 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtean Compiler: An Agile Framework to Drive Fine-grain Phase Ordering
Feb 05, 2026The phase ordering problem has been a long-standing challenge since the late 1970s, yet it remains an open problem due to having a vast optimization space and an unbounded nature, making it an open-ended problem without a finite solution, one can limit the scope by reducing the number and the length of optimizations. Traditionally, such locally optimized decisions are made by hand-coded algorithms tuned for a small number of benchmarks, often requiring significant effort to be retuned when the benchmark suite changes. In the past 20 years, Machine Learning has been employed to construct performance models to improve the selection and ordering of compiler optimizations, however, the approaches are not baked into the compiler seamlessly and never materialized to be leveraged at a fine-grained scope of code segments. This paper presents Protean Compiler: An agile framework to enable LLVM with built-in phase-ordering capabilities at a fine-grained scope. The framework also comprises a complete library of more than 140 handcrafted static feature collection methods at varying scopes, and the experimental results showcase speedup gains of up to 4.1% on average and up to 15.7% on select Cbench applications wrt LLVM's O3 by just incurring a few extra seconds of build time on Cbench. Additionally, Protean compiler allows for an easy integration with third-party ML frameworks and other Large Language Models, and this two-step optimization shows a gain of 10.1% and 8.5% speedup wrt O3 on Cbench's Susan and Jpeg applications. Protean compiler is seamlessly integrated into LLVM and can be used as a new, enhanced, full-fledged compiler. We plan to release the project to the open-source community in the near future.
PerfCoder: Large Language Models for Interpretable Code Performance Optimization
Dec 16, 2025


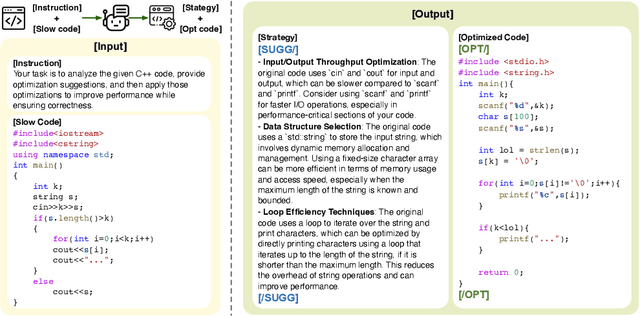
Large language models (LLMs) have achieved remarkable progress in automatic code generation, yet their ability to produce high-performance code remains limited--a critical requirement in real-world software systems. We argue that current LLMs struggle not only due to data scarcity but, more importantly, because they lack supervision that guides interpretable and effective performance improvements. In this work, we introduce PerfCoder, a family of LLMs specifically designed to generate performance-enhanced code from source code via interpretable, customized optimizations. PerfCoder is fine-tuned on a curated collection of real-world optimization trajectories with human-readable annotations, and preference-aligned by reinforcement fine-tuning using runtime measurements, enabling it to propose input-specific improvement strategies and apply them directly without relying on iterative refinement. On the PIE code performance benchmark, PerfCoder surpasses all existing models in both runtime speedup and effective optimization rate, demonstrating that performance optimization cannot be achieved by scale alone but requires optimization stratetgy awareness. In addition, PerfCoder can generate interpretable feedback about the source code, which, when provided as input to a larger LLM in a planner-and-optimizer cooperative workflow, can further improve outcomes. Specifically, we elevate the performance of 32B models and GPT-5 to new levels on code optimization, substantially surpassing their original performance.
Disentanglement in Implicit Causal Models via Switch Variable
Feb 16, 2024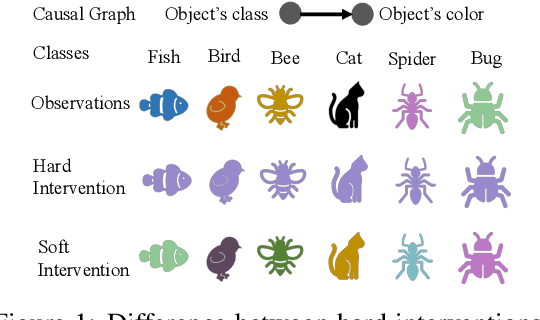


Learning causal representations from observational and interventional data in the absence of known ground-truth graph structures necessitates implicit latent causal representation learning. Implicitly learning causal mechanisms typically involves two categories of interventional data: hard and soft interventions. In real-world scenarios, soft interventions are often more realistic than hard interventions, as the latter require fully controlled environments. Unlike hard interventions, which directly force changes in a causal variable, soft interventions exert influence indirectly by affecting the causal mechanism. In this paper, we tackle implicit latent causal representation learning in a Variational Autoencoder (VAE) framework through soft interventions. Our approach models soft interventions effects by employing a causal mechanism switch variable designed to toggle between different causal mechanisms. In our experiments, we consistently observe improved learning of identifiable, causal representations, compared to baseline approaches.
Generative Causal Representation Learning for Out-of-Distribution Motion Forecasting
Feb 17, 2023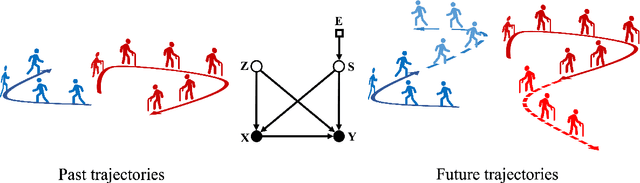
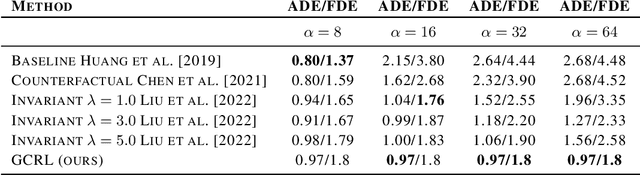
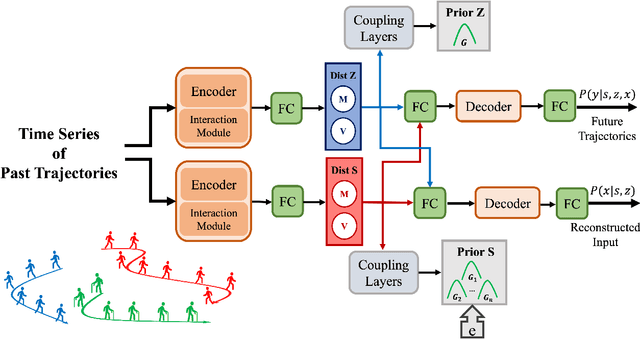

Conventional supervised learning methods typically assume i.i.d samples and are found to be sensitive to out-of-distribution (OOD) data. We propose Generative Causal Representation Learning (GCRL) which leverages causality to facilitate knowledge transfer under distribution shifts. While we evaluate the effectiveness of our proposed method in human trajectory prediction models, GCRL can be applied to other domains as well. First, we propose a novel causal model that explains the generative factors in motion forecasting datasets using features that are common across all environments and with features that are specific to each environment. Selection variables are used to determine which parts of the model can be directly transferred to a new environment without fine-tuning. Second, we propose an end-to-end variational learning paradigm to learn the causal mechanisms that generate observations from features. GCRL is supported by strong theoretical results that imply identifiability of the causal model under certain assumptions. Experimental results on synthetic and real-world motion forecasting datasets show the robustness and effectiveness of our proposed method for knowledge transfer under zero-shot and low-shot settings by substantially outperforming the prior motion forecasting models on out-of-distribution prediction.
Deep Representation of Imbalanced Spatio-temporal Traffic Flow Data for Traffic Accident Detection
Aug 21, 2021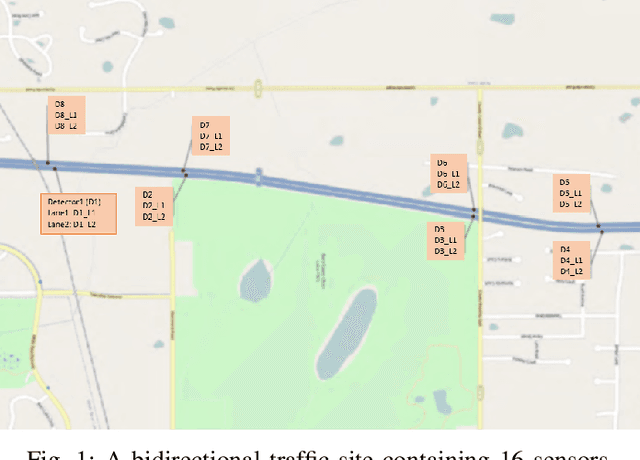
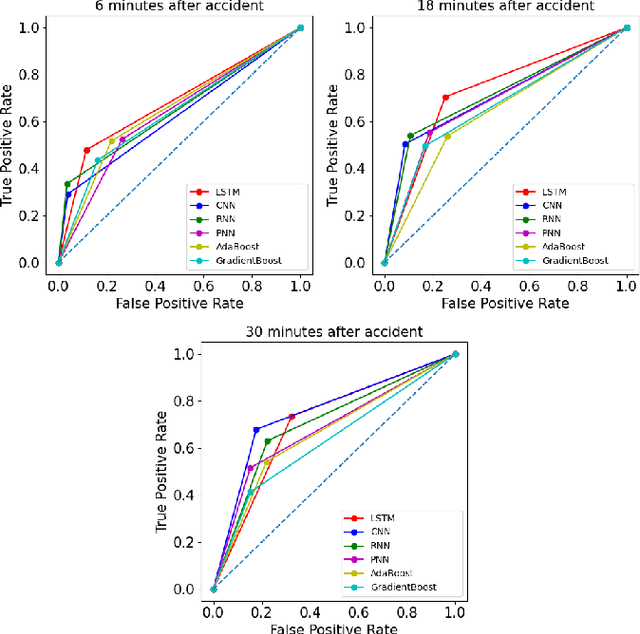

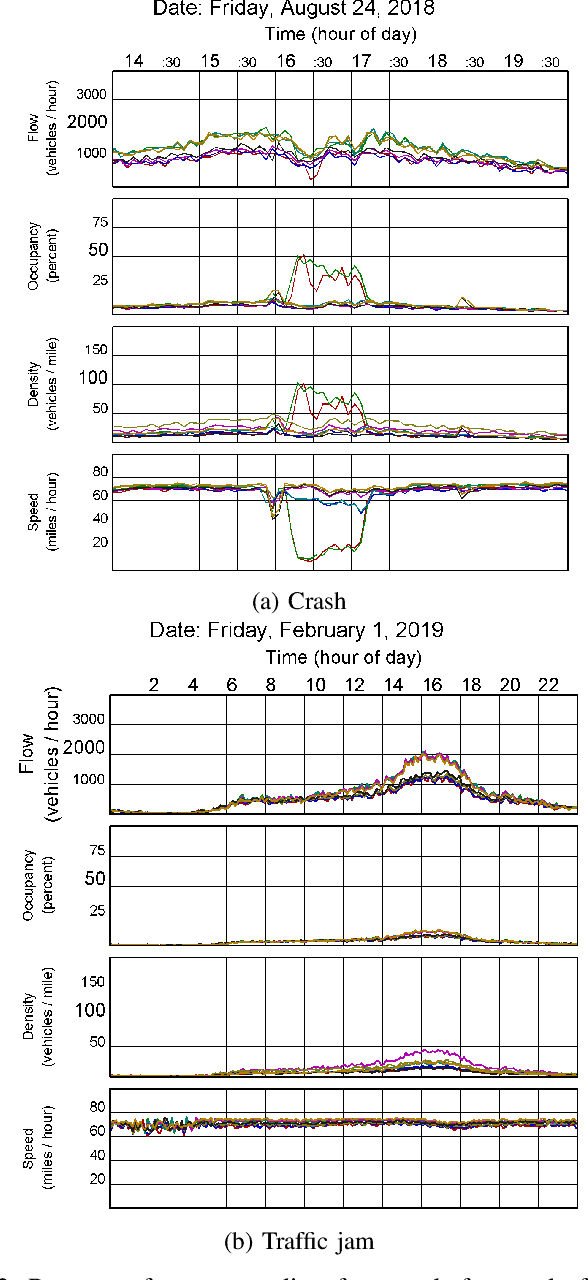
Automatic detection of traffic accidents has a crucial effect on improving transportation, public safety, and path planning. Many lives can be saved by the consequent decrease in the time between when the accidents occur and when rescue teams are dispatched, and much travelling time can be saved by notifying drivers to select alternative routes. This problem is challenging mainly because of the rareness of accidents and spatial heterogeneity of the environment. This paper studies deep representation of loop detector data using Long-Short Term Memory (LSTM) network for automatic detection of freeway accidents. The LSTM-based framework increases class separability in the encoded feature space while reducing the dimension of data. Our experiments on real accident and loop detector data collected from the Twin Cities Metro freeways of Minnesota demonstrate that deep representation of traffic flow data using LSTM network has the potential to detect freeway accidents in less than 18 minutes with a true positive rate of 0.71 and a false positive rate of 0.25 which outperforms other competing methods in the same arrangement.