 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegged Autonomous Surface Science In Analogue Environments (LASSIE): Making Every Robotic Step Count in Planetary Exploration
Mar 20, 2026The ability to efficiently and effectively explore planetary surfaces is currently limited by the capability of wheeled rovers to traverse challenging terrains, and by pre-programmed data acquisition plans with limited in-situ flexibility. In this paper, we present two novel approaches to address these limitations: (i) high-mobility legged robots that use direct surface interactions to collect rich information about the terrain's mechanics to guide exploration; (ii) human-inspired data acquisition algorithms that enable robots to reason about scientific hypotheses and adapt exploration priorities based on incoming ground-sensing measurements. We successfully verify our approach through lab work and field deployments in two planetary analog environments. The new capability for legged robots to measure soil mechanical properties is shown to enable effective traversal of challenging terrains. When coupled with other geologic properties (e.g., composition, thermal properties, and grain size data etc), soil mechanical measurements reveal key factors governing the formation and development of geologic environments. We then demonstrate how human-inspired algorithms turn terrain-sensing robots into teammates, by supporting more flexible and adaptive data collection decisions with human scientists. Our approach therefore enables exploration of a wider range of planetary environments and new substrate investigation opportunities through integrated human-robot systems that support maximum scientific return.
Proprioceptive Safe Active Navigation and Exploration for Planetary Environments
Mar 09, 2026Deformable granular terrains introduce significant locomotion and immobilization risks in planetary exploration and are difficult to detect via remote sensing (e.g., vision). Legged robots can sense terrain properties through leg-terrain interactions during locomotion, offering a direct means to assess traversability in deformable environments. How to systematically exploit this interaction-derived information for navigation planning, however, remains underexplored. We address this gap by presenting PSANE, a Proprioceptive Safe Active Navigation and Exploration framework that leverages leg-terrain interaction measurements for safe navigation and exploration in unknown deformable environments. PSANE learns a traversability model via Gaussian Process regression to estimate and certify safe regions and identify exploration frontiers online, and integrates these estimates with a reactive controller for real-time navigation. Frontier selection is formulated as a multi-objective optimization that balances safe-set expansion probability and goal-directed cost, with subgoals selected via scalarization over the Pareto-optimal frontier set. PSANE safely explores unknown granular terrain and reaches specified goals using only proprioceptively estimated traversability, while achieving performance improvements over baseline methods.
Inverse Resistive Force Theory (I-RFT): Learning granular properties through robot-terrain physical interactions
Mar 08, 2026For robots to navigate safely and efficiently on soft, granular terrains, it is crucial to gather information about the terrain's mechanical properties, which directly affect locomotion performance. Recent research has developed robotic legs that can accurately sense ground reaction forces during locomotion. However, existing tests of granular property estimation often rely on specific foot trajectories, such as vertical penetration or horizontal shear, limiting their applicability during natural locomotion. To address this limitation, we introduce a physics-informed machine learning framework, Inverse Resistive Force Theory (I-RFT), which integrates the Granular Resistive Force Theory model with Gaussian Processes to infer terrain properties from proprioceptively measured contact forces under arbitrary gait trajectories. By embedding the granular force model within the learning process, I-RFT preserves physical consistency while enabling generalization across diverse motion primitives. Experimental results demonstrate that I-RFT accurately estimates terrain properties across multiple gait trajectories and toe shapes. Moreover, we show that the quantified uncertainty over the terrain resistance stress map could enable robots to optimize foot design and gait trajectories for efficient information gathering. This approach establishes a new foundation for data-efficient characterization of complex granular environments and opens new avenues for locomotion strategies that actively adapt gait for autonomous terrain exploration.
Safe Active Navigation and Exploration for Planetary Environments Using Proprioceptive Measurements
Oct 21, 2025Legged robots can sense terrain through force interactions during locomotion, offering more reliable traversability estimates than remote sensing and serving as scouts for guiding wheeled rovers in challenging environments. However, even legged scouts face challenges when traversing highly deformable or unstable terrain. We present Safe Active Exploration for Granular Terrain (SAEGT), a navigation framework that enables legged robots to safely explore unknown granular environments using proprioceptive sensing, particularly where visual input fails to capture terrain deformability. SAEGT estimates the safe region and frontier region online from leg-terrain interactions using Gaussian Process regression for traversability assessment, with a reactive controller for real-time safe exploration and navigation. SAEGT demonstrated its ability to safely explore and navigate toward a specified goal using only proprioceptively estimated traversability in simulation.
MATTER: Multiscale Attention for Registration Error Regression
Sep 16, 2025

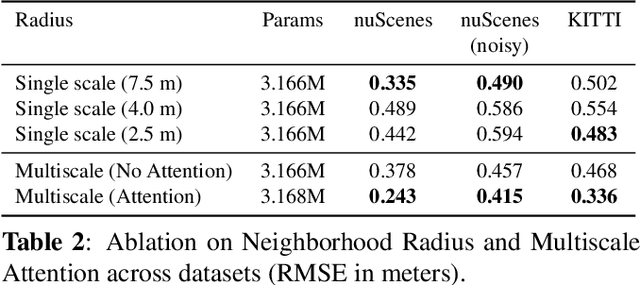

Point cloud registration (PCR) is crucial for many downstream tasks, such as simultaneous localization and mapping (SLAM) and object tracking. This makes detecting and quantifying registration misalignment, i.e.,~{\it PCR quality validation}, an important task. All existing methods treat validation as a classification task, aiming to assign the PCR quality to a few classes. In this work, we instead use regression for PCR validation, allowing for a more fine-grained quantification of the registration quality. We also extend previously used misalignment-related features by using multiscale extraction and attention-based aggregation. This leads to accurate and robust registration error estimation on diverse datasets, especially for point clouds with heterogeneous spatial densities. Furthermore, when used to guide a mapping downstream task, our method significantly improves the mapping quality for a given amount of re-registered frames, compared to the state-of-the-art classification-based method.
Bio-inspired tail oscillation enables robot fast crawling on deformable granular terrains
Sep 15, 2025



Deformable substrates such as sand and mud present significant challenges for terrestrial robots due to complex robot-terrain interactions. Inspired by mudskippers, amphibious animals that naturally adjust their tail morphology and movement jointly to navigate such environments, we investigate how tail design and control can jointly enhance flipper-driven locomotion on granular media. Using a bio-inspired robot modeled after the mudskipper, we experimentally compared locomotion performance between idle and actively oscillating tail configurations. Tail oscillation increased robot speed by 67% and reduced body drag by 46%. Shear force measurements revealed that this improvement was enabled by tail oscillation fluidizing the substrate, thereby reducing resistance. Additionally, tail morphology strongly influenced the oscillation strategy: designs with larger horizontal surface areas leveraged the oscillation-reduced shear resistance more effectively by limiting insertion depth. Based on these findings, we present a design principle to inform tail action selection based on substrate strength and tail morphology. Our results offer new insights into tail design and control for improving robot locomotion on deformable substrates, with implications for agricultural robotics, search and rescue, and environmental exploration.
Continuous Normalizing Flows for Uncertainty-Aware Human Pose Estimation
May 04, 2025



Human Pose Estimation (HPE) is increasingly important for applications like virtual reality and motion analysis, yet current methods struggle with balancing accuracy, computational efficiency, and reliable uncertainty quantification (UQ). Traditional regression-based methods assume fixed distributions, which might lead to poor UQ. Heatmap-based methods effectively model the output distribution using likelihood heatmaps, however, they demand significant resources. To address this, we propose Continuous Flow Residual Estimation (CFRE), an integration of Continuous Normalizing Flows (CNFs) into regression-based models, which allows for dynamic distribution adaptation. Through extensive experiments, we show that CFRE leads to better accuracy and uncertainty quantification with retained computational efficiency on both 2D and 3D human pose estimation tasks.
Adaptive Locomotion on Mud through Proprioceptive Sensing of Substrate Properties
Apr 28, 2025Muddy terrains present significant challenges for terrestrial robots, as subtle changes in composition and water content can lead to large variations in substrate strength and force responses, causing the robot to slip or get stuck. This paper presents a method to estimate mud properties using proprioceptive sensing, enabling a flipper-driven robot to adapt its locomotion through muddy substrates of varying strength. First, we characterize mud reaction forces through actuator current and position signals from a statically mounted robotic flipper. We use the measured force to determine key coefficients that characterize intrinsic mud properties. The proprioceptively estimated coefficients match closely with measurements from a lab-grade load cell, validating the effectiveness of the proposed method. Next, we extend the method to a locomoting robot to estimate mud properties online as it crawls across different mud mixtures. Experimental data reveal that mud reaction forces depend sensitively on robot motion, requiring joint analysis of robot movement with proprioceptive force to determine mud properties correctly. Lastly, we deploy this method in a flipper-driven robot moving across muddy substrates of varying strengths, and demonstrate that the proposed method allows the robot to use the estimated mud properties to adapt its locomotion strategy, and successfully avoid locomotion failures. Our findings highlight the potential of proprioception-based terrain sensing to enhance robot mobility in complex, deformable natural environments, paving the way for more robust field exploration capabilities.
CATPlan: Loss-based Collision Prediction in End-to-End Autonomous Driving
Mar 10, 2025
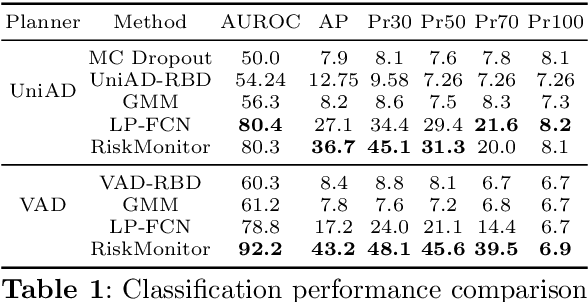


In recent years, there has been increased interest in the design, training, and evaluation of end-to-end autonomous driving (AD) systems. One often overlooked aspect is the uncertainty of planned trajectories predicted by these systems, despite awareness of their own uncertainty being key to achieve safety and robustness. We propose to estimate this uncertainty by adapting loss prediction from the uncertainty quantification literature. To this end, we introduce a novel light-weight module, dubbed CATPlan, that is trained to decode motion and planning embeddings into estimates of the collision loss used to partially supervise end-to-end AD systems. During inference, these estimates are interpreted as collision risk. We evaluate CATPlan on the safety-critical, nerf-based, closed-loop benchmark NeuroNCAP and find that it manages to detect collisions with a $54.8\%$ relative improvement to average precision over a GMM-based baseline in which the predicted trajectory is compared to the forecasted trajectories of other road users. Our findings indicate that the addition of CATPlan can lead to safer end-to-end AD systems and hope that our work will spark increased interest in uncertainty quantification for such systems.
CLICv2: Image Complexity Representation via Content Invariance Contrastive Learning
Mar 09, 2025



Unsupervised image complexity representation often suffers from bias in positive sample selection and sensitivity to image content. We propose CLICv2, a contrastive learning framework that enforces content invariance for complexity representation. Unlike CLIC, which generates positive samples via cropping-introducing positive pairs bias-our shifted patchify method applies randomized directional shifts to image patches before contrastive learning. Patches at corresponding positions serve as positive pairs, ensuring content-invariant learning. Additionally, we propose patch-wise contrastive loss, which enhances local complexity representation while mitigating content interference. In order to further suppress the interference of image content, we introduce Masked Image Modeling as an auxiliary task, but we set its modeling objective as the entropy of masked patches, which recovers the entropy of the overall image by using the information of the unmasked patches, and then obtains the global complexity perception ability. Extensive experiments on IC9600 demonstrate that CLICv2 significantly outperforms existing unsupervised methods in PCC and SRCC, achieving content-invariant complexity representation without introducing positive pairs bias.