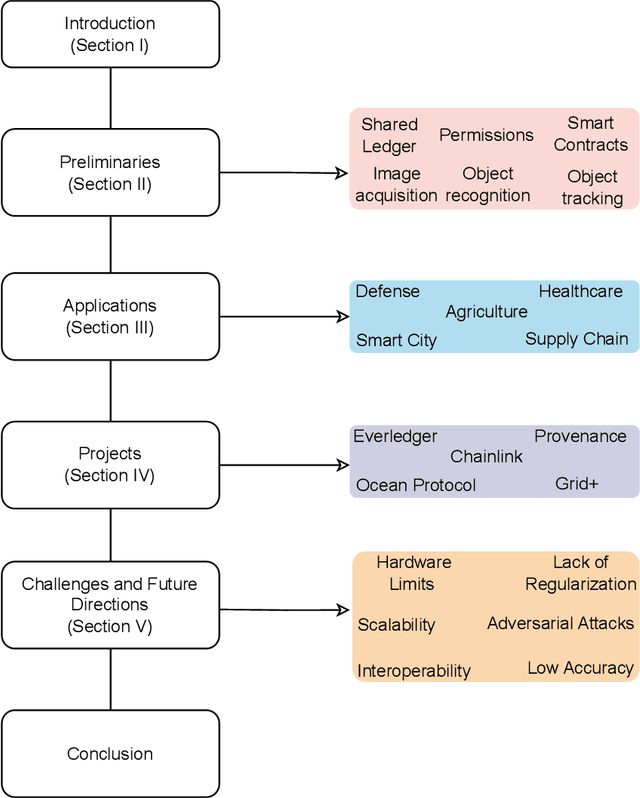
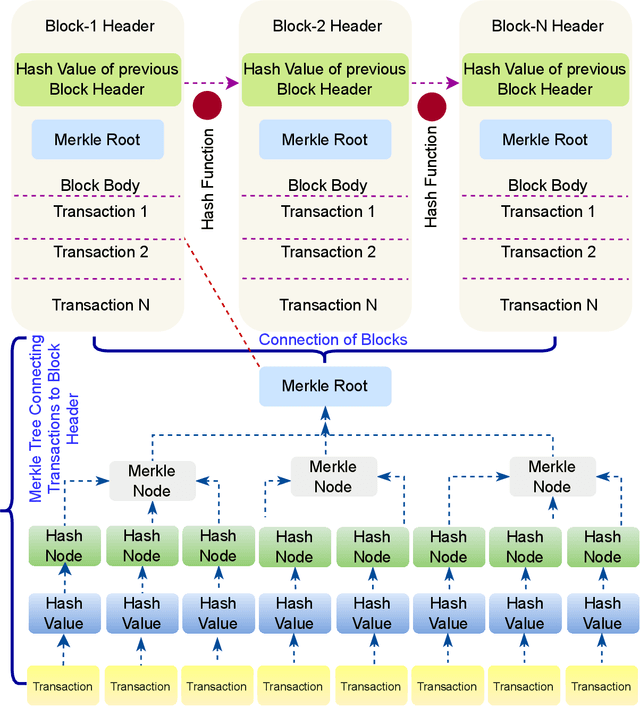
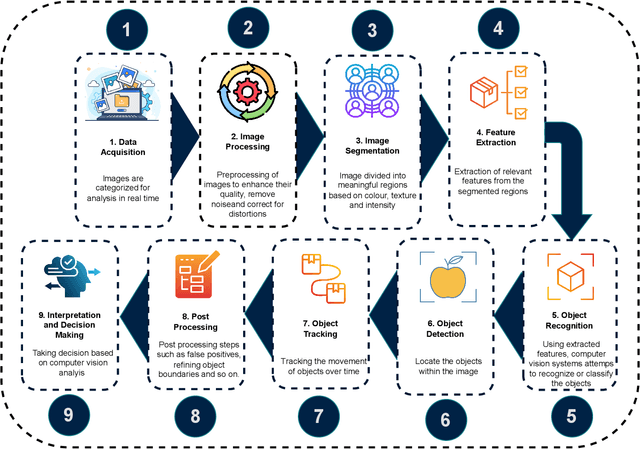
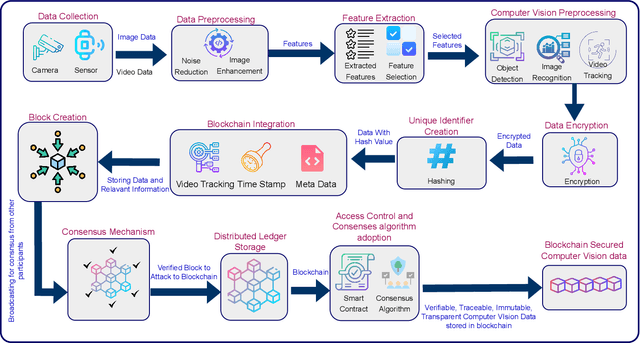
Blockchain (BC) and Computer Vision (CV) are the two emerging fields with the potential to transform various sectors.The ability of BC can help in offering decentralized and secure data storage, while CV allows machines to learn and understand visual data. This integration of the two technologies holds massive promise for developing innovative applications that can provide solutions to the challenges in various sectors such as supply chain management, healthcare, smart cities, and defense. This review explores a comprehensive analysis of the integration of BC and CV by examining their combination and potential applications. It also provides a detailed analysis of the fundamental concepts of both technologies, highlighting their strengths and limitations. This paper also explores current research efforts that make use of the benefits offered by this combination. The effort includes how BC can be used as an added layer of security in CV systems and also ensure data integrity, enabling decentralized image and video analytics using BC. The challenges and open issues associated with this integration are also identified, and appropriate potential future directions are also proposed.
A Comprehensive Survey on Affective Computing; Challenges, Trends, Applications, and Future Directions
May 08, 2023As the name suggests, affective computing aims to recognize human emotions, sentiments, and feelings. There is a wide range of fields that study affective computing, including languages, sociology, psychology, computer science, and physiology. However, no research has ever been done to determine how machine learning (ML) and mixed reality (XR) interact together. This paper discusses the significance of affective computing, as well as its ideas, conceptions, methods, and outcomes. By using approaches of ML and XR, we survey and discuss recent methodologies in affective computing. We survey the state-of-the-art approaches along with current affective data resources. Further, we discuss various applications where affective computing has a significant impact, which will aid future scholars in gaining a better understanding of its significance and practical relevance.
A Comprehensive Survey of Transformers for Computer Vision
Nov 11, 2022As a special type of transformer, Vision Transformers (ViTs) are used to various computer vision applications (CV), such as image recognition. There are several potential problems with convolutional neural networks (CNNs) that can be solved with ViTs. For image coding tasks like compression, super-resolution, segmentation, and denoising, different variants of the ViTs are used. The purpose of this survey is to present the first application of ViTs in CV. The survey is the first of its kind on ViTs for CVs to the best of our knowledge. In the first step, we classify different CV applications where ViTs are applicable. CV applications include image classification, object detection, image segmentation, image compression, image super-resolution, image denoising, and anomaly detection. Our next step is to review the state-of-the-art in each category and list the available models. Following that, we present a detailed analysis and comparison of each model and list its pros and cons. After that, we present our insights and lessons learned for each category. Moreover, we discuss several open research challenges and future research directions.
Learning-Driven Lossy Image Compression; A Comprehensive Survey
Jan 23, 2022In the realm of image processing and computer vision (CV), machine learning (ML) architectures are widely applied. Convolutional neural networks (CNNs) solve a wide range of image processing issues and can solve image compression problem. Compression of images is necessary due to bandwidth and memory constraints. Helpful, redundant, and irrelevant information are three different forms of information found in images. This paper aims to survey recent techniques utilizing mostly lossy image compression using ML architectures including different auto-encoders (AEs) such as convolutional auto-encoders (CAEs), variational auto-encoders (VAEs), and AEs with hyper-prior models, recurrent neural networks (RNNs), CNNs, generative adversarial networks (GANs), principal component analysis (PCA) and fuzzy means clustering. We divide all of the algorithms into several groups based on architecture. We cover still image compression in this survey. Various discoveries for the researchers are emphasized and possible future directions for researchers. The open research problems such as out of memory (OOM), striped region distortion (SRD), aliasing, and compatibility of the frameworks with central processing unit (CPU) and graphics processing unit (GPU) simultaneously are explained. The majority of the publications in the compression domain surveyed are from the previous five years and use a variety of approaches.