 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Rotation Equivariance in Monocular 3D Human Pose Estimation
Jan 20, 2026Estimating 3D from 2D is one of the central tasks in computer vision. In this work, we consider the monocular setting, i.e. single-view input, for 3D human pose estimation (HPE). Here, the task is to predict a 3D point set of human skeletal joints from a single 2D input image. While by definition this is an ill-posed problem, recent work has presented methods that solve it with up to several-centimetre error. Typically, these methods employ a two-step approach, where the first step is to detect the 2D skeletal joints in the input image, followed by the step of 2D-to-3D lifting. We find that common lifting models fail when encountering a rotated input. We argue that learning a single human pose along with its in-plane rotations is considerably easier and more geometrically grounded than directly learning a point-to-point mapping. Furthermore, our intuition is that endowing the model with the notion of rotation equivariance without explicitly constraining its parameter space should lead to a more straightforward learning process than one with equivariance by design. Utilising the common HPE benchmarks, we confirm that the 2D rotation equivariance per se improves the model performance on human poses akin to rotations in the image plane, and can be efficiently and straightforwardly learned by augmentation, outperforming state-of-the-art equivariant-by-design methods.
Robust Multi-view Camera Calibration from Dense Matches
Dec 17, 2025



Estimating camera intrinsics and extrinsics is a fundamental problem in computer vision, and while advances in structure-from-motion (SfM) have improved accuracy and robustness, open challenges remain. In this paper, we introduce a robust method for pose estimation and calibration. We consider a set of rigid cameras, each observing the scene from a different perspective, which is a typical camera setup in animal behavior studies and forensic analysis of surveillance footage. Specifically, we analyse the individual components in a structure-from-motion (SfM) pipeline, and identify design choices that improve accuracy. Our main contributions are: (1) we investigate how to best subsample the predicted correspondences from a dense matcher to leverage them in the estimation process. (2) We investigate selection criteria for how to add the views incrementally. In a rigorous quantitative evaluation, we show the effectiveness of our changes, especially for cameras with strong radial distortion (79.9% ours vs. 40.4 vanilla VGGT). Finally, we demonstrate our correspondence subsampling in a global SfM setting where we initialize the poses using VGGT. The proposed pipeline generalizes across a wide range of camera setups, and could thus become a useful tool for animal behavior and forensic analysis.
MATTER: Multiscale Attention for Registration Error Regression
Sep 16, 2025

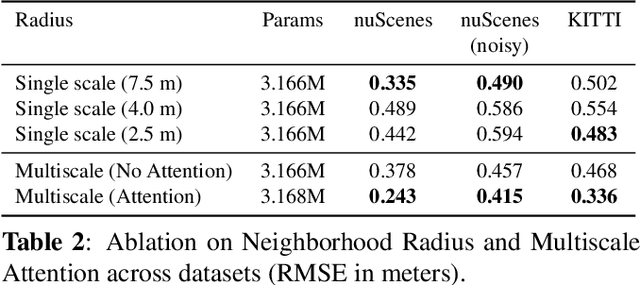

Point cloud registration (PCR) is crucial for many downstream tasks, such as simultaneous localization and mapping (SLAM) and object tracking. This makes detecting and quantifying registration misalignment, i.e.,~{\it PCR quality validation}, an important task. All existing methods treat validation as a classification task, aiming to assign the PCR quality to a few classes. In this work, we instead use regression for PCR validation, allowing for a more fine-grained quantification of the registration quality. We also extend previously used misalignment-related features by using multiscale extraction and attention-based aggregation. This leads to accurate and robust registration error estimation on diverse datasets, especially for point clouds with heterogeneous spatial densities. Furthermore, when used to guide a mapping downstream task, our method significantly improves the mapping quality for a given amount of re-registered frames, compared to the state-of-the-art classification-based method.
Continuous Normalizing Flows for Uncertainty-Aware Human Pose Estimation
May 04, 2025



Human Pose Estimation (HPE) is increasingly important for applications like virtual reality and motion analysis, yet current methods struggle with balancing accuracy, computational efficiency, and reliable uncertainty quantification (UQ). Traditional regression-based methods assume fixed distributions, which might lead to poor UQ. Heatmap-based methods effectively model the output distribution using likelihood heatmaps, however, they demand significant resources. To address this, we propose Continuous Flow Residual Estimation (CFRE), an integration of Continuous Normalizing Flows (CNFs) into regression-based models, which allows for dynamic distribution adaptation. Through extensive experiments, we show that CFRE leads to better accuracy and uncertainty quantification with retained computational efficiency on both 2D and 3D human pose estimation tasks.
FACT: Multinomial Misalignment Classification for Point Cloud Registration
Apr 09, 2025



We present FACT, a method for predicting alignment quality (i.e., registration error) of registered lidar point cloud pairs. This is useful e.g. for quality assurance of large, automatically registered 3D models. FACT extracts local features from a registered pair and processes them with a point transformer-based network to predict a misalignment class. We generalize prior work that study binary alignment classification of registration errors, by recasting it as multinomial misalignment classification. To achieve this, we introduce a custom regression-by-classification loss function that combines the cross-entropy and Wasserstein losses, and demonstrate that it outperforms both direct regression and prior binary classification. FACT successfully classifies point-cloud pairs registered with both the classical ICP and GeoTransformer, while other choices, such as standard point-cloud-quality metrics and registration residuals are shown to be poor choices for predicting misalignment. On a synthetically perturbed point-cloud task introduced by the CorAl method, we show that FACT achieves substantially better performance than CorAl. Finally, we demonstrate how FACT can assist experts in correcting misaligned point-cloud maps. Our code is available at https://github.com/LudvigDillen/FACT_for_PCMC.
Uncertainty Quantification Metrics for Deep Regression
May 07, 2024



When deploying deep neural networks on robots or other physical systems, the learned model should reliably quantify predictive uncertainty. A reliable uncertainty allows downstream modules to reason about the safety of its actions. In this work, we address metrics for evaluating such an uncertainty. Specifically, we focus on regression tasks, and investigate Area Under Sparsification Error (AUSE), Calibration Error, Spearman's Rank Correlation, and Negative Log-Likelihood (NLL). Using synthetic regression datasets, we look into how those metrics behave under four typical types of uncertainty, their stability regarding the size of the test set, and reveal their strengths and weaknesses. Our results indicate that Calibration Error is the most stable and interpretable metric, but AUSE and NLL also have their respective use cases. We discourage the usage of Spearman's Rank Correlation for evaluating uncertainties and recommend replacing it with AUSE.
GMSF: Global Matching Scene Flow
May 27, 2023We tackle the task of scene flow estimation from point clouds. Given a source and a target point cloud, the objective is to estimate a translation from each point in the source point cloud to the target, resulting in a 3D motion vector field. Previous dominant scene flow estimation methods require complicated coarse-to-fine or recurrent architectures as a multi-stage refinement. In contrast, we propose a significantly simpler single-scale one-shot global matching to address the problem. Our key finding is that reliable feature similarity between point pairs is essential and sufficient to estimate accurate scene flow. To this end, we propose to decompose the feature extraction step via a hybrid local-global-cross transformer architecture which is crucial to accurate and robust feature representations. Extensive experiments show that GMSF sets a new state-of-the-art on multiple scene flow estimation benchmarks. On FlyingThings3D, with the presence of occlusion points, GMSF reduces the outlier percentage from the previous best performance of 27.4% to 11.7%. On KITTI Scene Flow, without any fine-tuning, our proposed method shows state-of-the-art performance.
Self-supervised learning of object pose estimation using keypoint prediction
Feb 19, 2023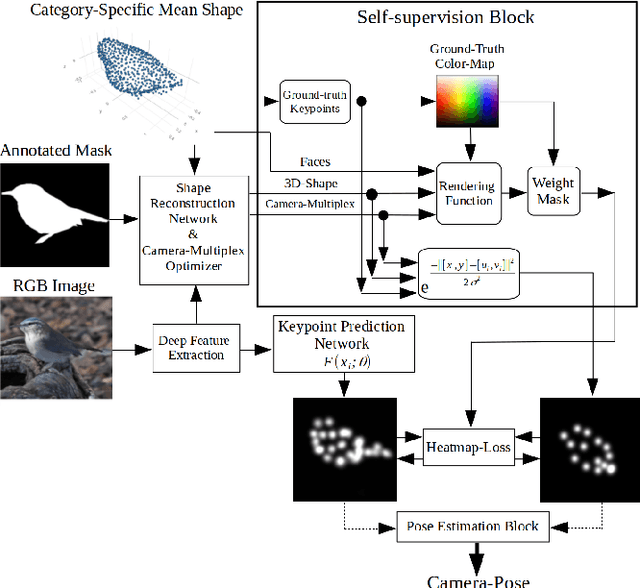



This paper describes recent developments in object specific pose and shape prediction from single images. The main contribution is a new approach to camera pose prediction by self-supervised learning of keypoints corresponding to locations on a category specific deformable shape. We designed a network to generate a proxy ground-truth heatmap from a set of keypoints distributed all over the category-specific mean shape, where each is represented by a unique color on a labeled texture. The proxy ground-truth heatmap is used to train a deep keypoint prediction network, which can be used in online inference. The proposed approach to camera pose prediction show significant improvements when compared with state-of-the-art methods. Our approach to camera pose prediction is used to infer 3D objects from 2D image frames of video sequences online. To train the reconstruction model, it receives only a silhouette mask from a single frame of a video sequence in every training step and a category-specific mean object shape. We conducted experiments using three different datasets representing the bird category: the CUB [51] image dataset, YouTubeVos and the Davis video datasets. The network is trained on the CUB dataset and tested on all three datasets. The online experiments are demonstrated on YouTubeVos and Davis [56] video sequences using a network trained on the CUB training set.
Camera Calibration without Camera Access -- A Robust Validation Technique for Extended PnP Methods
Feb 14, 2023A challenge in image based metrology and forensics is intrinsic camera calibration when the used camera is unavailable. The unavailability raises two questions. The first question is how to find the projection model that describes the camera, and the second is to detect incorrect models. In this work, we use off-the-shelf extended PnP-methods to find the model from 2D-3D correspondences, and propose a method for model validation. The most common strategy for evaluating a projection model is comparing different models' residual variances - however, this naive strategy cannot distinguish whether the projection model is potentially underfitted or overfitted. To this end, we model the residual errors for each correspondence, individually scale all residuals using a predicted variance and test if the new residuals are drawn from a standard normal distribution. We demonstrate the effectiveness of our proposed validation in experiments on synthetic data, simulating 2D detection and Lidar measurements. Additionally, we provide experiments using data from an actual scene and compare non-camera access and camera access calibrations. Last, we use our method to validate annotations in MegaDepth.
Registration Loss Learning for Deep Probabilistic Point Set Registration
Nov 04, 2020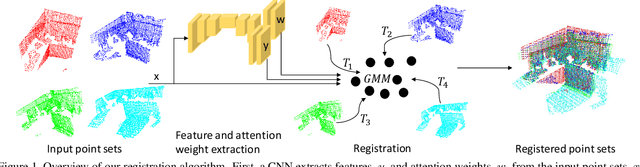
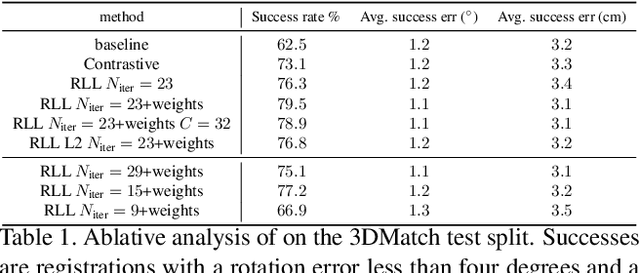
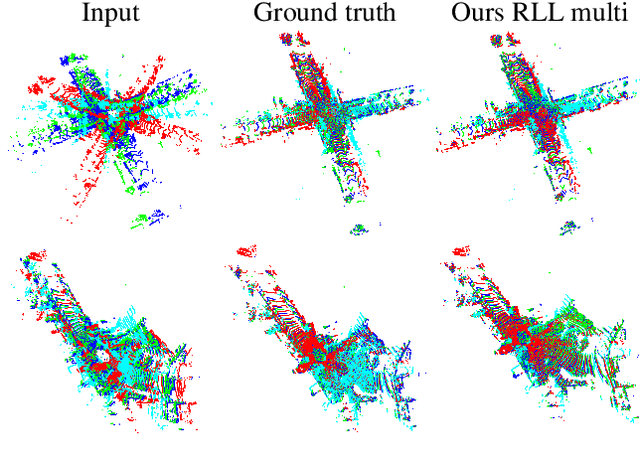
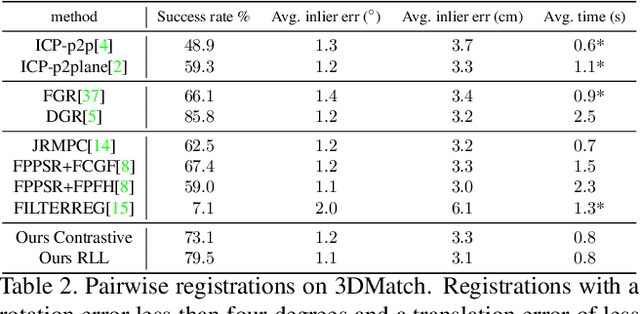
Probabilistic methods for point set registration have interesting theoretical properties, such as linear complexity in the number of used points, and they easily generalize to joint registration of multiple point sets. In this work, we improve their recognition performance to match state of the art. This is done by incorporating learned features, by adding a von Mises-Fisher feature model in each mixture component, and by using learned attention weights. We learn these jointly using a registration loss learning strategy (RLL) that directly uses the registration error as a loss, by back-propagating through the registration iterations. This is possible as the probabilistic registration is fully differentiable, and the result is a learning framework that is truly end-to-end. We perform extensive experiments on the 3DMatch and Kitti datasets. The experiments demonstrate that our approach benefits significantly from the integration of the learned features and our learning strategy, outperforming the state-of-the-art on Kitti. Code is available at https://github.com/felja633/RLLReg.