 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIOSCAN-5M: A Multimodal Dataset for Insect Biodiversity
Jun 18, 2024



As part of an ongoing worldwide effort to comprehend and monitor insect biodiversity, this paper presents the BIOSCAN-5M Insect dataset to the machine learning community and establish several benchmark tasks. BIOSCAN-5M is a comprehensive dataset containing multi-modal information for over 5 million insect specimens, and it significantly expands existing image-based biological datasets by including taxonomic labels, raw nucleotide barcode sequences, assigned barcode index numbers, and geographical information. We propose three benchmark experiments to demonstrate the impact of the multi-modal data types on the classification and clustering accuracy. First, we pretrain a masked language model on the DNA barcode sequences of the \mbox{BIOSCAN-5M} dataset, and demonstrate the impact of using this large reference library on species- and genus-level classification performance. Second, we propose a zero-shot transfer learning task applied to images and DNA barcodes to cluster feature embeddings obtained from self-supervised learning, to investigate whether meaningful clusters can be derived from these representation embeddings. Third, we benchmark multi-modality by performing contrastive learning on DNA barcodes, image data, and taxonomic information. This yields a general shared embedding space enabling taxonomic classification using multiple types of information and modalities. The code repository of the BIOSCAN-5M Insect dataset is available at {\url{https://github.com/zahrag/BIOSCAN-5M}}
Video Relationship Detection Using Mixture of Experts
Mar 06, 2024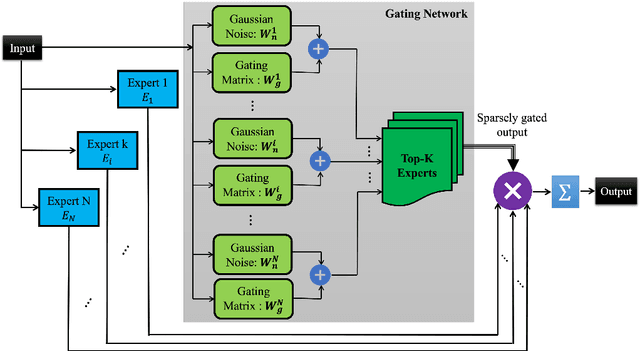
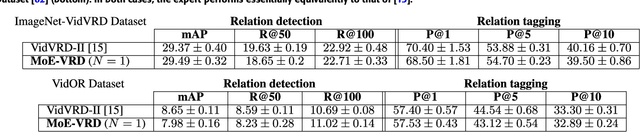
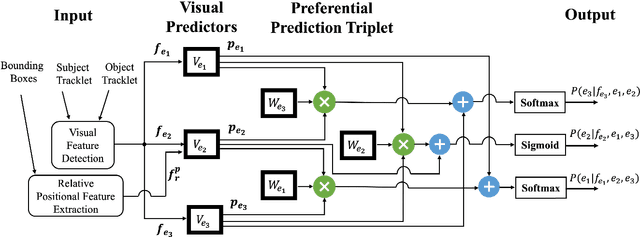
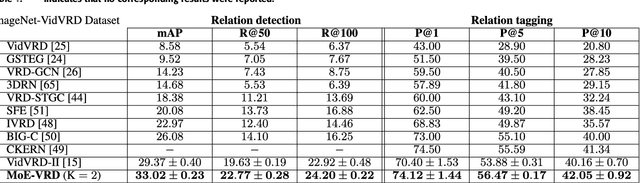
Machine comprehension of visual information from images and videos by neural networks faces two primary challenges. Firstly, there exists a computational and inference gap in connecting vision and language, making it difficult to accurately determine which object a given agent acts on and represent it through language. Secondly, classifiers trained by a single, monolithic neural network often lack stability and generalization. To overcome these challenges, we introduce MoE-VRD, a novel approach to visual relationship detection utilizing a mixture of experts. MoE-VRD identifies language triplets in the form of < subject, predicate, object> tuples to extract relationships from visual processing. Leveraging recent advancements in visual relationship detection, MoE-VRD addresses the requirement for action recognition in establishing relationships between subjects (acting) and objects (being acted upon). In contrast to single monolithic networks, MoE-VRD employs multiple small models as experts, whose outputs are aggregated. Each expert in MoE-VRD specializes in visual relationship learning and object tagging. By utilizing a sparsely-gated mixture of experts, MoE-VRD enables conditional computation and significantly enhances neural network capacity without increasing computational complexity. Our experimental results demonstrate that the conditional computation capabilities and scalability of the mixture-of-experts approach lead to superior performance in visual relationship detection compared to state-of-the-art methods.
Disentanglement in Implicit Causal Models via Switch Variable
Feb 16, 2024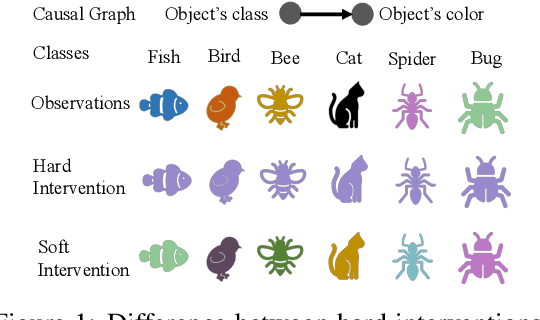


Learning causal representations from observational and interventional data in the absence of known ground-truth graph structures necessitates implicit latent causal representation learning. Implicitly learning causal mechanisms typically involves two categories of interventional data: hard and soft interventions. In real-world scenarios, soft interventions are often more realistic than hard interventions, as the latter require fully controlled environments. Unlike hard interventions, which directly force changes in a causal variable, soft interventions exert influence indirectly by affecting the causal mechanism. In this paper, we tackle implicit latent causal representation learning in a Variational Autoencoder (VAE) framework through soft interventions. Our approach models soft interventions effects by employing a causal mechanism switch variable designed to toggle between different causal mechanisms. In our experiments, we consistently observe improved learning of identifiable, causal representations, compared to baseline approaches.
Memory-Efficient Continual Learning Object Segmentation for Long Video
Sep 26, 2023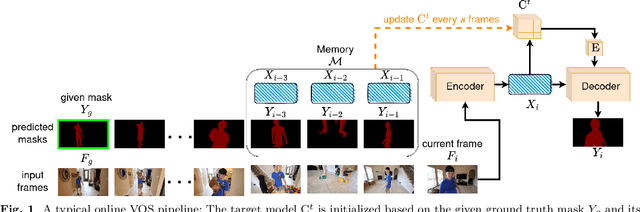



Recent state-of-the-art semi-supervised Video Object Segmentation (VOS) methods have shown significant improvements in target object segmentation accuracy when information from preceding frames is used in undertaking segmentation on the current frame. In particular, such memory-based approaches can help a model to more effectively handle appearance changes (representation drift) or occlusions. Ideally, for maximum performance, online VOS methods would need all or most of the preceding frames (or their extracted information) to be stored in memory and be used for online learning in consecutive frames. Such a solution is not feasible for long videos, as the required memory size would grow without bound. On the other hand, these methods can fail when memory is limited and a target object experiences repeated representation drifts throughout a video. We propose two novel techniques to reduce the memory requirement of online VOS methods while improving modeling accuracy and generalization on long videos. Motivated by the success of continual learning techniques in preserving previously-learned knowledge, here we propose Gated-Regularizer Continual Learning (GRCL), which improves the performance of any online VOS subject to limited memory, and a Reconstruction-based Memory Selection Continual Learning (RMSCL) which empowers online VOS methods to efficiently benefit from stored information in memory. Experimental results show that the proposed methods improve the performance of online VOS models up to 10 %, and boosts their robustness on long-video datasets while maintaining comparable performance on short-video datasets DAVIS16 and DAVIS17.
A Step Towards Worldwide Biodiversity Assessment: The BIOSCAN-1M Insect Dataset
Jul 19, 2023In an effort to catalog insect biodiversity, we propose a new large dataset of hand-labelled insect images, the BIOSCAN-Insect Dataset. Each record is taxonomically classified by an expert, and also has associated genetic information including raw nucleotide barcode sequences and assigned barcode index numbers, which are genetically-based proxies for species classification. This paper presents a curated million-image dataset, primarily to train computer-vision models capable of providing image-based taxonomic assessment, however, the dataset also presents compelling characteristics, the study of which would be of interest to the broader machine learning community. Driven by the biological nature inherent to the dataset, a characteristic long-tailed class-imbalance distribution is exhibited. Furthermore, taxonomic labelling is a hierarchical classification scheme, presenting a highly fine-grained classification problem at lower levels. Beyond spurring interest in biodiversity research within the machine learning community, progress on creating an image-based taxonomic classifier will also further the ultimate goal of all BIOSCAN research: to lay the foundation for a comprehensive survey of global biodiversity. This paper introduces the dataset and explores the classification task through the implementation and analysis of a baseline classifier.
Self-supervised learning of object pose estimation using keypoint prediction
Feb 19, 2023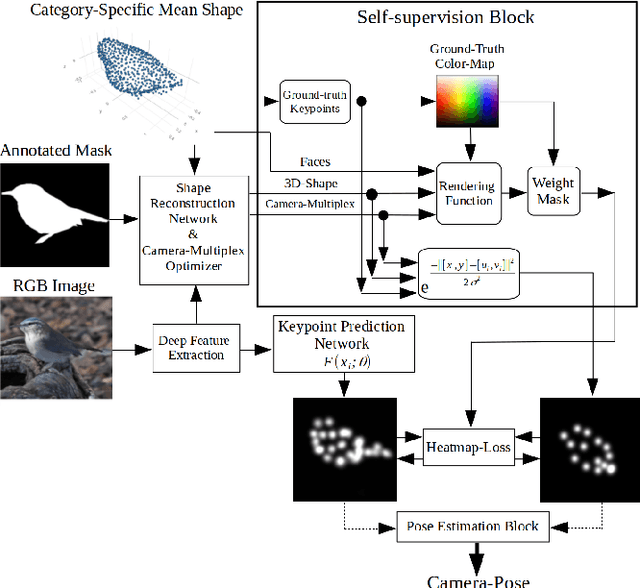



This paper describes recent developments in object specific pose and shape prediction from single images. The main contribution is a new approach to camera pose prediction by self-supervised learning of keypoints corresponding to locations on a category specific deformable shape. We designed a network to generate a proxy ground-truth heatmap from a set of keypoints distributed all over the category-specific mean shape, where each is represented by a unique color on a labeled texture. The proxy ground-truth heatmap is used to train a deep keypoint prediction network, which can be used in online inference. The proposed approach to camera pose prediction show significant improvements when compared with state-of-the-art methods. Our approach to camera pose prediction is used to infer 3D objects from 2D image frames of video sequences online. To train the reconstruction model, it receives only a silhouette mask from a single frame of a video sequence in every training step and a category-specific mean object shape. We conducted experiments using three different datasets representing the bird category: the CUB [51] image dataset, YouTubeVos and the Davis video datasets. The network is trained on the CUB dataset and tested on all three datasets. The online experiments are demonstrated on YouTubeVos and Davis [56] video sequences using a network trained on the CUB training set.
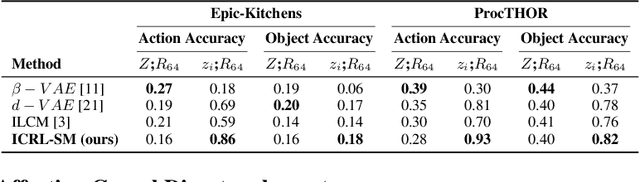
Generative Causal Representation Learning for Out-of-Distribution Motion Forecasting
Feb 17, 2023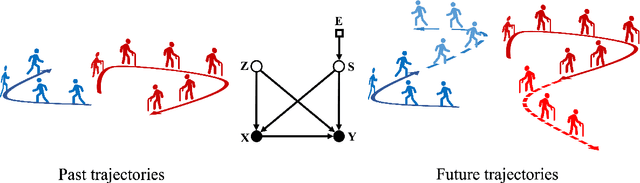
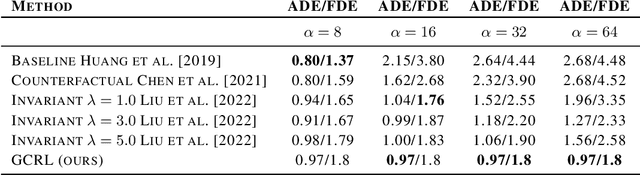
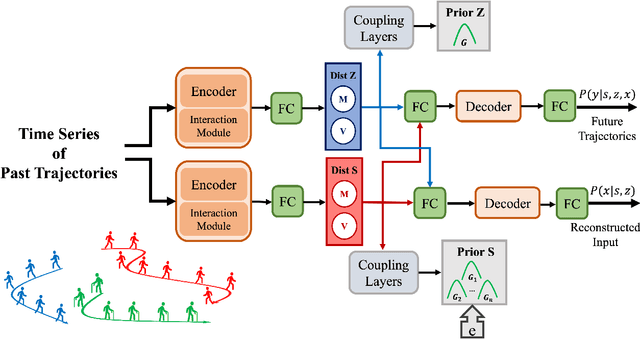

Conventional supervised learning methods typically assume i.i.d samples and are found to be sensitive to out-of-distribution (OOD) data. We propose Generative Causal Representation Learning (GCRL) which leverages causality to facilitate knowledge transfer under distribution shifts. While we evaluate the effectiveness of our proposed method in human trajectory prediction models, GCRL can be applied to other domains as well. First, we propose a novel causal model that explains the generative factors in motion forecasting datasets using features that are common across all environments and with features that are specific to each environment. Selection variables are used to determine which parts of the model can be directly transferred to a new environment without fine-tuning. Second, we propose an end-to-end variational learning paradigm to learn the causal mechanisms that generate observations from features. GCRL is supported by strong theoretical results that imply identifiability of the causal model under certain assumptions. Experimental results on synthetic and real-world motion forecasting datasets show the robustness and effectiveness of our proposed method for knowledge transfer under zero-shot and low-shot settings by substantially outperforming the prior motion forecasting models on out-of-distribution prediction.
Machine Learning Challenges of Biological Factors in Insect Image Data
Nov 04, 2022


The BIOSCAN project, led by the International Barcode of Life Consortium, seeks to study changes in biodiversity on a global scale. One component of the project is focused on studying the species interaction and dynamics of all insects. In addition to genetically barcoding insects, over 1.5 million images per year will be collected, each needing taxonomic classification. With the immense volume of incoming images, relying solely on expert taxonomists to label the images would be impossible; however, artificial intelligence and computer vision technology may offer a viable high-throughput solution. Additional tasks including manually weighing individual insects to determine biomass, remain tedious and costly. Here again, computer vision may offer an efficient and compelling alternative. While the use of computer vision methods is appealing for addressing these problems, significant challenges resulting from biological factors present themselves. These challenges are formulated in the context of machine learning in this paper.
Predicting the intended action using internal simulation of perception
Feb 09, 2022

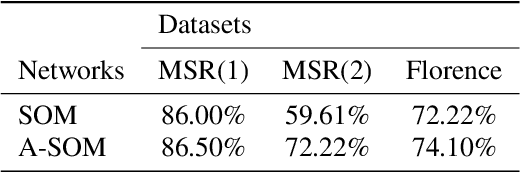

This article proposes an architecture, which allows the prediction of intention by internally simulating perceptual states represented by action pattern vectors. To this end, associative self-organising neural networks (A-SOM) is utilised to build a hierarchical cognitive architecture for recognition and simulation of the skeleton based human actions. The abilities of the proposed architecture in recognising and predicting actions is evaluated in experiments using three different datasets of 3D actions. Based on the experiments of this article, applying internally simulated perceptual states represented by action pattern vectors improves the performance of the recognition task in all experiments. Furthermore, internal simulation of perception addresses the problem of having limited access to the sensory input, and also the future prediction of the consecutive perceptual sequences. The performance of the system is compared and discussed with similar architecture using self-organizing neural networks (SOM).
Graph Representation Learning for Road Type Classification
Aug 19, 2021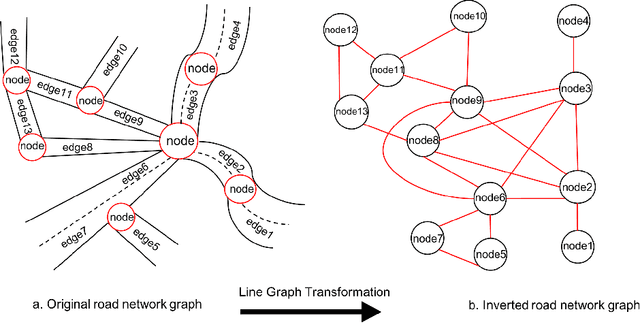
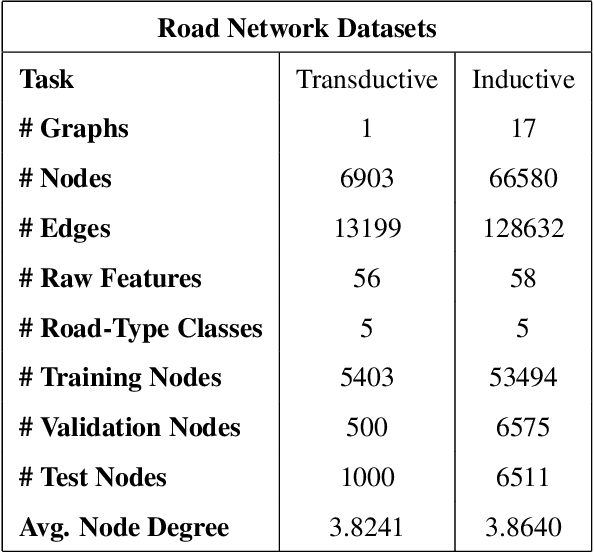
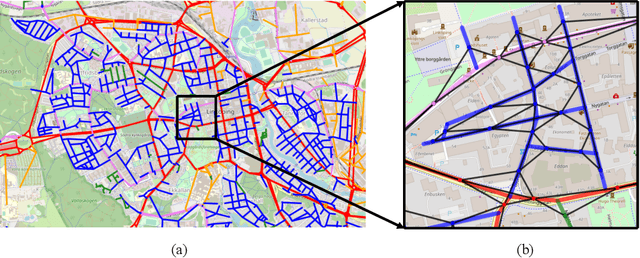
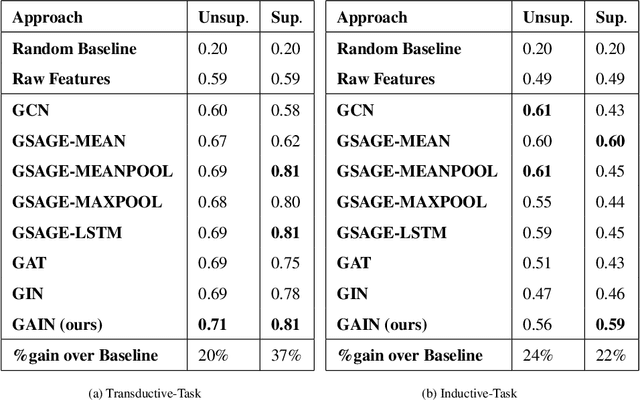
We present a novel learning-based approach to graph representations of road networks employing state-of-the-art graph convolutional neural networks. Our approach is applied to realistic road networks of 17 cities from Open Street Map. While edge features are crucial to generate descriptive graph representations of road networks, graph convolutional networks usually rely on node features only. We show that the highly representative edge features can still be integrated into such networks by applying a line graph transformation. We also propose a method for neighborhood sampling based on a topological neighborhood composed of both local and global neighbors. We compare the performance of learning representations using different types of neighborhood aggregation functions in transductive and inductive tasks and in supervised and unsupervised learning. Furthermore, we propose a novel aggregation approach, Graph Attention Isomorphism Network, GAIN. Our results show that GAIN outperforms state-of-the-art methods on the road type classification problem.