 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relation of State Space Models and Hidden Markov Models
Jan 19, 2026State Space Models (SSMs) and Hidden Markov Models (HMMs) are foundational frameworks for modeling sequential data with latent variables and are widely used in signal processing, control theory, and machine learning. Despite their shared temporal structure, they differ fundamentally in the nature of their latent states, probabilistic assumptions, inference procedures, and training paradigms. Recently, deterministic state space models have re-emerged in natural language processing through architectures such as S4 and Mamba, raising new questions about the relationship between classical probabilistic SSMs, HMMs, and modern neural sequence models. In this paper, we present a unified and systematic comparison of HMMs, linear Gaussian state space models, Kalman filtering, and contemporary NLP state space models. We analyze their formulations through the lens of probabilistic graphical models, examine their inference algorithms -- including forward-backward inference and Kalman filtering -- and contrast their learning procedures via Expectation-Maximization and gradient-based optimization. By highlighting both structural similarities and semantic differences, we clarify when these models are equivalent, when they fundamentally diverge, and how modern NLP SSMs relate to classical probabilistic models. Our analysis bridges perspectives from control theory, probabilistic modeling, and modern deep learning.
Wittgenstein's Family Resemblance Clustering Algorithm
Jan 07, 2026This paper, introducing a novel method in philomatics, draws on Wittgenstein's concept of family resemblance from analytic philosophy to develop a clustering algorithm for machine learning. According to Wittgenstein's Philosophical Investigations (1953), family resemblance holds that members of a concept or category are connected by overlapping similarities rather than a single defining property. Consequently, a family of entities forms a chain of items sharing overlapping traits. This philosophical idea naturally lends itself to a graph-based approach in machine learning. Accordingly, we propose the Wittgenstein's Family Resemblance (WFR) clustering algorithm and its kernel variant, kernel WFR. This algorithm computes resemblance scores between neighboring data instances, and after thresholding these scores, a resemblance graph is constructed. The connected components of this graph define the resulting clusters. Simulations on benchmark datasets demonstrate that WFR is an effective nonlinear clustering algorithm that does not require prior knowledge of the number of clusters or assumptions about their shapes.
Kernel VICReg for Self-Supervised Learning in Reproducing Kernel Hilbert Space
Sep 08, 2025Self-supervised learning (SSL) has emerged as a powerful paradigm for representation learning by optimizing geometric objectives--such as invariance to augmentations, variance preservation, and feature decorrelation--without requiring labels. However, most existing methods operate in Euclidean space, limiting their ability to capture nonlinear dependencies and geometric structures. In this work, we propose Kernel VICReg, a novel self-supervised learning framework that lifts the VICReg objective into a Reproducing Kernel Hilbert Space (RKHS). By kernelizing each term of the loss-variance, invariance, and covariance--we obtain a general formulation that operates on double-centered kernel matrices and Hilbert-Schmidt norms, enabling nonlinear feature learning without explicit mappings. We demonstrate that Kernel VICReg not only avoids representational collapse but also improves performance on tasks with complex or small-scale data. Empirical evaluations across MNIST, CIFAR-10, STL-10, TinyImageNet, and ImageNet100 show consistent gains over Euclidean VICReg, with particularly strong improvements on datasets where nonlinear structures are prominent. UMAP visualizations further confirm that kernel-based embeddings exhibit better isometry and class separation. Our results suggest that kernelizing SSL objectives is a promising direction for bridging classical kernel methods with modern representation learning.
Self-Supervised Learning Using Nonlinear Dependence
Jan 31, 2025



Self-supervised learning has gained significant attention in contemporary applications, particularly due to the scarcity of labeled data. While existing SSL methodologies primarily address feature variance and linear correlations, they often neglect the intricate relations between samples and the nonlinear dependencies inherent in complex data. In this paper, we introduce Correlation-Dependence Self-Supervised Learning (CDSSL), a novel framework that unifies and extends existing SSL paradigms by integrating both linear correlations and nonlinear dependencies, encapsulating sample-wise and feature-wise interactions. Our approach incorporates the Hilbert-Schmidt Independence Criterion (HSIC) to robustly capture nonlinear dependencies within a Reproducing Kernel Hilbert Space, enriching representation learning. Experimental evaluations on diverse benchmarks demonstrate the efficacy of CDSSL in improving representation quality.
An Optimal Cascade Feature-Level Spatiotemporal Fusion Strategy for Anomaly Detection in CAN Bus
Jan 31, 2025



Autonomous vehicles represent a revolutionary advancement driven by the integration of artificial intelligence within intelligent transportation systems. However, they remain vulnerable due to the absence of robust security mechanisms in the Controller Area Network (CAN) bus. In order to mitigate the security issue, many machine learning models and strategies have been proposed, which primarily focus on a subset of dominant patterns of anomalies and lack rigorous evaluation in terms of reliability and robustness. Therefore, to address the limitations of previous works and mitigate the security vulnerability in CAN bus, the current study develops a model based on the intrinsic nature of the problem to cover all dominant patterns of anomalies. To achieve this, a cascade feature-level fusion strategy optimized by a two-parameter genetic algorithm is proposed to combine temporal and spatial information. Subsequently, the model is evaluated using a paired t-test to ensure reliability and robustness. Finally, a comprehensive comparative analysis conducted on two widely used datasets advocates that the proposed model outperforms other models and achieves superior accuracy and F1-score, demonstrating the best performance among all models presented to date.
Probabilistic Classification by Density Estimation Using Gaussian Mixture Model and Masked Autoregressive Flow
Oct 16, 2023Density estimation, which estimates the distribution of data, is an important category of probabilistic machine learning. A family of density estimators is mixture models, such as Gaussian Mixture Model (GMM) by expectation maximization. Another family of density estimators is the generative models which generate data from input latent variables. One of the generative models is the Masked Autoregressive Flow (MAF) which makes use of normalizing flows and autoregressive networks. In this paper, we use the density estimators for classification, although they are often used for estimating the distribution of data. We model the likelihood of classes of data by density estimation, specifically using GMM and MAF. The proposed classifiers outperform simpler classifiers such as linear discriminant analysis which model the likelihood using only a single Gaussian distribution. This work opens the research door for proposing other probabilistic classifiers based on joint density estimation.
On Philomatics and Psychomatics for Combining Philosophy and Psychology with Mathematics
Aug 26, 2023We propose the concepts of philomatics and psychomatics as hybrid combinations of philosophy and psychology with mathematics. We explain four motivations for this combination which are fulfilling the desire of analytical philosophy, proposing science of philosophy, justifying mathematical algorithms by philosophy, and abstraction in both philosophy and mathematics. We enumerate various examples for philomatics and psychomatics, some of which are explained in more depth. The first example is the analysis of relation between the context principle, semantic holism, and the usage theory of meaning with the attention mechanism in mathematics. The other example is on the relations of Plato's theory of forms in philosophy with the holographic principle in string theory, object-oriented programming, and machine learning. Finally, the relation between Wittgenstein's family resemblance and clustering in mathematics is explained. This paper opens the door of research for combining philosophy and psychology with mathematics.
Recurrent Neural Networks and Long Short-Term Memory Networks: Tutorial and Survey
Apr 22, 2023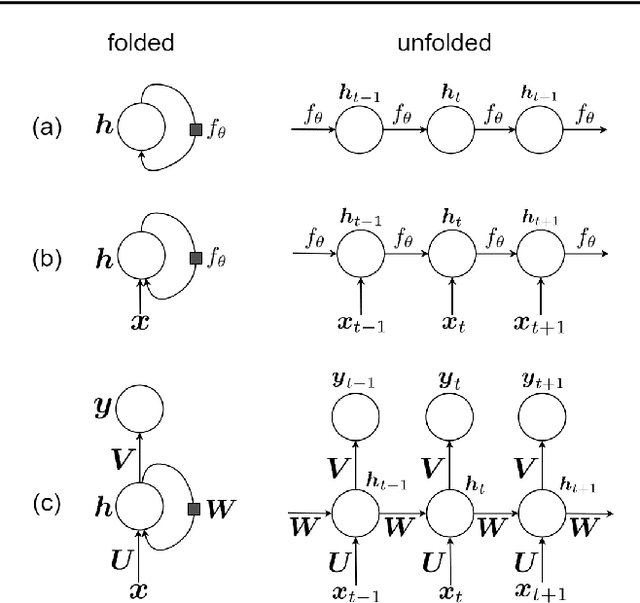
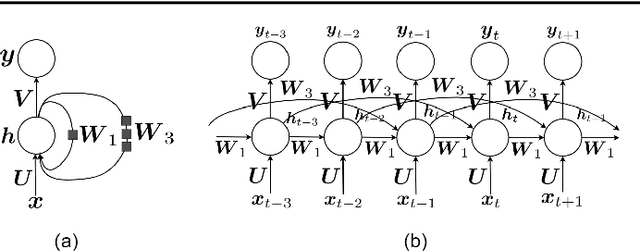
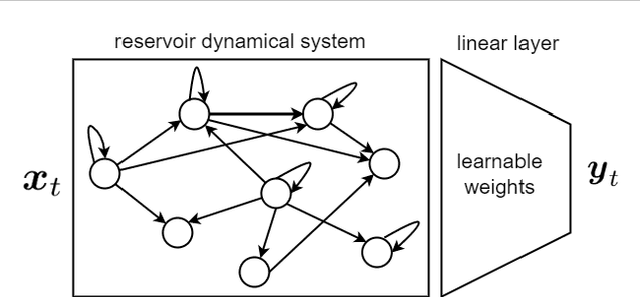
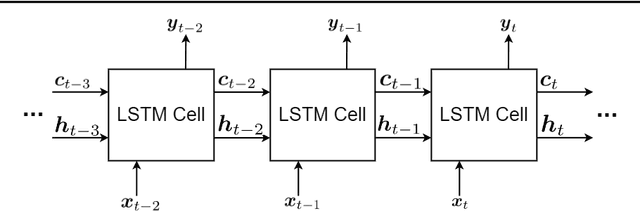
This is a tutorial paper on Recurrent Neural Network (RNN), Long Short-Term Memory Network (LSTM), and their variants. We start with a dynamical system and backpropagation through time for RNN. Then, we discuss the problems of gradient vanishing and explosion in long-term dependencies. We explain close-to-identity weight matrix, long delays, leaky units, and echo state networks for solving this problem. Then, we introduce LSTM gates and cells, history and variants of LSTM, and Gated Recurrent Units (GRU). Finally, we introduce bidirectional RNN, bidirectional LSTM, and the Embeddings from Language Model (ELMo) network, for processing a sequence in both directions.
Gravitational Dimensionality Reduction Using Newtonian Gravity and Einstein's General Relativity
Oct 30, 2022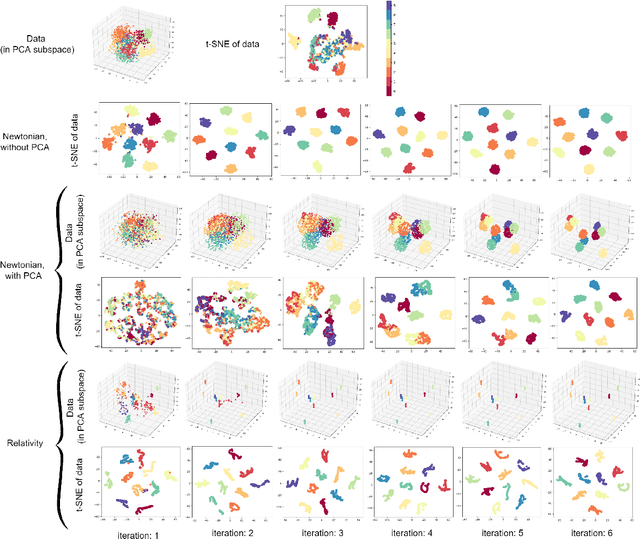
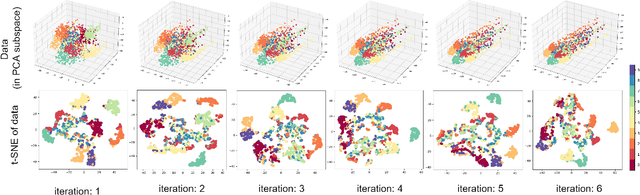
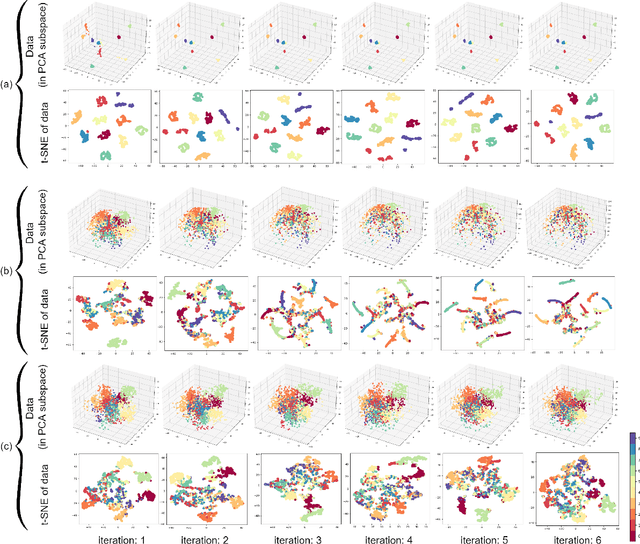
Due to the effectiveness of using machine learning in physics, it has been widely received increased attention in the literature. However, the notion of applying physics in machine learning has not been given much awareness to. This work is a hybrid of physics and machine learning where concepts of physics are used in machine learning. We propose the supervised Gravitational Dimensionality Reduction (GDR) algorithm where the data points of every class are moved to each other for reduction of intra-class variances and better separation of classes. For every data point, the other points are considered to be gravitational particles, such as stars, where the point is attracted to the points of its class by gravity. The data points are first projected onto a spacetime manifold using principal component analysis. We propose two variants of GDR -- one with the Newtonian gravity and one with the Einstein's general relativity. The former uses Newtonian gravity in a straight line between points but the latter moves data points along the geodesics of spacetime manifold. For GDR with relativity gravitation, we use both Schwarzschild and Minkowski metric tensors to cover both general relativity and special relativity. Our simulations show the effectiveness of GDR in discrimination of classes.
Affective Manifolds: Modeling Machine's Mind to Like, Dislike, Enjoy, Suffer, Worry, Fear, and Feel Like A Human
Aug 29, 2022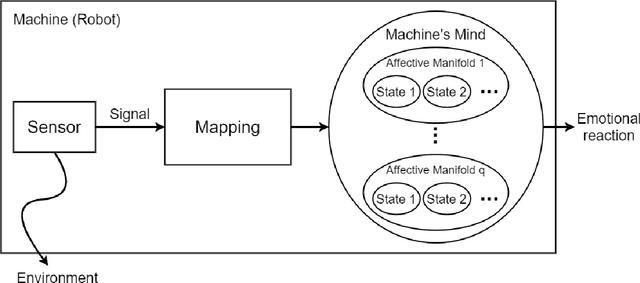
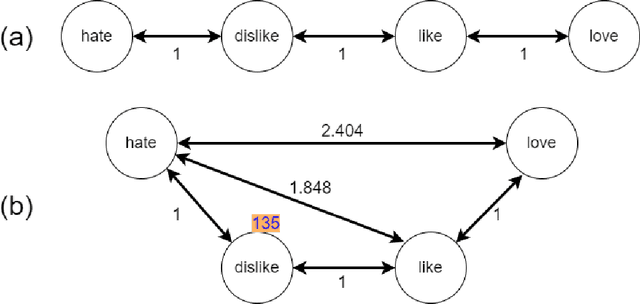
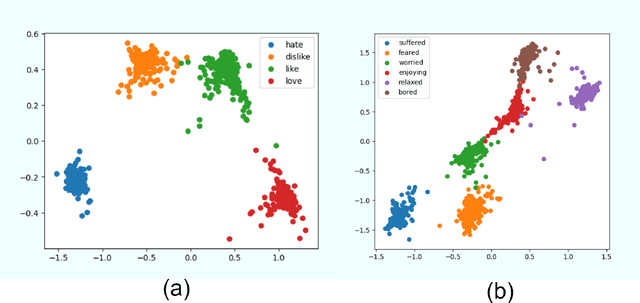
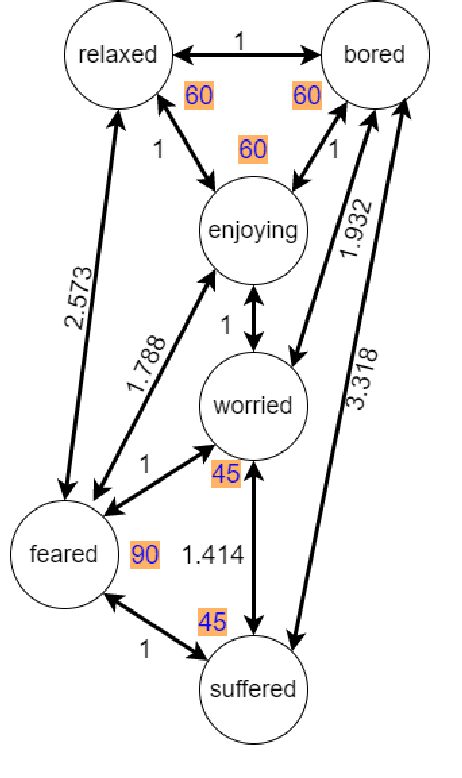
After the development of different machine learning and manifold learning algorithms, it may be a good time to put them together to make a powerful mind for machine. In this work, we propose affective manifolds as components of a machine's mind. Every affective manifold models a characteristic group of mind and contains multiple states. We define the machine's mind as a set of affective manifolds. We use a learning model for mapping the input signals to the embedding space of affective manifold. Using this mapping, a machine or a robot takes an input signal and can react emotionally to it. We use deep metric learning, with Siamese network, and propose a loss function for affective manifold learning. We define margins between states based on the psychological and philosophical studies. Using triplets of instances, we train the network to minimize the variance of every state and have the desired distances between states. We show that affective manifolds can have various applications for machine-machine and human-machine interactions. Some simulations are also provided for verification of the proposed method. It is possible to have as many affective manifolds as required in machine's mind. More affective manifolds in the machine's mind can make it more realistic and effective. This paper opens the door; we invite the researchers from various fields of science to propose more affective manifolds to be inserted in machine's mind.