 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Calibration without Camera Access -- A Robust Validation Technique for Extended PnP Methods
Feb 14, 2023A challenge in image based metrology and forensics is intrinsic camera calibration when the used camera is unavailable. The unavailability raises two questions. The first question is how to find the projection model that describes the camera, and the second is to detect incorrect models. In this work, we use off-the-shelf extended PnP-methods to find the model from 2D-3D correspondences, and propose a method for model validation. The most common strategy for evaluating a projection model is comparing different models' residual variances - however, this naive strategy cannot distinguish whether the projection model is potentially underfitted or overfitted. To this end, we model the residual errors for each correspondence, individually scale all residuals using a predicted variance and test if the new residuals are drawn from a standard normal distribution. We demonstrate the effectiveness of our proposed validation in experiments on synthetic data, simulating 2D detection and Lidar measurements. Additionally, we provide experiments using data from an actual scene and compare non-camera access and camera access calibrations. Last, we use our method to validate annotations in MegaDepth.
Learning Video Instance Segmentation with Recurrent Graph Neural Networks
Dec 07, 2020

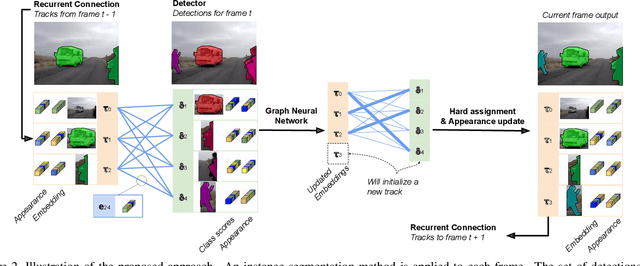
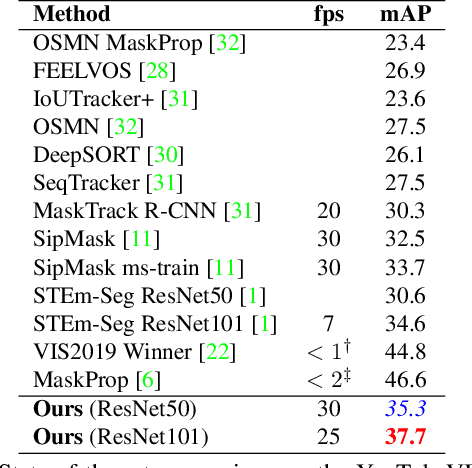
Most existing approaches to video instance segmentation comprise multiple modules that are heuristically combined to produce the final output. Formulating a purely learning-based method instead, which models both the temporal aspect as well as a generic track management required to solve the video instance segmentation task, is a highly challenging problem. In this work, we propose a novel learning formulation, where the entire video instance segmentation problem is modelled jointly. We fit a flexible model to our formulation that, with the help of a graph neural network, processes all available new information in each frame. Past information is considered and processed via a recurrent connection. We demonstrate the effectiveness of the proposed approach in comprehensive experiments. Our approach, operating at over 25 FPS, outperforms previous video real-time methods. We further conduct detailed ablative experiments that validate the different aspects of our approach.
A Generative Appearance Model for End-to-end Video Object Segmentation
Dec 07, 2018
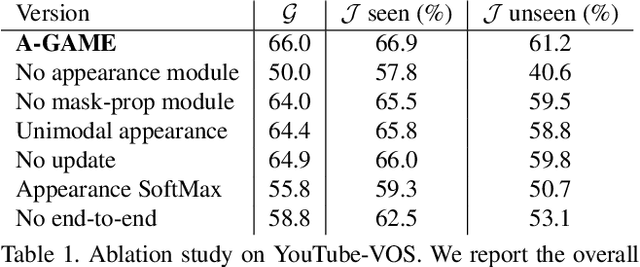
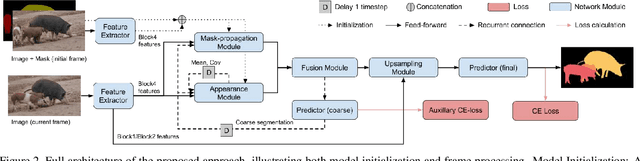
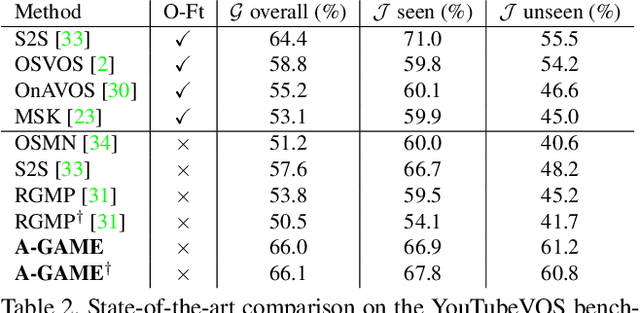
One of the fundamental challenges in video object segmentation is to find an effective representation of the target and background appearance. The best performing approaches resort to extensive fine-tuning of a convolutional neural network for this purpose. Besides being prohibitively expensive, this strategy cannot be truly trained end-to-end since the online fine-tuning procedure is not integrated into the offline training of the network. To address these issues, we propose a network architecture that learns a powerful representation of the target and background appearance in a single forward pass. The introduced appearance module learns a probabilistic generative model of target and background feature distributions. Given a new image, it predicts the posterior class probabilities, providing a highly discriminative cue, which is processed in later network modules. Both the learning and prediction stages of our appearance module are fully differentiable, enabling true end-to-end training of the entire segmentation pipeline. Comprehensive experiments demonstrate the effectiveness of the proposed approach on three video object segmentation benchmarks. We close the gap to approaches based on online fine-tuning on DAVIS17, while operating at 15 FPS on a single GPU. Furthermore, our method outperforms all published approaches on the large-scale YouTube-VOS dataset.