 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATPlan: Loss-based Collision Prediction in End-to-End Autonomous Driving
Mar 10, 2025
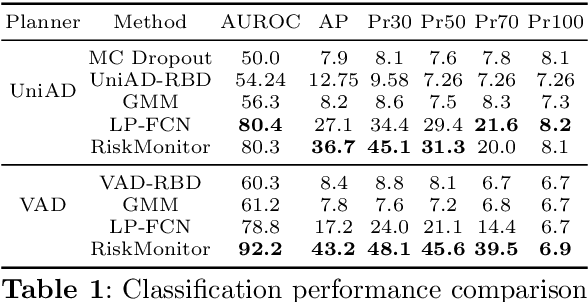


In recent years, there has been increased interest in the design, training, and evaluation of end-to-end autonomous driving (AD) systems. One often overlooked aspect is the uncertainty of planned trajectories predicted by these systems, despite awareness of their own uncertainty being key to achieve safety and robustness. We propose to estimate this uncertainty by adapting loss prediction from the uncertainty quantification literature. To this end, we introduce a novel light-weight module, dubbed CATPlan, that is trained to decode motion and planning embeddings into estimates of the collision loss used to partially supervise end-to-end AD systems. During inference, these estimates are interpreted as collision risk. We evaluate CATPlan on the safety-critical, nerf-based, closed-loop benchmark NeuroNCAP and find that it manages to detect collisions with a $54.8\%$ relative improvement to average precision over a GMM-based baseline in which the predicted trajectory is compared to the forecasted trajectories of other road users. Our findings indicate that the addition of CATPlan can lead to safer end-to-end AD systems and hope that our work will spark increased interest in uncertainty quantification for such systems.
NeuroNCAP: Photorealistic Closed-loop Safety Testing for Autonomous Driving
Apr 12, 2024



We present a versatile NeRF-based simulator for testing autonomous driving (AD) software systems, designed with a focus on sensor-realistic closed-loop evaluation and the creation of safety-critical scenarios. The simulator learns from sequences of real-world driving sensor data and enables reconfigurations and renderings of new, unseen scenarios. In this work, we use our simulator to test the responses of AD models to safety-critical scenarios inspired by the European New Car Assessment Programme (Euro NCAP). Our evaluation reveals that, while state-of-the-art end-to-end planners excel in nominal driving scenarios in an open-loop setting, they exhibit critical flaws when navigating our safety-critical scenarios in a closed-loop setting. This highlights the need for advancements in the safety and real-world usability of end-to-end planners. By publicly releasing our simulator and scenarios as an easy-to-run evaluation suite, we invite the research community to explore, refine, and validate their AD models in controlled, yet highly configurable and challenging sensor-realistic environments. Code and instructions can be found at https://github.com/wljungbergh/NeuroNCAP
You can have your ensemble and run it too -- Deep Ensembles Spread Over Time
Sep 20, 2023Ensembles of independently trained deep neural networks yield uncertainty estimates that rival Bayesian networks in performance. They also offer sizable improvements in terms of predictive performance over single models. However, deep ensembles are not commonly used in environments with limited computational budget -- such as autonomous driving -- since the complexity grows linearly with the number of ensemble members. An important observation that can be made for robotics applications, such as autonomous driving, is that data is typically sequential. For instance, when an object is to be recognized, an autonomous vehicle typically observes a sequence of images, rather than a single image. This raises the question, could the deep ensemble be spread over time? In this work, we propose and analyze Deep Ensembles Spread Over Time (DESOT). The idea is to apply only a single ensemble member to each data point in the sequence, and fuse the predictions over a sequence of data points. We implement and experiment with DESOT for traffic sign classification, where sequences of tracked image patches are to be classified. We find that DESOT obtains the benefits of deep ensembles, in terms of predictive and uncertainty estimation performance, while avoiding the added computational cost. Moreover, DESOT is simple to implement and does not require sequences during training. Finally, we find that DESOT, like deep ensembles, outperform single models for out-of-distribution detection.
Hinge-Wasserstein: Mitigating Overconfidence in Regression by Classification
Jun 01, 2023



Modern deep neural networks are prone to being overconfident despite their drastically improved performance. In ambiguous or even unpredictable real-world scenarios, this overconfidence can pose a major risk to the safety of applications. For regression tasks, the regression-by-classification approach has the potential to alleviate these ambiguities by instead predicting a discrete probability density over the desired output. However, a density estimator still tends to be overconfident when trained with the common NLL loss. To mitigate the overconfidence problem, we propose a loss function, hinge-Wasserstein, based on the Wasserstein Distance. This loss significantly improves the quality of both aleatoric and epistemic uncertainty, compared to previous work. We demonstrate the capabilities of the new loss on a synthetic dataset, where both types of uncertainty are controlled separately. Moreover, as a demonstration for real-world scenarios, we evaluate our approach on the benchmark dataset Horizon Lines in the Wild. On this benchmark, using the hinge-Wasserstein loss reduces the Area Under Sparsification Error (AUSE) for horizon parameters slope and offset, by 30.47% and 65.00%, respectively.
Raw or Cooked? Object Detection on RAW Images
Jan 21, 2023Images fed to a deep neural network have in general undergone several handcrafted image signal processing (ISP) operations, all of which have been optimized to produce visually pleasing images. In this work, we investigate the hypothesis that the intermediate representation of visually pleasing images is sub-optimal for downstream computer vision tasks compared to the RAW image representation. We suggest that the operations of the ISP instead should be optimized towards the end task, by learning the parameters of the operations jointly during training. We extend previous works on this topic and propose a new learnable operation that enables an object detector to achieve superior performance when compared to both previous works and traditional RGB images. In experiments on the open PASCALRAW dataset, we empirically confirm our hypothesis.
Towards Explainable Motion Prediction using Heterogeneous Graph Representations
Dec 07, 2022Motion prediction systems aim to capture the future behavior of traffic scenarios enabling autonomous vehicles to perform safe and efficient planning. The evolution of these scenarios is highly uncertain and depends on the interactions of agents with static and dynamic objects in the scene. GNN-based approaches have recently gained attention as they are well suited to naturally model these interactions. However, one of the main challenges that remains unexplored is how to address the complexity and opacity of these models in order to deal with the transparency requirements for autonomous driving systems, which includes aspects such as interpretability and explainability. In this work, we aim to improve the explainability of motion prediction systems by using different approaches. First, we propose a new Explainable Heterogeneous Graph-based Policy (XHGP) model based on an heterograph representation of the traffic scene and lane-graph traversals, which learns interaction behaviors using object-level and type-level attention. This learned attention provides information about the most important agents and interactions in the scene. Second, we explore this same idea with the explanations provided by GNNExplainer. Third, we apply counterfactual reasoning to provide explanations of selected individual scenarios by exploring the sensitivity of the trained model to changes made to the input data, i.e., masking some elements of the scene, modifying trajectories, and adding or removing dynamic agents. The explainability analysis provided in this paper is a first step towards more transparent and reliable motion prediction systems, important from the perspective of the user, developers and regulatory agencies. The code to reproduce this work is publicly available at https://github.com/sancarlim/Explainable-MP/tree/v1.1.
Towards Trustworthy Multi-Modal Motion Prediction: Evaluation and Interpretability
Oct 28, 2022



Predicting the motion of other road agents enables autonomous vehicles to perform safe and efficient path planning. This task is very complex, as the behaviour of road agents depends on many factors and the number of possible future trajectories can be considerable (multi-modal). Most approaches proposed to address multi-modal motion prediction are based on complex machine learning systems that have limited interpretability. Moreover, the metrics used in current benchmarks do not evaluate all aspects of the problem, such as the diversity and admissibility of the output. In this work, we aim to advance towards the design of trustworthy motion prediction systems, based on some of the requirements for the design of Trustworthy Artificial Intelligence. We focus on evaluation criteria, robustness, and interpretability of outputs. First, we comprehensively analyse the evaluation metrics, identify the main gaps of current benchmarks, and propose a new holistic evaluation framework. In addition, we formulate a method for the assessment of spatial and temporal robustness by simulating noise in the perception system. We propose an intent prediction layer that can be attached to multi-modal motion prediction models to enhance the interpretability of the outputs and generate more balanced results in the proposed evaluation framework. Finally, the interpretability of the outputs is assessed by means of a survey that explores different elements in the visualization of the multi-modal trajectories and intentions.
Learning Future Object Prediction with a Spatiotemporal Detection Transformer
Apr 21, 2022
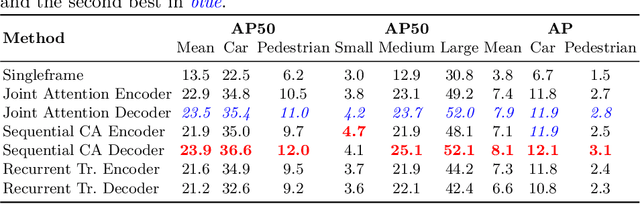
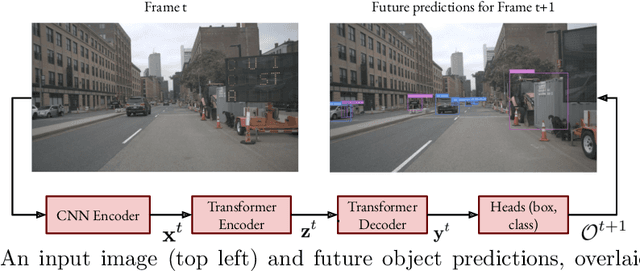
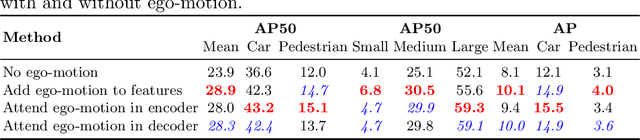
We explore future object prediction -- a challenging problem where all objects visible in a future video frame are to be predicted. We propose to tackle this problem end-to-end by training a detection transformer to directly output future objects. In order to make accurate predictions about the future, it is necessary to capture the dynamics in the scene, both of other objects and of the ego-camera. We extend existing detection transformers in two ways to capture the scene dynamics. First, we experiment with three different mechanisms that enable the model to spatiotemporally process multiple frames. Second, we feed ego-motion information to the model via cross-attention. We show that both of these cues substantially improve future object prediction performance. Our final approach learns to capture the dynamics and make predictions on par with an oracle for 100 ms prediction horizons, and outperform baselines for longer prediction horizons.
Dense Gaussian Processes for Few-Shot Segmentation
Oct 07, 2021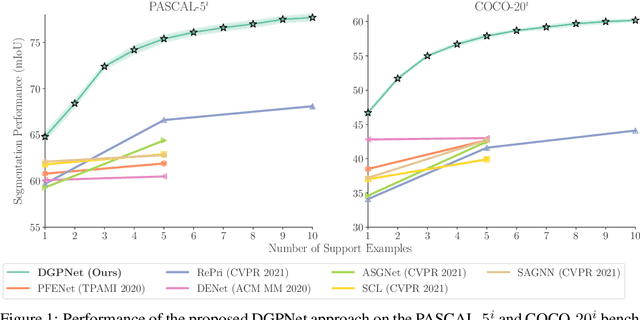
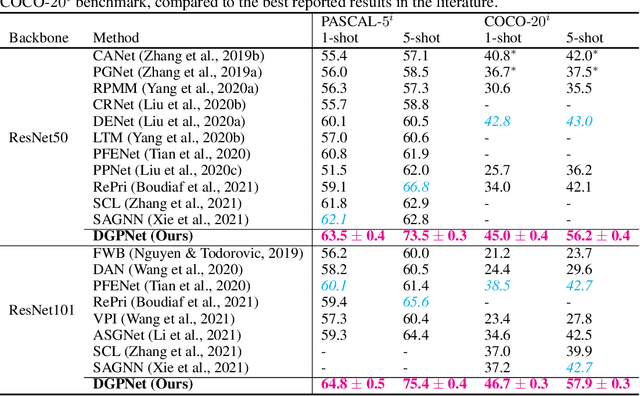
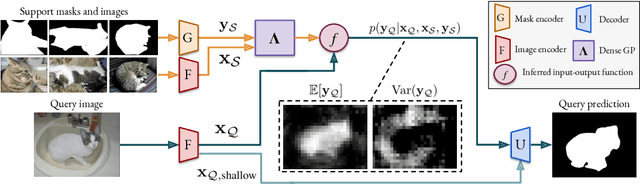

Few-shot segmentation is a challenging dense prediction task, which entails segmenting a novel query image given only a small annotated support set. The key problem is thus to design a method that aggregates detailed information from the support set, while being robust to large variations in appearance and context. To this end, we propose a few-shot segmentation method based on dense Gaussian process (GP) regression. Given the support set, our dense GP learns the mapping from local deep image features to mask values, capable of capturing complex appearance distributions. Furthermore, it provides a principled means of capturing uncertainty, which serves as another powerful cue for the final segmentation, obtained by a CNN decoder. Instead of a one-dimensional mask output, we further exploit the end-to-end learning capabilities of our approach to learn a high-dimensional output space for the GP. Our approach sets a new state-of-the-art for both 1-shot and 5-shot FSS on the PASCAL-5$^i$ and COCO-20$^i$ benchmarks, achieving an absolute gain of $+14.9$ mIoU in the COCO-20$^i$ 5-shot setting. Furthermore, the segmentation quality of our approach scales gracefully when increasing the support set size, while achieving robust cross-dataset transfer.
Deep Gaussian Processes for Few-Shot Segmentation
Mar 30, 2021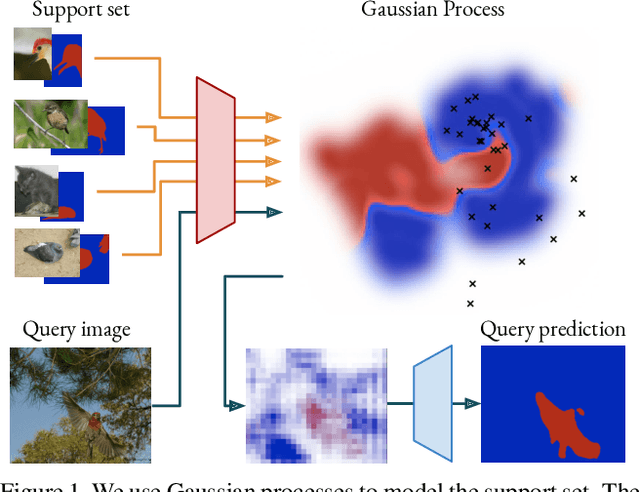
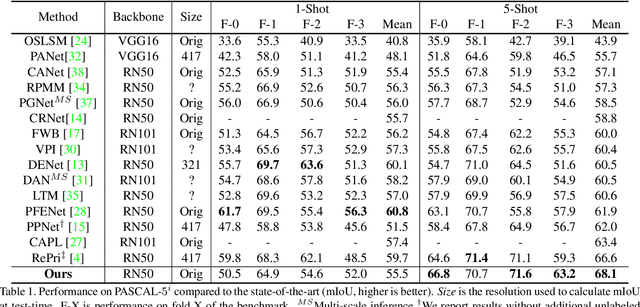
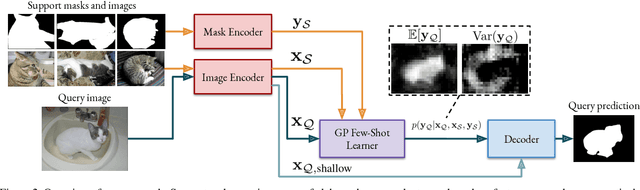
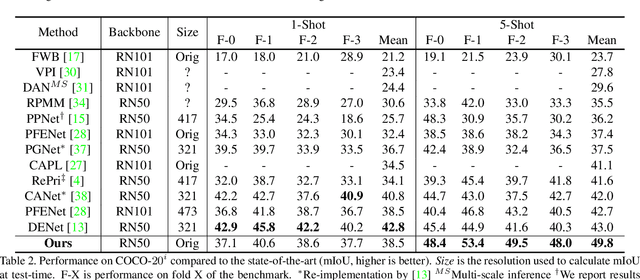
Few-shot segmentation is a challenging task, requiring the extraction of a generalizable representation from only a few annotated samples, in order to segment novel query images. A common approach is to model each class with a single prototype. While conceptually simple, these methods suffer when the target appearance distribution is multi-modal or not linearly separable in feature space. To tackle this issue, we propose a few-shot learner formulation based on Gaussian process (GP) regression. Through the expressivity of the GP, our approach is capable of modeling complex appearance distributions in the deep feature space. The GP provides a principled way of capturing uncertainty, which serves as another powerful cue for the final segmentation, obtained by a CNN decoder. We further exploit the end-to-end learning capabilities of our approach to learn the output space of the GP learner, ensuring a richer encoding of the segmentation mask. We perform comprehensive experimental analysis of our few-shot learner formulation. Our approach sets a new state-of-the-art for 5-shot segmentation, with mIoU scores of 68.1 and 49.8 on PASCAL-5i and COCO-20i, respectively