 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Relationship Detection Using Mixture of Experts
Paper and Code
Mar 06, 2024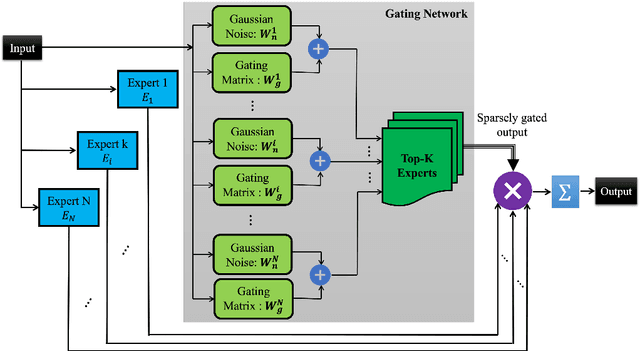
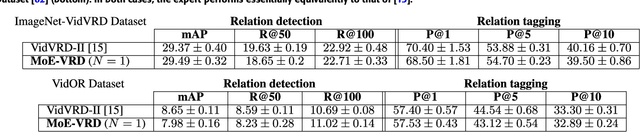
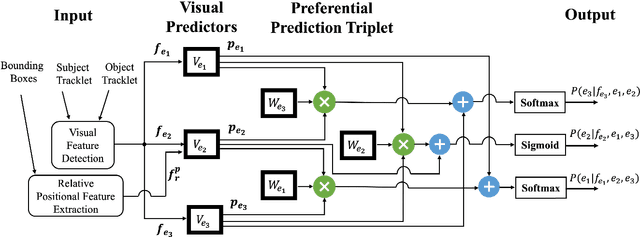
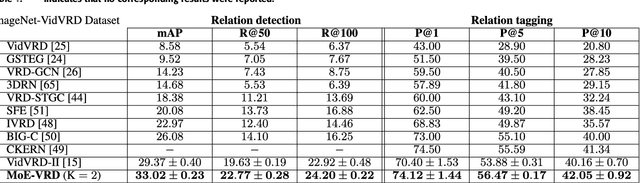
Machine comprehension of visual information from images and videos by neural networks faces two primary challenges. Firstly, there exists a computational and inference gap in connecting vision and language, making it difficult to accurately determine which object a given agent acts on and represent it through language. Secondly, classifiers trained by a single, monolithic neural network often lack stability and generalization. To overcome these challenges, we introduce MoE-VRD, a novel approach to visual relationship detection utilizing a mixture of experts. MoE-VRD identifies language triplets in the form of < subject, predicate, object> tuples to extract relationships from visual processing. Leveraging recent advancements in visual relationship detection, MoE-VRD addresses the requirement for action recognition in establishing relationships between subjects (acting) and objects (being acted upon). In contrast to single monolithic networks, MoE-VRD employs multiple small models as experts, whose outputs are aggregated. Each expert in MoE-VRD specializes in visual relationship learning and object tagging. By utilizing a sparsely-gated mixture of experts, MoE-VRD enables conditional computation and significantly enhances neural network capacity without increasing computational complexity. Our experimental results demonstrate that the conditional computation capabilities and scalability of the mixture-of-experts approach lead to superior performance in visual relationship detection compared to state-of-the-art methods.